Clear Sky Science · fr
Un modèle hybride ResNet50-vision transformer avec un mécanisme d’attention pour la classification d’images aériennes
Pourquoi des « yeux » plus intelligents dans le ciel comptent
Les photos aériennes prises par drones et satellites guident désormais les interventions en cas de catastrophe, l’urbanisme, l’agriculture et même la gestion du trafic. Mais apprendre aux ordinateurs à comprendre ces vues complexes et encombrées vues d’en haut reste difficile. Cette étude présente deux nouveaux modèles d’intelligence artificielle qui combinent différentes façons de « voir » les images pour reconnaître dix types d’objets dans des photos de drones — comme les bâtiments, voitures, arbres et routes — avec une meilleure précision que les méthodes précédentes. Leur approche pourrait rendre la surveillance automatisée depuis les airs plus rapide, plus fiable et plus facile à déployer dans des contextes réels.
Les défis de regarder le monde d’en haut
Les images aériennes diffèrent des photos de tous les jours que nous prenons avec nos téléphones. Les objets y sont plus petits, peuvent apparaître sous des angles insolites et sont souvent très proches les uns des autres. Une voiture partiellement cachée par un arbre, un sentier étroit ou des tas de débris après un glissement de terrain peuvent être difficiles à repérer même pour des humains. Pourtant, gouvernements, équipes d’urgence et agences environnementales s’appuient de plus en plus sur les vues par drone et satellite pour suivre les inondations, les feux de forêt, l’expansion urbaine et les dégâts aux infrastructures. Avec des milliers de satellites en orbite et un marché de l’imagerie aérienne en plein essor, le volume de données croît trop vite pour être inspecté manuellement, ce qui renforce le besoin de classifications automatisées plus précises et plus efficaces.
Mélanger deux manières dont les machines apprennent à voir
La plupart des systèmes de reconnaissance d’images performants aujourd’hui reposent sur l’apprentissage profond. Une famille, les réseaux convolutifs, excelle à repérer des motifs locaux comme les bords, textures et petites formes. Une autre famille, plus récente, appelée vision transformer, traite une image comme une séquence de patches et est particulièrement bonne pour capturer les relations à longue portée — par exemple comment une route, un groupe de toits et un champ voisin s’articulent dans une scène. Ce travail combine les deux : un modèle convolutionnel bien connu, ResNet-50, et un vision transformer. Chacun traite la même image aérienne et extrait son propre ensemble de caractéristiques numériques — des résumés compacts de ce que le réseau a appris sur la scène. Ces deux flux d’information sont ensuite réunis et transmis à un module d’« attention » qui apprend quelles caractéristiques sont les plus importantes pour décider entre les dix classes cibles.
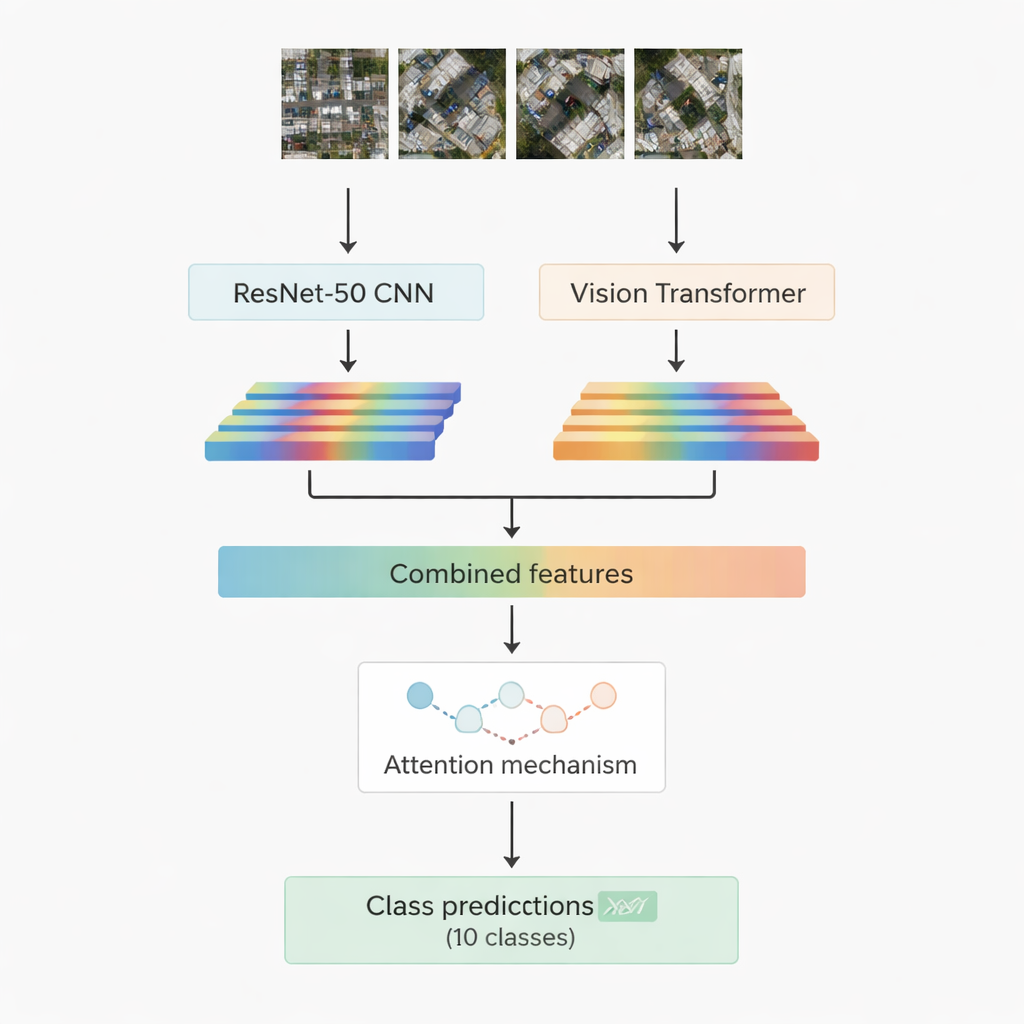
Deux stratégies d’attention pour se concentrer sur l’essentiel
Les chercheurs conçoivent et testent deux versions de leur système hybride. Dans la première, ils joignent simplement les caractéristiques de ResNet-50 et du transformer et les injectent dans un module d’attention multi-têtes. Ce mécanisme peut être vu comme de nombreux petits projecteurs qui examinent chacun les caractéristiques selon un angle légèrement différent, puis combinent leurs conclusions. Dans la seconde version, ils utilisent de la cross-attention : les caractéristiques du réseau convolutionnel jouent le rôle de requête qui interroge les caractéristiques du transformer pour indiquer où regarder, permettant à un flux de guider l’autre. Dans les deux cas, la sortie de l’attention est traitée par des couches standard qui assignent finalement la vignette d’image à l’une des dix classes, incluant bâtiments, voitures, débris, sentiers piétonniers, routes métalliques, champs ouverts, ombres, tanks, arbres et toits.
Tests sur des images de drone du monde réel
Pour évaluer la performance de leurs modèles, les auteurs utilisent un jeu de données public de l’État indien du Sikkim, collecté par un drone volant entre 60 et 120 mètres d’altitude. Les données couvrent rivières, forêts, collines et zones bâties, découpées en petites vignettes de sorte que chaque image appartient à l’une des dix catégories. Le jeu de données est équilibré, avec un nombre égal d’images d’entraînement et de test par classe, constituant un banc d’essai équitable. Les chercheurs entraînent les deux modèles hybrides dans des conditions identiques puis comparent leurs performances à l’aide de mesures couramment utilisées : exactitude, précision, rappel, score F1, matrices de confusion et courbes ROC. Ils comparent également leurs résultats à plusieurs réseaux bien connus et à des méthodes récentes basées sur les transformers issues de la littérature.

Une classification plus nette et un potentiel concret
Les deux modèles hybrides surpassent les systèmes antérieurs sur ce jeu de données, atteignant des précisions globales de 95,52 % et 95,80 %, la version à attention multi-têtes étant légèrement en tête. Leurs performances restent solides et stables pour les dix types d’objets, et des analyses détaillées montrent que même les classes les plus faibles sont reconnues à des taux élevés. Cela suggère que le mélange de réseaux convolutionnels, de vision transformers et de mécanismes d’attention est une recette puissante pour comprendre des scènes aériennes complexes. Pour un lecteur non spécialiste, la conclusion est que les ordinateurs s’améliorent nettement pour répondre à des questions comme « Où sont les routes ? » ou « Quelles vignettes montrent des débris ou des bâtiments ? » dans d’immenses collections d’images de drones. À mesure que ces modèles seront affinés et étendus à de nouveaux jeux de données, ils pourraient soutenir des réponses aux catastrophes plus intelligentes, la surveillance environnementale et des services de villes intelligentes reposant sur une interprétation rapide et fiable des images prises d’en haut.
Citation: Aboghanem, A., Abd Elfattah, M., M. Amer, H. et al. A hybrid ResNet50-vision transformer model with an attention mechanism for aerial image classification. Sci Rep 16, 5940 (2026). https://doi.org/10.1038/s41598-026-36492-4
Mots-clés: classification d’images aériennes, imagerie par drone, apprentissage profond, vision transformer, télédétection