Clear Sky Science · fr
Modèle hybride d’apprentissage profond pour la prédiction de la qualité de l’air et son impact sur la santé
Pourquoi un air plus propre et des prévisions plus intelligentes comptent
La pollution de l’air n’est pas seulement une skyline brumeuse : elle aggrave silencieusement les problèmes respiratoires, met le cœur à rude épreuve et raccourcit l’espérance de vie. Les autorités municipales s’appuient aujourd’hui sur l’indice de qualité de l’air (AQI) pour prévenir la population lorsqu’il est dangereux de rester dehors, mais ces alertes reposent souvent sur les données d’hier ou sur des prévisions simplistes qui ratent les pics soudains. Cet article explore une nouvelle méthode de prédiction de la qualité de l’air à court terme, combinant des modèles informatiques avancés et des entrées soigneusement conçues, dans le but de fournir aux citoyens et aux systèmes de santé des avertissements plus précoces et plus fiables.
De l’air pollué à un seul indicateur de santé
L’étude se concentre sur Gurugram, une ville indienne en forte croissance où la circulation, l’industrie et le bâtiment contribuent à la mauvaise qualité de l’air. Six polluants clés — particules fines (PM2,5 et PM10), ozone au sol, dioxyde d’azote, dioxyde de soufre et monoxyde de carbone — ont été mesurés horairement pendant quatre mois via le service OpenWeather. Ces mesures ont été converties en une valeur AQI unique en comparant chaque polluant aux limites nationales de sécurité puis en retenant le polluant le plus défavorable comme score global de la ville. Cette valeur AQI est ce que les applications météo affichent sous des catégories comme « Bon », « Modéré », « Mauvais » ou « Très mauvais », chacune correspondant à différents niveaux de préoccupation sanitaire.
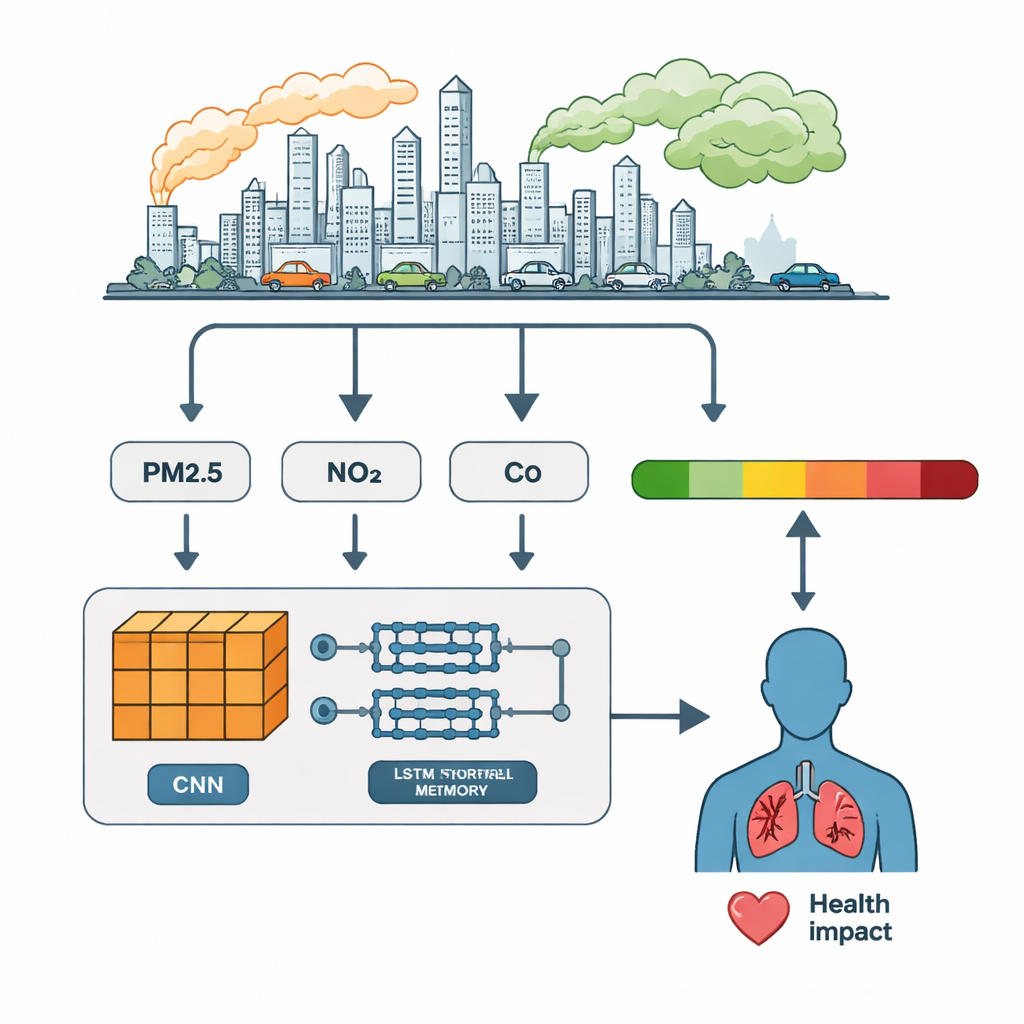
Apprendre aux ordinateurs à lire les rythmes de la pollution
Plutôt que d’alimenter directement les modèles avec des relevés bruts, les auteurs ont d’abord conçu des caractéristiques supplémentaires qui reflètent le comportement réel de l’air. Ils ont ajouté des valeurs décalées pour montrer l’état de la pollution quelques heures plus tôt, des moyennes mobiles pour lisser les pics passagers, et des ratios comme PM2,5/PM10 pour distinguer poussières fines et grosses. Ils ont également encodé des motifs calendaires — heure de la journée, jour de la semaine, mois — en utilisant des signaux cycliques afin de capter les activités humaines récurrentes, comme le trafic en semaine ou le ralentissement le week‑end. Ces signaux conçus par des experts visaient à aider les modèles à percevoir des tendances et des interactions subtiles que les nombres bruts peuvent masquer.
Mélanger deux types d’apprentissage profond
Les chercheurs ont comparé trois approches d’apprentissage profond. Un réseau de neurones convolutionnel unidimensionnel (CNN) est excellent pour repérer des motifs locaux — courtes rafales ou formes dans les données. Un réseau à mémoire à long terme (LSTM) est performant pour mémoriser l’évolution des valeurs dans le temps. Le modèle hybride CNN–LSTM enchaîne ces forces : d’abord, des couches CNN compressent et mettent en évidence les caractéristiques importantes des séries de polluants ; ensuite, des couches LSTM suivent l’évolution de ces caractéristiques heure par heure. Les trois modèles ont été entraînés sur la majeure partie des données et testés sur le reste, en utilisant des métriques standard comme la précision, le rappel et le score F1 pour évaluer la capacité à classer chaque heure dans la bonne catégorie AQI.
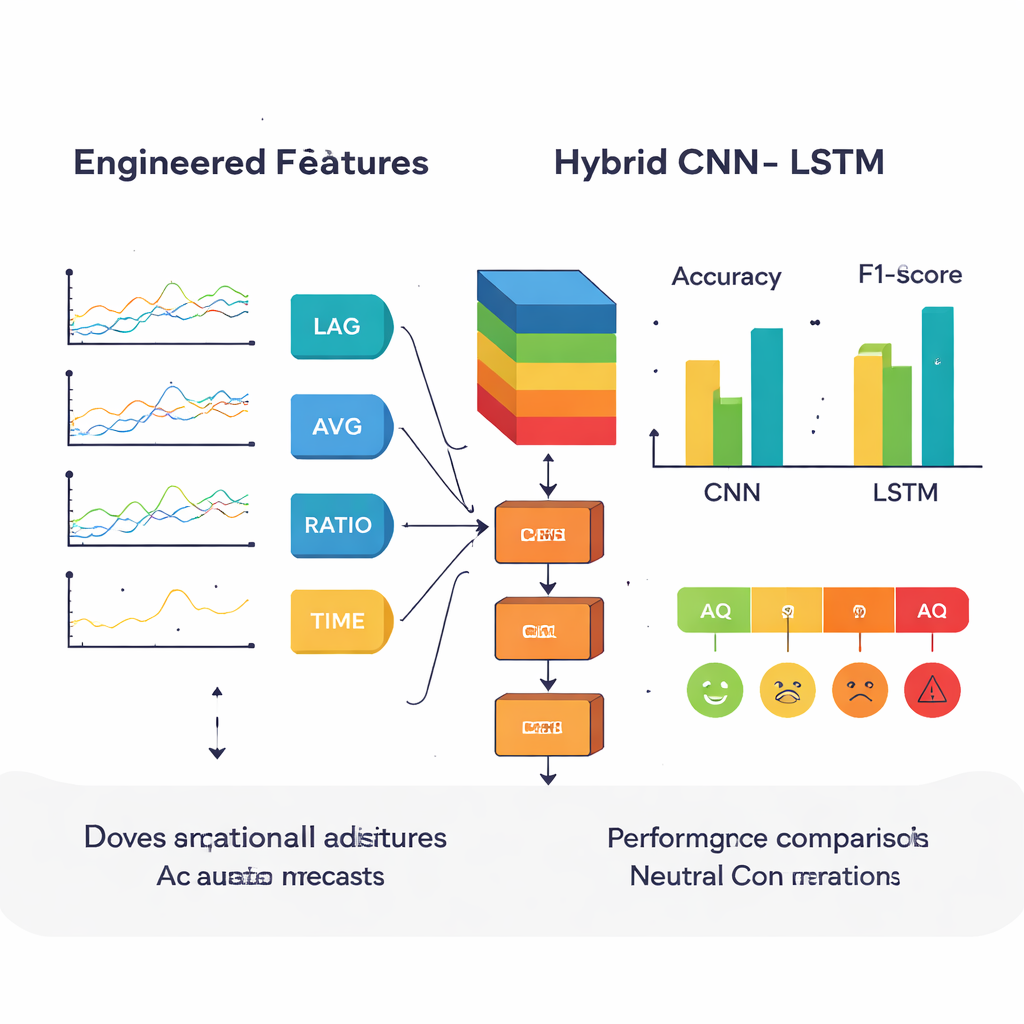
Des prévisions plus nettes et leurs implications pour la santé
Sur des expériences répétées, le modèle hybride a systématiquement offert le meilleur compromis entre exactitude et fiabilité. Avec les caractéristiques conçues, il a atteint un score F1 d’environ 91 %, légèrement devant le LSTM seul et nettement meilleur que le CNN. Il a aussi été particulièrement performant pour distinguer les situations les plus polluées, confondant rarement l’air « Très mauvais » avec des catégories plus sûres. Un simple module supplémentaire a traduit chaque niveau AQI prédit en un score de risque sanitaire approximatif, indiquant par exemple que les conditions « Très mauvaises » et « Sévères » correspondent à une probabilité nettement plus élevée de problèmes respiratoires et cardiaques. Les auteurs soulignent que ces scores de risque sont des repères et non des diagnostics médicaux, mais ils montrent comment des prévisions de qualité de l’air peuvent être converties en signaux de santé plus intuitifs.
Ce que cela signifie pour les villes et les citoyens
L’étude conclut que la combinaison d’entrées soigneusement ingénierées et d’une architecture hybride CNN–LSTM peut rendre les prévisions AQI à court terme à la fois plus précises et plus stables que l’utilisation d’un modèle unique. Bien que le travail soit limité à une ville et à quelques mois de données, il ouvre la voie à des outils pratiques susceptibles d’éclairer la fermeture d’écoles, les plannings de travail en extérieur, la préparation des hôpitaux et des choix individuels comme les moments propices pour faire de l’exercice dehors ou porter un masque. Avec des séries plus longues et des tests plus étendus, des systèmes similaires pourraient devenir l’épine dorsale d’une surveillance de la qualité de l’air pilotée par les données, donnant aux populations des avertissements plus précoces sur l’air malsain et aidant les décideurs à agir avant les pics de pollution.
Citation: Madan, T., Sagar, S., Singh, Y. et al. Hybrid deep learning model for air quality prediction and its impact on healthcare. Sci Rep 16, 6036 (2026). https://doi.org/10.1038/s41598-026-36564-5
Mots-clés: indice de qualité de l’air, apprentissage profond, CNN-LSTM, risque pour la santé, prévision de la pollution