Clear Sky Science · fr
Évaluation fine des grands modèles de langage en médecine à l’aide d’un modèle diagnostique cognitif non paramétrique
Pourquoi cela compte pour les prochaines visites chez le médecin
Les systèmes d’intelligence artificielle qui parlent et écrivent, appelés grands modèles de langage, passent rapidement des laboratoires de recherche aux hôpitaux. Ils peuvent déjà aider les médecins à lire des dossiers complexes, suggérer des traitements et répondre à des questions médicales. Mais la plupart des évaluations de ces systèmes donnent un seul score global, à la manière d’une note finale, ce qui peut masquer des angles morts dangereux. Cette étude propose une nouvelle façon d’analyser ces scores et de révéler exactement quelles zones de la médecine ces modèles comprennent réellement — et où ils peuvent encore mettre les patients en danger.
Au-delà d’un seul score de test
Aujourd’hui, la plupart des IA médicales sont jugées sur le nombre de questions auxquelles elles répondent correctement lors d’examens calqués sur les concours d’agrément des médecins. Cette approche est simple mais grossière. Un modèle peut obtenir une note globale élevée tout en étant faible dans un domaine critique, comme l’analyse du rythme cardiaque ou les maladies du foie. Dans les cliniques réelles, de telles lacunes peuvent avoir des conséquences vitales. Les auteurs soutiennent qu’un usage sûr de l’IA en médecine exige une évaluation plus profonde et plus fine — capable de dresser un profil détaillé de compétences plutôt que d’attribuer une seule note potentiellement trompeuse.

Une façon plus intelligente d’évaluer les connaissances médicales
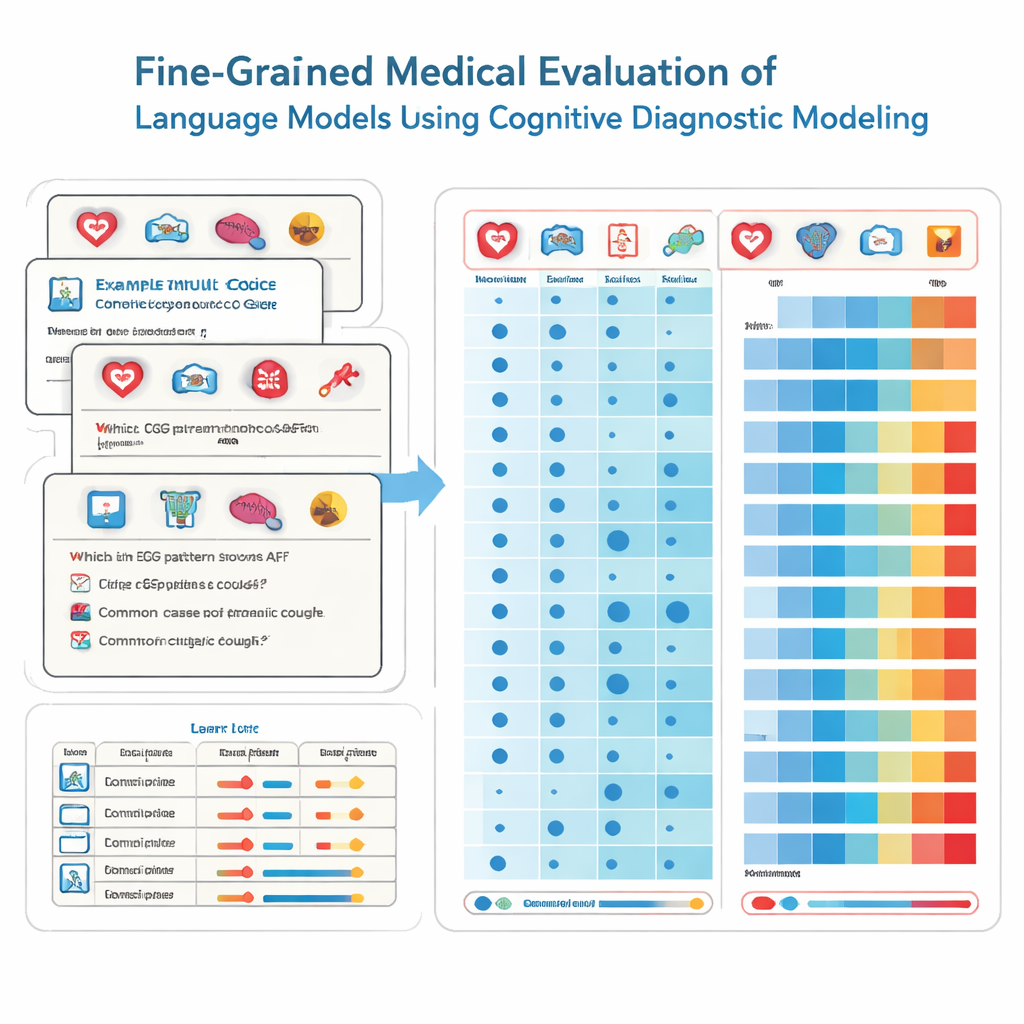
Pour y parvenir, les chercheurs empruntent des outils à la psychologie de l’éducation appelés évaluations diagnostiques cognitives. Plutôt que de considérer chaque question d’examen comme mesurant la même capacité vague, cette méthode décompose les connaissances médicales en éléments spécifiques, comme la cardiologie, la radiologie ou les soins d’urgence. Chaque question à choix multiple est étiquetée avec le mélange précis de compétences qu’elle requiert. À l’aide d’une technique statistique non paramétrique, l’équipe compare la manière dont un modèle répond à des milliers de ces questions à des schémas de réponse idéaux. À partir de là, elle infère si le modèle a « maîtrisé » chaque compétence sous-jacente, à la manière d’un bulletin détaillé montrant forces et faiblesses selon les matières.
Mettre 41 modèles d’IA à l’épreuve d’un examen médical
L’équipe a testé 41 modèles de langage largement utilisés, incluant des systèmes commerciaux et des modèles open source, sur 2 809 questions soigneusement vérifiées issues d’une banque d’examens médicaux nationale chinoise. Ces questions couvrent 22 sous-domaines médicaux et sont conçues pour des étudiants sur le point de passer l’examen d’aptitude au diplôme de médecin. Chaque question a une réponse correcte et est annotée par des experts pour indiquer les spécialités concernées. Grâce à leur méthode diagnostique, les chercheurs ont estimé, pour chaque modèle, combien de ces 22 attributs médicaux il maîtrisait effectivement, et pas seulement combien de questions il avait répondu correctement par hasard.
Bonne culture générale, mais angles morts marqués
Les résultats sont à la fois impressionnants et préoccupants. Les modèles les plus performants, comme plusieurs systèmes commerciaux majeurs, ont répondu correctement à la plupart des questions et ont montré la maîtrise de 20 des 22 domaines médicaux. Globalement, la performance était excellente dans de nombreuses spécialités courantes, avec une maîtrise complète dans 15 domaines incluant la cardiologie, la dermatologie et l’endocrinologie. Pourtant, l’analyse fine a mis au jour des lacunes criantes dans d’autres secteurs. La radiologie accusait un retard avec des taux de maîtrise beaucoup plus faibles, et deux sous-domaines — ECG & hypertension & lipides et les troubles hépatiques — n’étaient maîtrisés par aucun modèle. Fait important, certains modèles de plus petite taille partageaient les mêmes compétences maîtrisées que des modèles beaucoup plus grands, montrant que la taille seule ne garantit pas des connaissances médicales larges et fiables.
Choisir le bon outil pour la bonne tâche
Ces profils détaillés comptent parce que des modèles avec des scores globaux très similaires peuvent présenter des schémas de forces et de faiblesses très différents. Un système peut être solide en neurologie mais faible en pharmacologie, tandis qu’un autre présente le schéma inverse. Pour les responsables hospitaliers, cela signifie qu’ils ne peuvent pas choisir en toute sécurité un assistant IA uniquement sur la base de son score d’examen ou du nombre de paramètres. Ils ont besoin de résultats diagnostiques comme ceux de cette étude pour associer chaque modèle à des tâches cliniques spécifiques et concevoir des flux de travail où des spécialistes humains vérifient les productions de l’IA dans les domaines à risque où le modèle est connu pour être faible.
Ce que cela signifie pour les patients et les cliniciens
En termes simples, l’étude conclut qu’une « bonne note » aux tests médicaux ne garantit pas qu’un système d’IA soit sûr à utiliser dans tous les domaines de la médecine. La nouvelle approche fonctionne davantage comme un bilan de santé approfondi pour l’IA elle‑même, révélant quels « organes » — ici, quelles spécialités médicales — sont en bonne santé et lesquels requièrent de l’attention. En découvrant des lacunes cachées dans des domaines critiques tels que l’interprétation des ECG et les maladies du foie, la méthode fournit aux hôpitaux, aux régulateurs et aux développeurs une feuille de route pratique : utiliser les modèles uniquement là où leur robustesse a été démontrée, garder les humains au cœur du processus là où des faiblesses subsistent, et concentrer la formation future sur les angles morts les plus risqués. Ce type d’évaluation fine, selon les auteurs, n’est pas seulement utile — il est indispensable avant de confier des soins aux patients à l’IA.
Citation: Zheng, T., Liu, J., Feng, S. et al. Fine-grained evaluation of large language models in medicine using non-parametric cognitive diagnostic modeling. Sci Rep 16, 6460 (2026). https://doi.org/10.1038/s41598-026-36627-7
Mots-clés: IA médicale, grands modèles de langage, sûreté clinique, évaluation de modèles, tests diagnostiques