Clear Sky Science · fr
Analyse de performance d’un réseau dépendant à long terme en cascade mélangé basé sur l’attention optimisée pour l’apprentissage adaptatif des professionnels IT
Formation en ligne plus intelligente pour les professionnels tech en activité
Pour de nombreux professionnels des technologies de l’information (IT), les cours en ligne sont désormais le principal moyen de maintenir leurs compétences à jour. Mais la plupart des plateformes de formation évaluent encore les personnes avec des outils approximatifs comme les totaux de quiz ou les badges de complétion. Cette étude présente un moyen plus sophistiqué d’analyser les « empreintes » numériques laissées par les apprenants et de les convertir en informations précises et en temps réel sur la véritable progression d’apprentissage de chaque individu.
Pourquoi les cours en ligne « taille unique » montrent leurs limites
L’e‑learning conventionnel traite la plupart des apprenants de la même façon : tout le monde voit les mêmes modules, passe les mêmes quiz et est jugé avec les mêmes tests fixes. Cette approche ignore la grande diversité des trajectoires professionnelles, surtout dans des domaines en rapide évolution comme la cybersécurité ou l’informatique en nuage. Des recherches antérieures ont tenté de corriger cela par l’apprentissage machine — en combinant scores de quiz, temps passé et données de clics pour prédire la réussite — mais de nombreux modèles peinaient avec des données bruitées ou incomplètes, ne pouvaient pas monter en charge pour des plateformes réalistes, ou ne parvenaient pas à suivre la manière dont l’apprentissage évolue sur des semaines et des mois. Le résultat était souvent des retours tardifs et grossiers, qui ne guidaient pas facilement un contenu personnalisé ou une intervention opportune.
Transformer les journaux bruts des cours en données propres et équitables
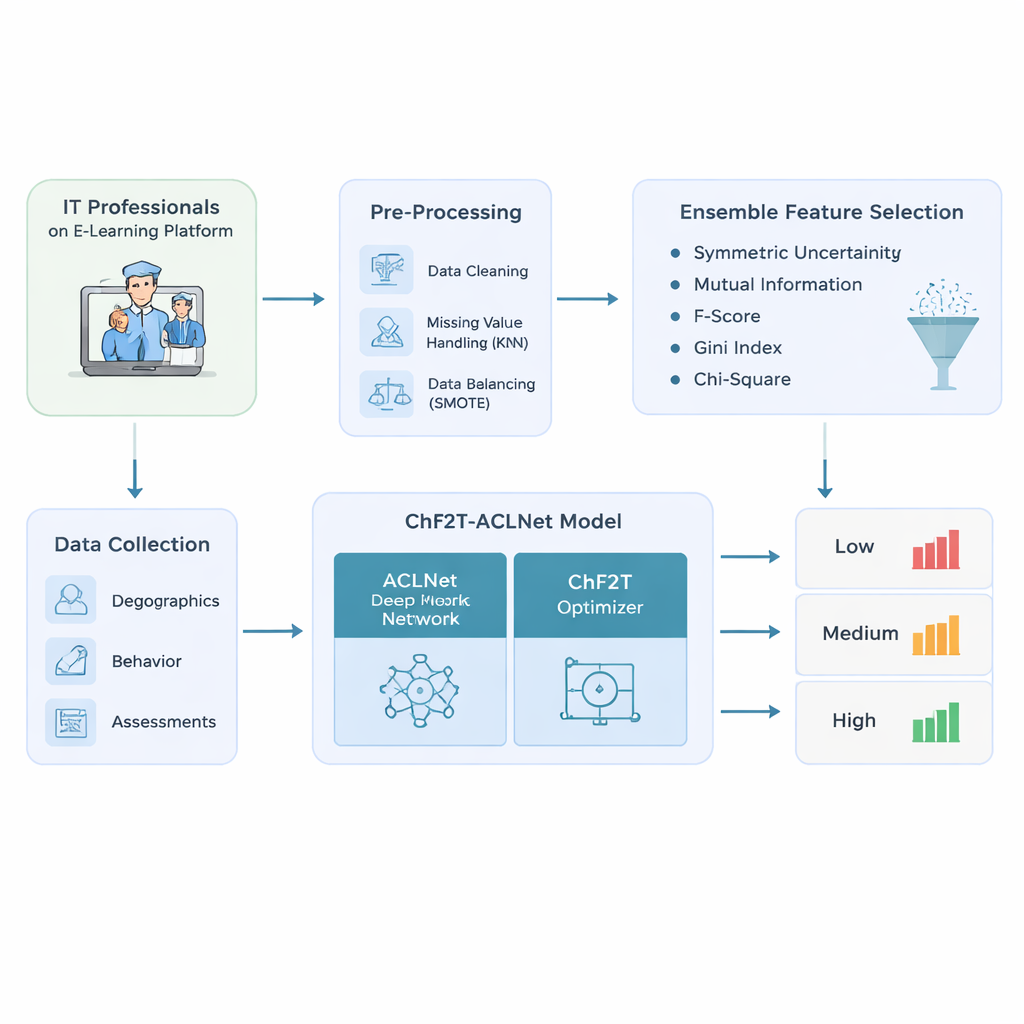
Les auteurs commencent par concevoir un pipeline de données soigné pour les professionnels IT utilisant des plateformes d’e‑learning adaptatif. Ils collectent un mélange riche d’informations : des détails de profil de base comme l’âge et le rôle professionnel ; des traces comportementales telles que le temps passé, les dates d’accès et les jours actifs ; et des indicateurs de performance incluant scores de quiz, tentatives, certificats et évaluations de feedback. Avant tout modèle, ils nettoient les données — suppression des enregistrements en double, estimation des valeurs manquantes en se basant sur des apprenants similaires, et correction des distributions de classes déséquilibrées afin que les faibles, moyens et forts performeurs soient représentés plus équitablement. Cette étape d’équilibrage évite des modèles excessivement confiants uniquement pour les apprenants « moyens » les plus fréquents et aveugles à ceux qui rencontrent des difficultés ou excellent.
Ne sélectionner que les signaux les plus révélateurs
À partir du jeu de données nettoyé, le système n’alimente pas simplement chaque colonne disponible dans une boîte noire. Il utilise plutôt un ensemble de cinq méthodes de classement simples pour décider quelles caractéristiques sont réellement importantes pour prédire les résultats d’apprentissage. Chaque méthode examine la connexion entre une caractéristique candidate — comme le nombre de tentatives de quiz ou le temps passé — et l’étiquette finale de performance. En combinant leurs classements via un score médian, l’approche filtre les signaux bruyants ou redondants et ne conserve que les plus informatifs. Cela réduit non seulement le volume de calcul requis par le modèle ultérieur, mais l’aide aussi à se concentrer sur des motifs qui distinguent de manière significative faibles, moyens et forts performeurs.
Un réseau hybride entraîné comme une équipe sportive
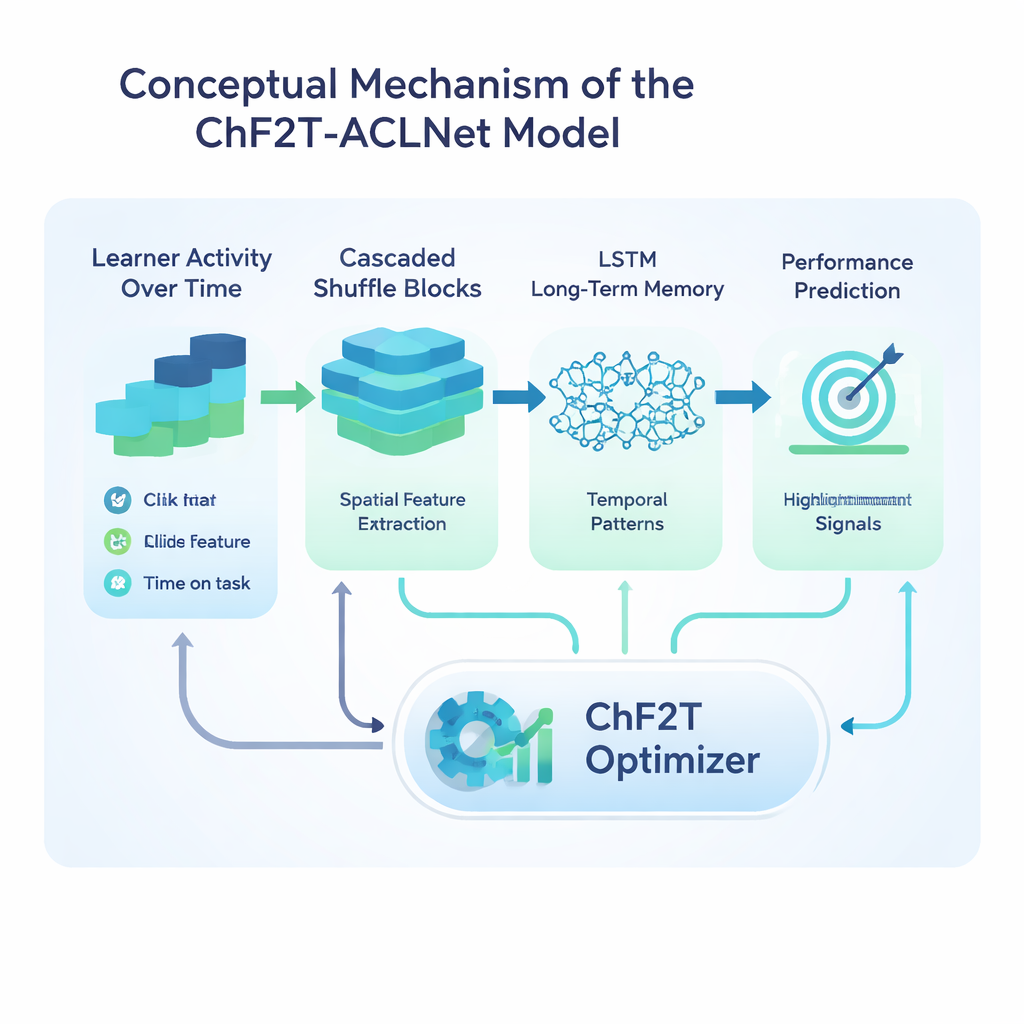
Le cœur de l’étude est un modèle d’apprentissage profond hybride appelé ACLNet, associé à une stratégie d’entraînement non conventionnelle inspirée des sports d’équipe. ACLNet utilise d’abord des blocs légers de « mélange » (shuffle) pour compresser et mélanger efficacement les signaux d’entrée, puis les transmet à un module mémoire qui retrace l’évolution du comportement d’un apprenant au fil du temps. Une couche d’attention en amont met en lumière les canaux les plus influents — comme des chutes soudaines d’activité ou des scores de quiz constamment élevés — avant de produire la prédiction finale de la classe de performance de l’apprenant. Pour régler les nombreux paramètres internes de ce réseau, les auteurs introduisent un algorithme appelé Chaotic Football Team Training (ChF2T). Ici, des « joueurs » virtuels explorent différentes configurations de paramètres, imitant les performeurs solides, évitant les faibles et effectuant parfois de grands sauts chaotiques qui aident la recherche à échapper à de mauvais optima locaux. Ce mélange de structure et d’aléatoire contrôlé accélère la convergence et réduit le surapprentissage.
Quelle est la performance du système en pratique
Les chercheurs testent leur pipeline sur un jeu de données synthétique mais réaliste de 1 200 professionnels IT, conçu pour refléter des enregistrements de systèmes de gestion de l’apprentissage avec des distributions de classes volontairement inégales. Ils comparent leur modèle ChF2T‑ACLNet à plusieurs baselines solides, y compris des configurations d’apprentissage fédéré, des réseaux de type image adaptés à l’éducation, et d’autres modèles profonds ou ensemblistes. Sur plusieurs configurations de validation croisée, la méthode proposée atteint environ 98,9 % de précision, avec des valeurs de précision, rappel et F‑score également élevées. Elle obtient aussi un score d’accord corrigé proche de la perfection et de fortes valeurs d’aire sous la courbe, ce qui signifie qu’elle sépare de manière fiable les niveaux de performance sur de nombreux seuils. Malgré sa complexité, le système s’exécute plus rapidement que les approches concurrentes, grâce à une sélection de caractéristiques soignée, un design de réseau efficace et la convergence rapide de l’optimiseur.
Ce que cela signifie pour l’apprentissage en ligne quotidien
En termes simples, ce travail montre qu’il est possible d’observer la manière dont des professionnels progressent dans des cours en ligne et d’inférer, avec une grande confiance, qui rencontre des difficultés, qui est en pilotage automatique et qui maîtrise le contenu — sans attendre un examen final. Un tel système pourrait déclencher des indices précoces, recommander des exercices différents ou alerter des mentors bien avant qu’un apprenant ne décroche. Les auteurs soulignent des défis restant à relever, notamment la montée en charge sur des plateformes très larges, l’adaptation à des conceptions de cours en rapide évolution et la facilitation de l’explicabilité des décisions du modèle. Néanmoins, leur approche constitue un pas significatif vers des systèmes d’e‑learning qui agissent plus comme des coachs personnels attentifs que comme de simples manuels numériques statiques.
Citation: Yuvapriya, P., Subramanian, P. & Surendran, R. Optimized attention-based cascaded shuffle long-term dependent network based performance analysis of adaptive e-learning among IT professionals. Sci Rep 16, 6245 (2026). https://doi.org/10.1038/s41598-026-36470-w
Mots-clés: apprentissage adaptatif, analytique de l’apprentissage, apprentissage profond, formation des professionnels IT, prédiction de la performance étudiante