Clear Sky Science · fr
Super‑résolution d’images de télédétection à échelle continue inter‑domaines via apprentissage des méta‑poids
Des vues spatiales plus nettes
Les images satellites alimentent tout, de l’aménagement urbain à la réponse aux catastrophes, mais nombre d’entre elles sont plus floues que souhaité en raison des limites du matériel optique et de la transmission de données. Cet article présente une nouvelle manière de transformer des photos satellites floues en images plus nettes à n’importe quel niveau de zoom choisi, en utilisant une stratégie d’apprentissage capable de s’adapter à l’aspect spécifique des images aériennes sans nécessiter une ré‑entraînement pour chaque situation.
Pourquoi des images satellites plus nettes comptent
Des images de télédétection haute résolution sont cruciales pour repérer de petits objets, suivre les changements au sol et cartographier l’usage des terres avec précision. Pourtant, les satellites réels doivent faire des compromis entre résolution, coût, taille des capteurs et bande passante, de sorte que de nombreuses images arrivent à une qualité inférieure à celle souhaitée par les analystes. Les techniques traditionnelles de « super‑résolution » peuvent améliorer la netteté, mais sont généralement entraînées pour un facteur de zoom fixe, comme exactement deux ou quatre fois. Cela oblige les opérateurs à utiliser des modèles distincts pour chaque niveau de zoom, ce qui est inefficace et peu flexible face à la multiplicité des satellites et des tâches.
Au‑delà du zoom universel
Des travaux récents ont développé la super‑résolution « à échelle continue », qui considère une image comme un signal continu et peut générer des sorties nettes pour tout facteur de zoom avec un seul modèle. La plupart de ces méthodes ont été conçues et testées sur des photos du quotidien, pas sur des données satellitaires. Elles décident typiquement comment mélanger l’information des pixels voisins selon des règles géométriques fixes — essentiellement en pondérant les voisins par la distance. Cela fonctionne assez bien pour des scènes naturelles comme des visages ou des paysages, mais les images satellites présentent des bâtiments denses, des textures répétitives et des bords abrupts qui ne suivent pas les mêmes motifs. Quand des modèles entraînés sur des photos naturelles sont appliqués à des vues satellites, leurs hypothèses s’effondrent et des détails tels que toitures, routes et véhicules ne sont pas restitués fidèlement.
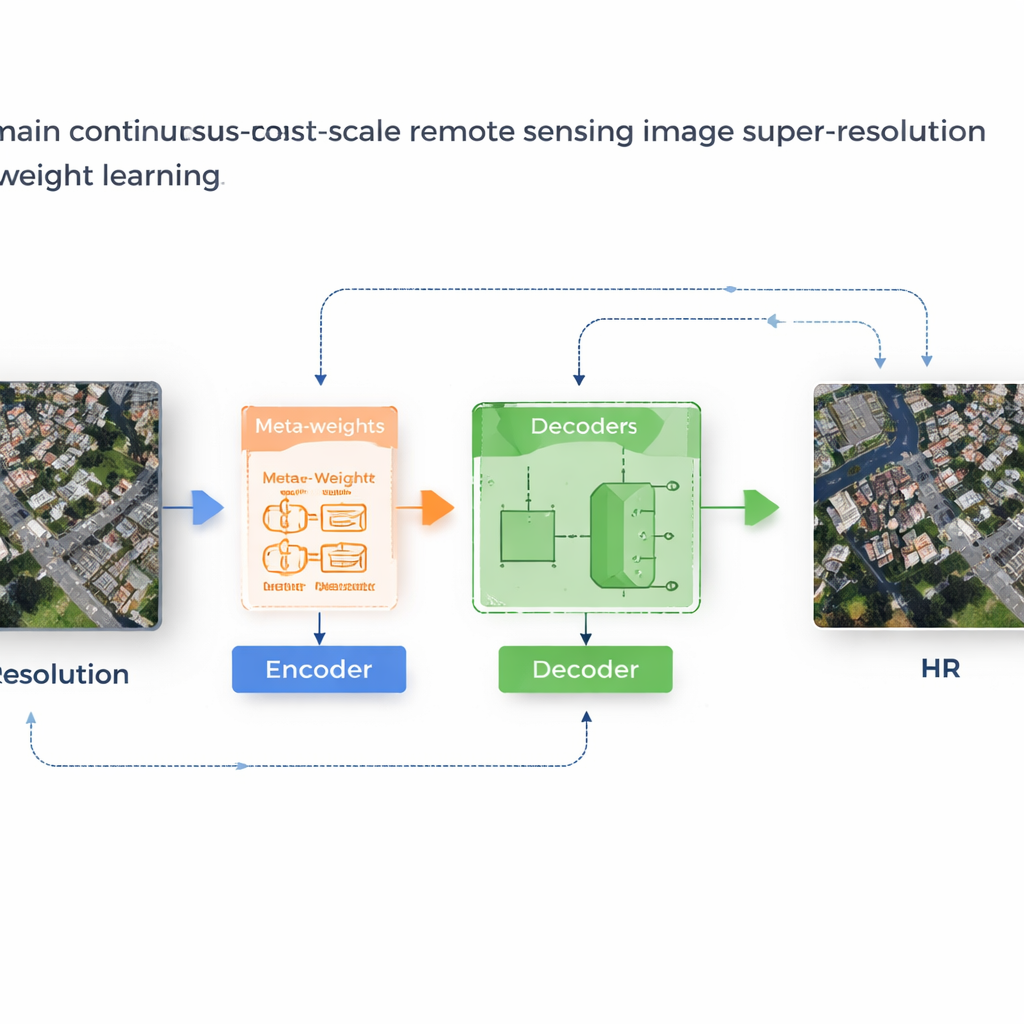
Un système d’apprentissage qui adapte ses propres règles
Les auteurs proposent un cadre appelé MLIN (Meta‑Learning‑based Implicit Neural Network) pour résoudre ce problème inter‑domaines. Plutôt que de concevoir à la main la façon dont les caractéristiques des pixels voisins doivent être combinées, MLIN apprend ces règles de combinaison à partir des données. Il conserve un encodeur d’images puissant, initialement entraîné sur des photos naturelles, entièrement gelé, afin de continuer à extraire des motifs visuels riches sans être déformé par les plus petits jeux de données satellites. Par dessus cela, MLIN ajoute un nouveau « décodeur implicite » équipé d’un module de méta‑apprentissage. Pour chaque point de l’image haute résolution que le modèle veut reconstruire, ce module examine les caractéristiques environnantes et leurs positions précises, puis prédit un ensemble de poids souples qui indiquent au décodeur l’importance à accorder à chaque voisin. En d’autres termes, le système n’assume plus que seule la distance importe ; il laisse le contenu local — textures de toits, champs ou eau — guider la reconstruction.
Des blocs flous à des structures nettes
Techniquement, la méthode fonctionne en échantillonnant un petit voisinage 2×2 de caractéristiques cachées autour de chaque position cible dans l’image de sortie. Un méta‑réseau combine ensuite des informations sur ces caractéristiques, leurs coordonnées relatives et le facteur de zoom demandé pour choisir des poids qui sommeillent à un. Le décodeur utilise ces poids pour fondre les prédictions de chaque voisin, produisant une valeur de couleur finale à cet endroit. Parce que cette pondération est apprise, MLIN peut traiter des régions complexes — comme des quartiers résidentiels denses, des ports avec navires ou des aéroports avec pistes — très différemment des zones lisses comme déserts ou océans. Des expériences sur deux jeux de données satellites largement utilisés (WHU‑RS19 et UCMerced) montrent que MLIN offre systématiquement de meilleurs scores numériques et des détails visiblement plus nets que plusieurs méthodes de zoom continu de pointe, tant aux facteurs de zoom courants qu’à des agrandissements extrêmes allant jusqu’à dix fois.
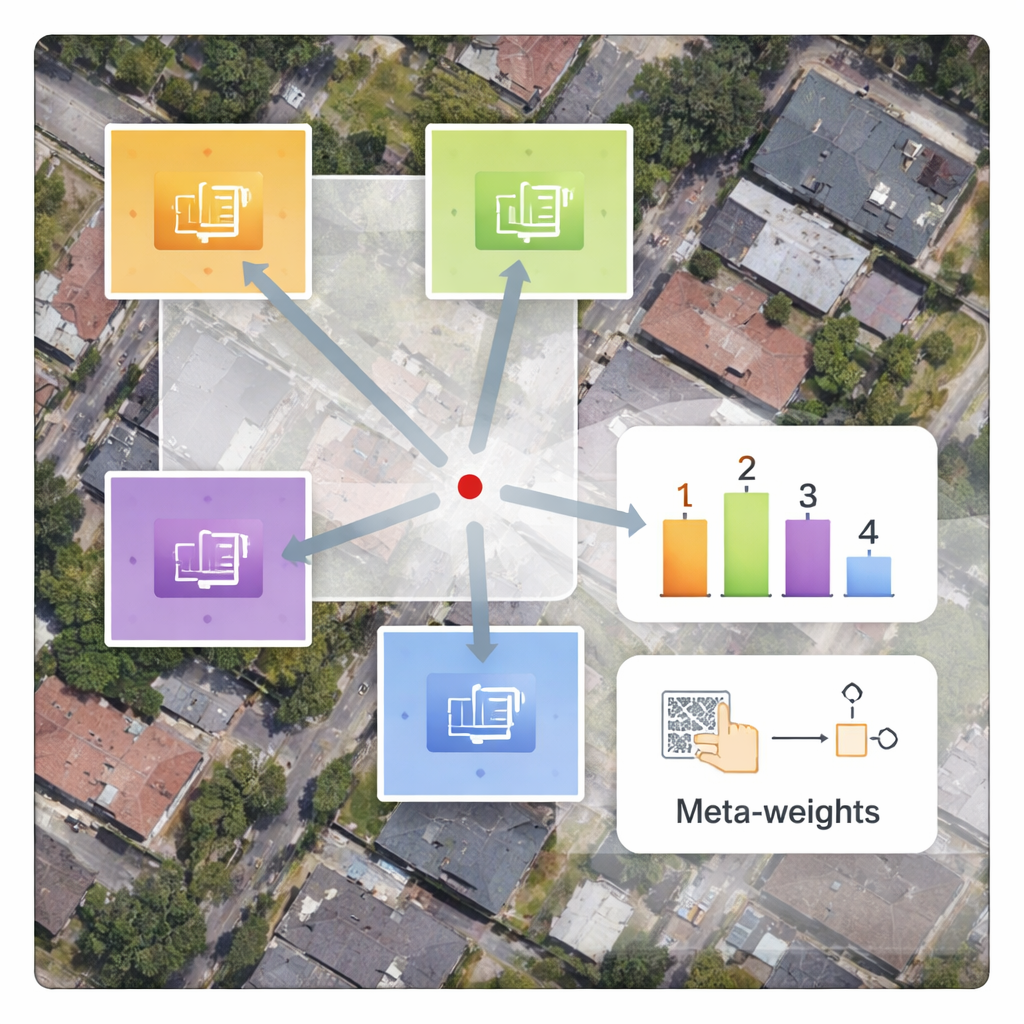
Un entraînement plus rapide sans délai additionnel
Un avantage pratique de cette conception est que seul le nouveau décodeur et le réseau de méta‑poids doivent être entraînés sur des images satellites, tandis que le grand encodeur reste fixe. Cela réduit considérablement le temps d’entraînement comparé aux méthodes qui réentraînent tous les paramètres depuis zéro. Même si le méta‑réseau introduit un calcul supplémentaire, les processeurs graphiques modernes gèrent ces opérations efficacement, de sorte que le temps de traitement d’une image reste presque identique à celui des approches existantes. Des études d’ablation — tests contrôlés où des parties du système sont supprimées ou simplifiées — confirment que la pondération dépendante du contenu est l’ingrédient clé qui améliore à la fois la netteté des bords et la continuité des textures.
Des yeux plus clairs sur la Terre
En termes simples, ce travail montre comment réutiliser des modèles d’images puissants entraînés sur des photos du quotidien et les adapter intelligemment au monde très différent de l’imagerie satellite. En laissant le système apprendre à équilibrer l’information provenant des pixels voisins selon ce qui figure réellement dans la scène, MLIN produit des images satellites plus claires et plus fiables à n’importe quel niveau de zoom à partir d’un seul modèle. Cela se traduit par de meilleurs outils pour les scientifiques, urbanistes et équipes d’intervention d’urgence qui dépendent de vues détaillées de notre planète, tout en maintenant des besoins de calcul et de stockage raisonnables.
Citation: Zhang, Q., Ma, S., Tang, Y. et al. Cross-domain continuous-scale remote sensing image super-resolution via meta-weight learning. Sci Rep 16, 6073 (2026). https://doi.org/10.1038/s41598-026-36632-w
Mots-clés: super‑résolution satellite, imagerie de télédétection, méta‑apprentissage, zoom à échelle arbitraire, amélioration d’image