Clear Sky Science · fr
Optimisation multitâche et stabilité de convergence avec apprentissage hiérarchique des caractéristiques pour une optimisation auto‑guidée
Une IA plus intelligente capable de jongler avec plusieurs tâches à la fois
Les applications modernes reposent de plus en plus sur des intelligences artificielles devant accomplir plusieurs choses simultanément — par exemple comprendre des images et du texte ensemble, soutenir des décisions médicales ou aider les véhicules à percevoir la route. Mais quand un même modèle d'IA apprend trop de compétences à la fois, son entraînement peut devenir instable et les compétences peuvent se perturber mutuellement. Cet article présente un nouveau cadre d'apprentissage profond, appelé Unified Multitask and Multiview Deep Architecture (UMDA), conçu pour permettre à un seul modèle d'apprendre à partir de nombreux types de données et de résoudre de multiples tâches sans se tromper ni perdre sa stabilité.
Pourquoi les IA multitâches d'aujourd'hui peinent souvent
La plupart des systèmes actuels qui apprennent plusieurs tâches (apprentissage multitâche) ou combinent plusieurs types de données, comme images et texte (apprentissage multivue), souffrent de trois problèmes majeurs. D'abord, les tâches peuvent se concurrencer lors de l'entraînement : améliorer une tâche peut nuire silencieusement à une autre, un phénomène connu sous le nom de transfert négatif. Ensuite, l'empilement ou la simple moyenne d'informations issues de sources diverses fait souvent perdre des relations subtiles mais importantes entre elles. Enfin, le processus d'entraînement lui‑même peut devenir instable, avec de fortes oscillations dans la direction des mises à jour des paramètres du modèle. Ces enjeux sont particulièrement critiques dans des contextes réels comme le diagnostic médical ou l'inspection industrielle, où les données sont complexes et les décisions doivent être fiables.
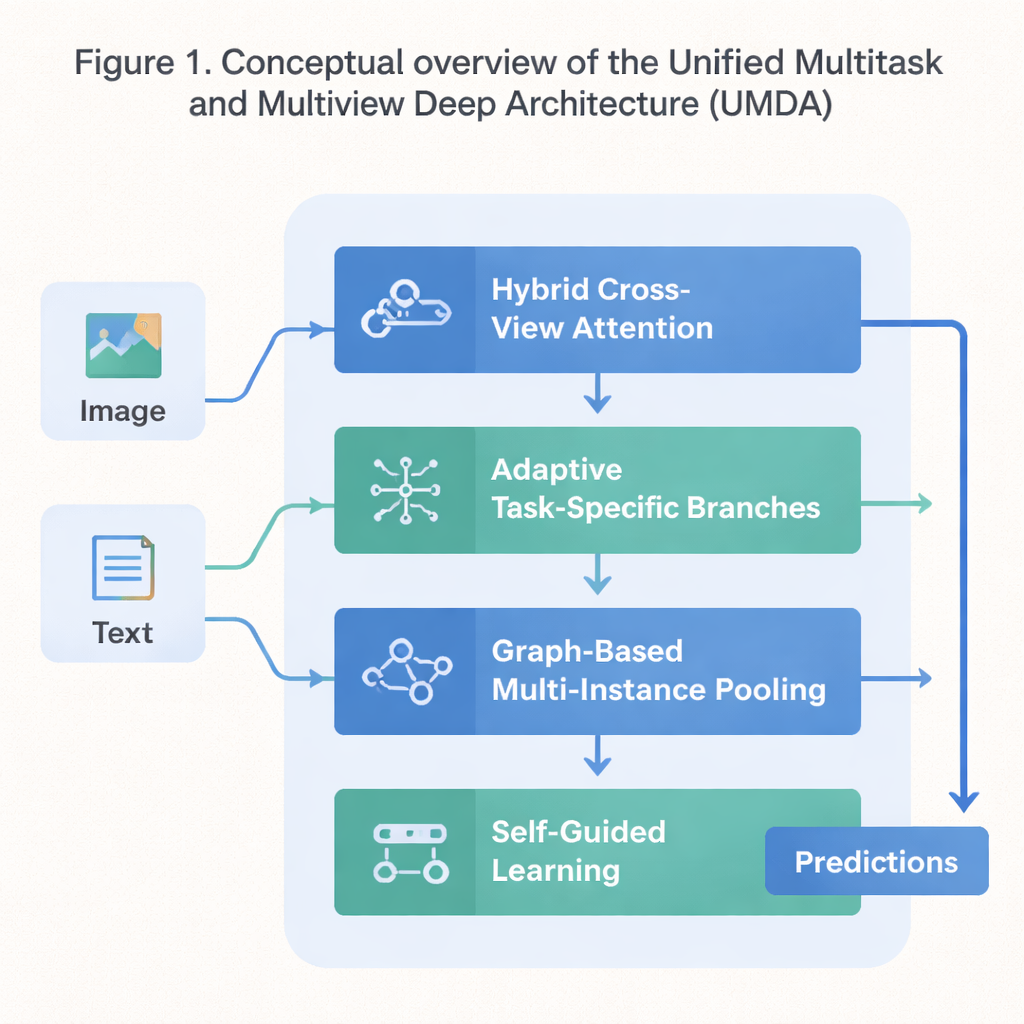
Un plan en quatre volets pour un apprentissage coopératif
UMDA s'attaque à ces faiblesses en divisant le processus d'apprentissage en quatre parties étroitement connectées qui partagent l'information de manière contrôlée. La première partie, appelée Hybrid Cross‑View Attention, examine différentes vues d'une même donnée — par exemple texte et images décrivant un film — et apprend quelle vue doit influencer une autre à chaque étape. Elle utilise des outils mathématiques qui encouragent le modèle à éviter de trop dépendre d'une seule vue, à préserver la distinctivité de chaque vue et, en même temps, à les maintenir globalement cohérentes. En termes simples, elle apprend au modèle à écouter tous ses « sens » sans laisser l'un d'eux écraser les autres.
Garder les tâches distinctes tout en restant coopératives
La deuxième partie, Adaptive Task‑Specific Branching, sépare le savoir générique partagé par de nombreuses tâches du savoir spécifique requis par chaque tâche. Plutôt que d'imposer à toutes les tâches d'utiliser exactement les mêmes caractéristiques, UMDA construit des « branches » séparées pour chaque tâche qui peuvent néanmoins communiquer entre elles via des connexions finement pondérées. Des termes de pénalisation supplémentaires dans l'objectif d'entraînement poussent ces branches à se spécialiser suffisamment, sans pour autant se diverger au point de cesser de coopérer. Cet équilibre aide à réduire les interférences nuisibles entre tâches tout en leur permettant de bénéficier des apprentissages des autres.
Voir la structure au sein d'ensembles d'exemples
De nombreux jeux de données réels se présentent comme des collections d'éléments reliés — par exemple plusieurs patchs d'image issus d'une même lame de microscope ou de nombreuses images consécutives d'une vidéo. La troisième partie d'UMDA, dite Graph‑Based Multi‑Instance Pooling, modélise explicitement les relations entre ces éléments en les traitant comme des nœuds d'un réseau. Elle connecte les éléments similaires, laisse l'information circuler le long de ces connexions, puis résume l'ensemble en une représentation compacte unique. Une régularisation supplémentaire encourage les éléments proches à s'accorder entre eux tout en conservant assez de diversité, permettant au modèle de capturer des motifs structurels que la moyenne simple manquerait.
Auto‑réglage de l'entraînement pour un progrès régulier
La dernière partie, Self‑Guided Learning, se concentre sur la manière dont le modèle est entraîné plutôt que sur sa structure interne. Elle mesure en continu l'intensité et la similarité des signaux d'entraînement de chaque tâche puis ajuste automatiquement la vitesse d'apprentissage pour chacune. Elle lisse et re‑pondère aussi les gradients — les signaux qui indiquent au modèle comment changer — afin que les tâches aux objectifs proches se renforcent mutuellement et que celles qui tirent dans des directions très différentes ne déstabilisent pas l'entraînement. Testé sur un jeu de données standard mélangeant résumés et affiches de films, UMDA a atteint une précision moyenne supérieure à celle d'une douzaine de concurrents de pointe, a maintenu des relations entre vues plus cohérentes et a réduit d'autre part une mesure clé d'instabilité d'entraînement de plus de moitié.
Ce que cela signifie pour les systèmes d'IA réels
Pour le grand public, le message principal est que UMDA propose une manière de construire des modèles d'IA uniques capables de gérer plusieurs types de données et d'objectifs de façon plus fiable. En apprenant au modèle quand partager l'information et quand la garder séparée, et en lui permettant d'ajuster automatiquement sa façon d'apprendre, le cadre fournit de meilleures prédictions, des représentations internes plus cohérentes et un entraînement plus stable. Cela en fait un composant prometteur pour des systèmes futurs en médecine, conduite autonome et autres applications complexes où l'IA doit interpréter simultanément de nombreux signaux sans perdre son équilibre.
Citation: Mahmood, K., Althobaiti, M.M., Hassan, M.U. et al. Multitask optimization and convergence stability with hierarchical feature learning for self guided optimization. Sci Rep 16, 6414 (2026). https://doi.org/10.1038/s41598-026-36622-y
Mots-clés: apprentissage multitâche, IA multimodale, stabilité de l'apprentissage profond, réseaux d'attention, réseaux de neurones graphiques