Clear Sky Science · fr
Ségrégation attentive à la confidentialité de la thrombose veineuse profonde à l’aide d’un cadre d’apprentissage fédéré multi‑modèle avec l’algorithme de moyennage fédéré
Pourquoi les caillots sanguins et la confidentialité des données comptent
Les caillots sanguins qui se forment en profondeur dans les veines des jambes, appelés thromboses veineuses profondes (TVP), peuvent migrer silencieusement vers les poumons et provoquer des urgences potentiellement mortelles. Les scanners CT peuvent révéler ces caillots, mais transformer des milliers d’images en niveaux de gris en détections automatiques fiables reste une tâche difficile pour les ordinateurs. Parallèlement, les hôpitaux sont à juste titre prudents quant au partage de données patients sensibles. Cette étude explore comment plusieurs hôpitaux peuvent s’associer pour entraîner un système d’intelligence artificielle (IA) performant pour détecter les caillots — sans jamais mutualiser ni exposer leurs images brutes de patients.
Partager les cerveaux, pas les corps
Le cœur du travail est une technique appelée apprentissage fédéré, qui permet à plusieurs institutions d’entraîner des modèles d’IA de façon collaborative tout en conservant leurs données sur site. Plutôt que d’envoyer les images CT à un serveur central, chaque hôpital entraîne son propre modèle local sur ses propres scans. Seuls les paramètres appris du modèle — essentiellement ce qu’il a « appris » à propos de la reconnaissance des caillots — sont envoyés à un serveur central. Là, une approche appelée moyennage fédéré combine ces différents jeux de paramètres en un modèle global unique et amélioré, qui est ensuite renvoyé à tous les hôpitaux. De cette façon, chaque site bénéficie de l’expérience collective de tous les participants, tandis qu’aucune image patient ne quitte jamais son institution d’origine. 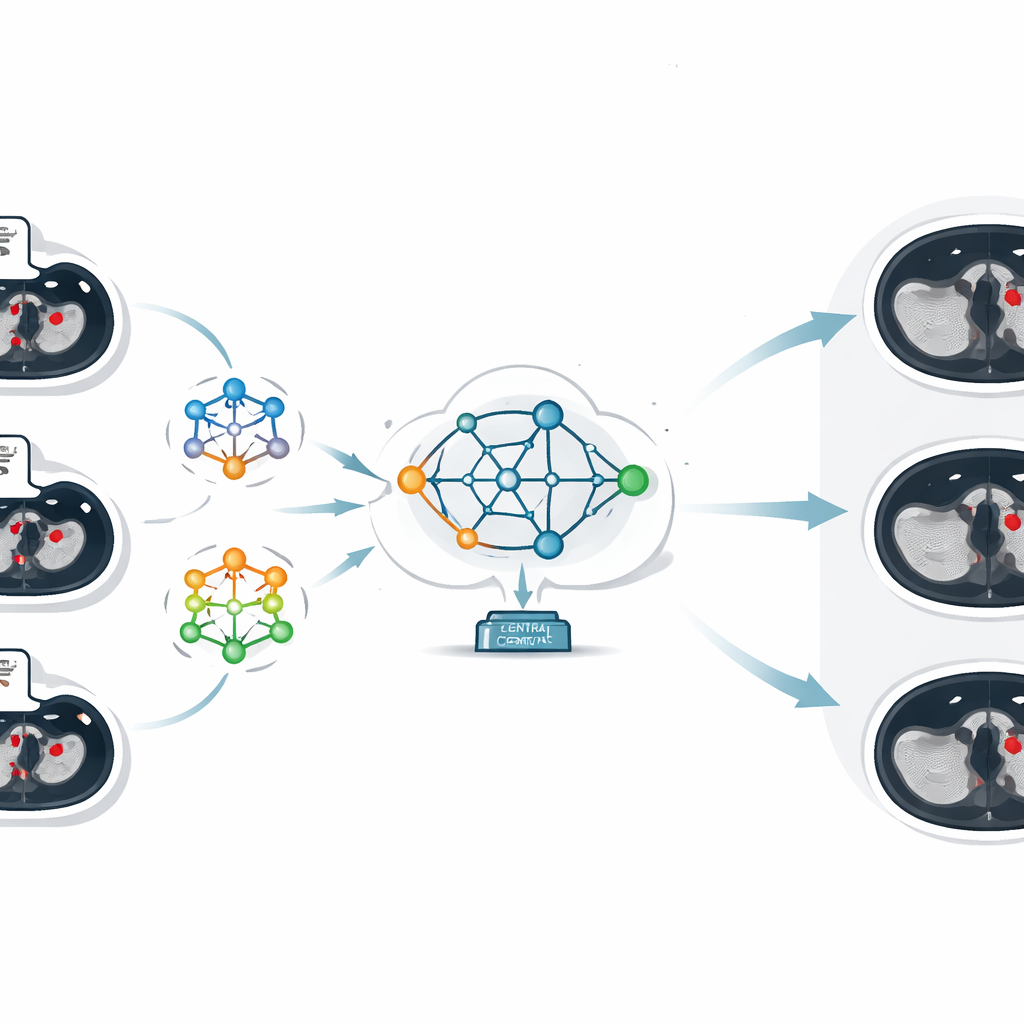
Plusieurs styles d’IA observant les mêmes veines
Une innovation clé de cette étude est que les chercheurs ne se sont pas appuyés sur un seul type de réseau neuronal. Ils ont assemblé sept architectures de modèles différentes, chacune capable de percevoir des aspects distincts des images CT. Les modèles plus simples, tels que les réseaux convolutionnels de base et les modèles séquentiels, sont plus rapides et plus faciles à exécuter sur du matériel limité. Des architectures plus avancées, incluant U‑Net, VGG‑19 et deux réseaux personnalisés avec blocs résiduels, inception, attention et traitement multi‑échelle, sont meilleures pour tracer les limites fines des vaisseaux, repérer de petits caillots et gérer des images bruitées. En permettant à chaque hôpital d’utiliser le modèle qui correspond le mieux à ses données et à sa puissance de calcul, le système reflète la réalité hétérogène des environnements cliniques réels plutôt que de supposer que chaque site est identique.
Apprendre à partir de données inégales et imparfaites
En médecine, les données d’un hôpital ressemblent rarement exactement aux données d’un autre. Les appareils, les protocoles d’imagerie et les populations de patients diffèrent, si bien que l’étude a délibérément travaillé avec des données « non‑IID » — des collections inégales et non identiquement distribuées. Cela rend normalement l’entraînement plus instable. Ici, les auteurs ont tiré parti de cette diversité et ont montré que le partage des connaissances entre plusieurs modèles structurés différemment améliorait en réalité la capacité de généralisation du système global. Ils ont mené trois phases expérimentales, d’abord avec trois clients, puis cinq, et enfin sept, en utilisant des jeux de données de 1 000, 2 000 et 3 000 images CT. À chaque étape, ils ont suivi non seulement la fréquence de segmentation correcte des caillots par le modèle global, mais aussi la quantité de communication nécessaire, la durée d’entraînement, la divergence des données de chaque client et l’efficacité des protections de confidentialité.
Meilleure détection des caillots, à un coût computationnel
Sur toutes les phases, le modèle global combiné a systématiquement surpassé n’importe quel modèle local unique. À mesure que le nombre d’images augmentait et que des modèles plus sophistiqués rejoignaient la fédération, la précision de segmentation est passée d’environ 91 % à plus de 96 %, et une mesure de qualité équilibrée, le score F1, est montée d’environ 0,89 à 0,95. Parallèlement, une mesure de perte axée sur les erreurs a diminué de plus de moitié, signalant des contours de caillots plus nets et plus fiables. Ces gains n’étaient pas gratuits : la communication entre clients et serveur est passée de quelques dizaines de mégaoctets à plusieurs gigaoctets, et le temps d’entraînement moyen est passé de quelques secondes à plusieurs heures à mesure que les architectures se complexifiaient. Néanmoins, le système a conservé une forte garantie formelle de confidentialité, indiquant que les mises à jour partagées révèlent très peu d’informations sur un patient individuel. 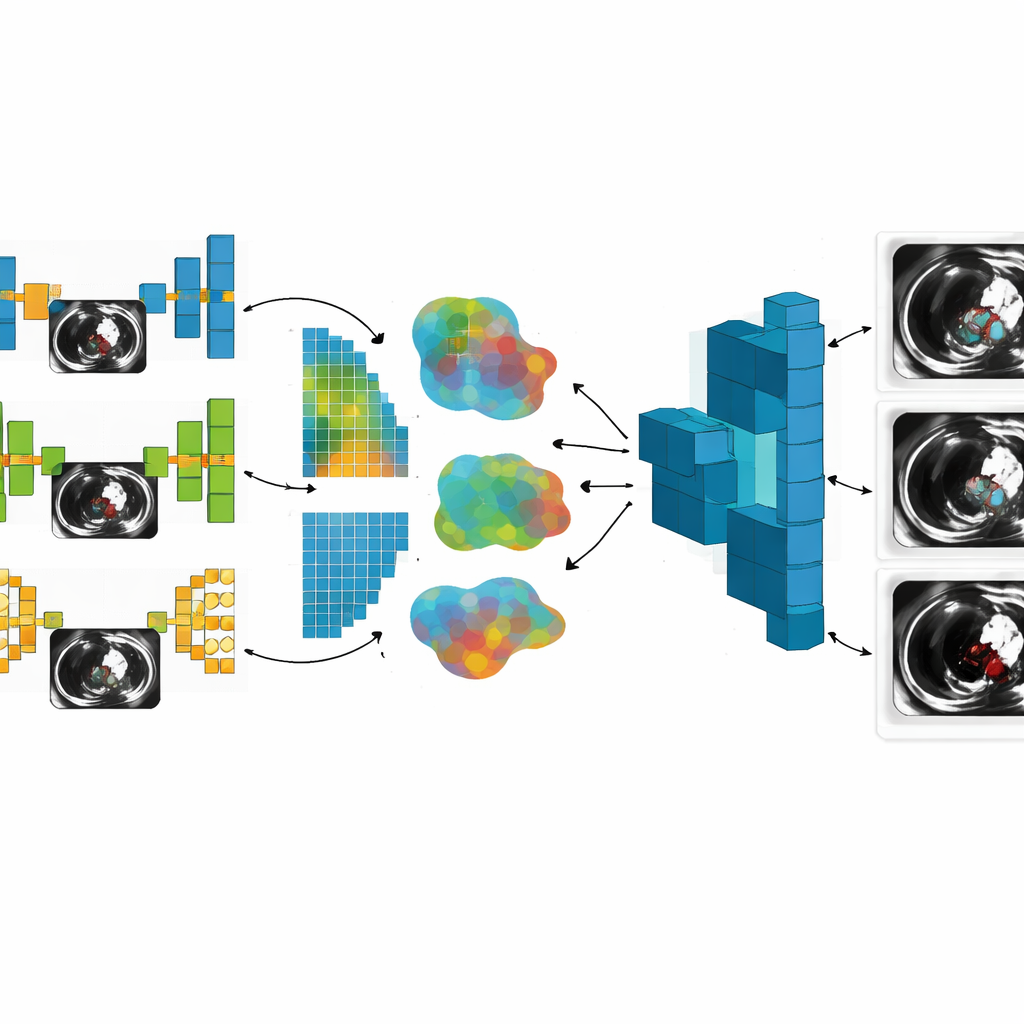
Ce que cela signifie pour les patients et les hôpitaux
Pour un non‑spécialiste, l’essentiel est que ce travail montre comment les hôpitaux peuvent enseigner à une IA commune à repérer les caillots dangereux plus précisément, sans céder le contrôle de leurs données sensibles. En combinant plusieurs architectures complémentaires et en agrégeant soigneusement ce que chacune apprend, les auteurs construisent un système de segmentation de caillots à la fois puissant et respectueux de la vie privée. Bien que l’approche exige des ressources de calcul et une bande passante réseau substantielles, elle ouvre la voie à un avenir où les centres médicaux collaborent régulièrement sur des outils diagnostiques plus intelligents, améliorant la prise en charge des patients à risque de TVP et d’affections connexes tout en gardant leurs images personnelles en sécurité au sein des murs institutionnels.
Citation: B, P.L., S, V. Privacy-aware deep vein thrombosis segmentation using a multi-model federated learning framework with the federated averaging algorithm. Sci Rep 16, 11333 (2026). https://doi.org/10.1038/s41598-026-36432-2
Mots-clés: thrombose veineuse profonde, apprentissage fédéré, segmentation d’images médicales, IA préservant la confidentialité, imagerie CT