Clear Sky Science · fr
Une méthode de désambiguïsation d'entités dans les courts textes basée sur le modèle BERT et l'algorithme du plus court chemin
Pourquoi il est important de trier les noms ambigus
Chaque jour, nous recherchons, faisons défiler et discutons à l'aide de courts extraits de texte souvent désordonnés — tweets, requêtes de recherche, messages de chat. Ces extraits regorgent de noms de personnes, de lieux, d'entreprises et d'objets qui peuvent avoir plusieurs sens, comme « Apple » le fruit ou « Apple » l'entreprise. Les ordinateurs doivent deviner quel sens nous visons, et lorsqu'ils se trompent, les résultats de recherche, les recommandations et les services en ligne deviennent beaucoup moins utiles. Cet article présente une nouvelle manière d'aider les machines à interpréter correctement ces noms ambigus dans les textes courts, en particulier pour les réseaux sociaux et la recherche en chinois, en combinant des modèles de langage modernes avec un algorithme de graphe astucieux.
Des textes courts et brouillons vers des cibles claires
Les textes courts sont étonnamment difficiles à comprendre pour les ordinateurs. Contrairement aux longs articles, ils contiennent très peu de contexte et sont remplis d'argot, d'abréviations et de phrases incomplètes. Les méthodes traditionnelles tentaient d'associer un nom dans le texte à des entrées d'une base de connaissances, ou utilisaient des règles manuelles et des modèles d'apprentissage automatique plus simples. Ces approches traitent souvent chaque mot comme s'il avait un sens fixe, ce qui échoue quand le même mot peut représenter un titre de poste, une entreprise ou une chanson selon l'usage. Le résultat est une confusion fréquente sur l'entité du monde réel à laquelle un mot dans un tweet ou une requête se réfère réellement.
Apprendre au système à repérer les noms ambigus
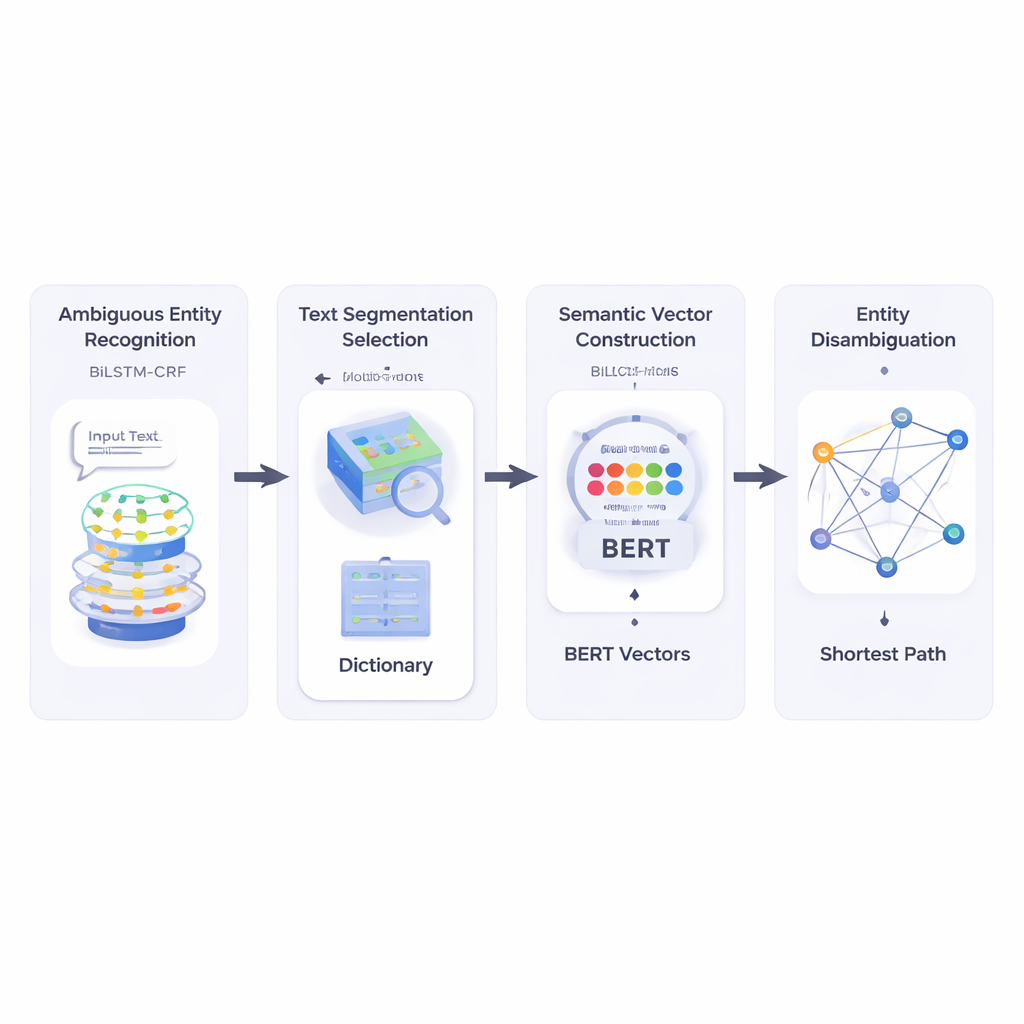
Les auteurs construisent d'abord un système qui lit un court texte et identifie quelles parties sont des noms d'entités et lesquelles de ces noms pourraient être ambiguës. Ils utilisent une combinaison de réseaux neuronaux appelée BiLSTM-CRF, efficace pour étiqueter des séquences de mots en regardant à la fois le contexte gauche et droit. Une fois les entités potentielles marquées, le système consulte une grande ressource lexicale nommée HowNet. Si HowNet répertorie plusieurs sens pour un mot, ce mot est signalé comme ambigu ; s'il n'y a qu'un seul sens, le mot est considéré comme déjà clair. Cette étape fournit au système une liste ciblée de noms qui ont réellement besoin d'être désambiguïsés.
Transformer les sens en points dans l'espace
Ensuite, la méthode segmente le texte court en segments de mots candidats et choisit la meilleure segmentation en vérifiant dans quelle mesure chaque coupe possible s'aligne, en termes de sens, avec des mots de référence déjà compris dans la même phrase. Pour mesurer cela, les auteurs s'appuient sur BERT, un puissant modèle de langage pré-entraîné qui produit un « vecteur sémantique » numérique pour chaque occurrence de mot, capturant son sens dépendant du contexte. En calculant la similarité cosinus entre ces vecteurs, le système trouve la segmentation dont les morceaux sont les plus compatibles sémantiquement avec les termes de référence non ambigus. Cela permet au modèle de représenter chaque sens possible de chaque mot comme un point dans un espace multidimensionnel.
Trouver le chemin le plus court vers le bon sens
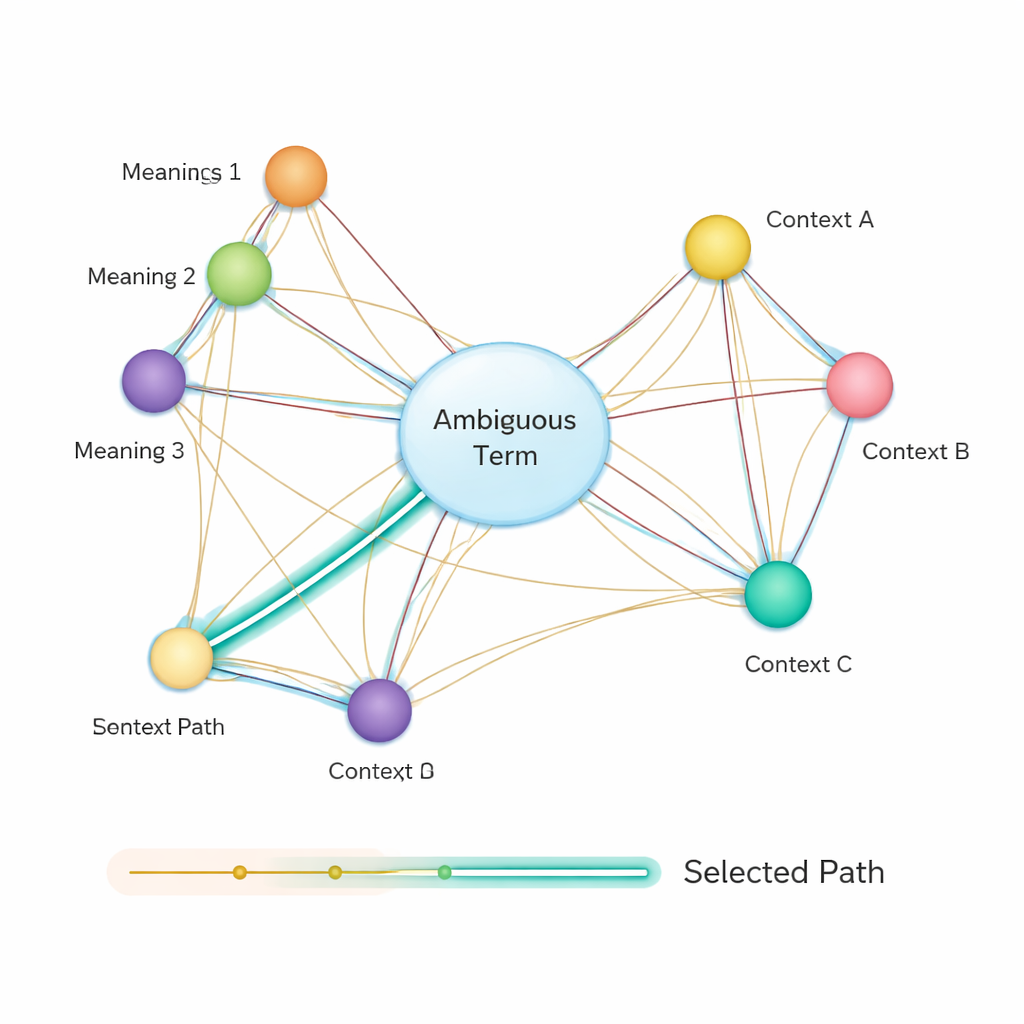
Après cela, la méthode construit un réseau sémantique : un graphe où chaque sens possible de chaque terme est un nœud, et des arêtes relient des sens qui pourraient co‑occurrence dans la même phrase. La force de chaque arête est basée sur la similarité des sens, encore une fois en utilisant des vecteurs dérivés de BERT. Pour décider quel sens d'un mot ambigu convient le mieux à la phrase, les auteurs appliquent un algorithme classique connu sous le nom d'algorithme du plus court chemin de Dijkstra. Intuitivement, le système cherche le chemin à travers ce graphe de sens qui minimise la « distance » sémantique globale. Le chemin choisi correspond à une interprétation cohérente de tous les termes, et le sens de l'entité ambiguë qui se trouve sur ce chemin est sélectionné comme réponse finale.
Quelle amélioration apporte cette méthode ?
Les chercheurs ont testé leur méthode sur un jeu de données chinois public provenant du benchmark CLUE, qui simule des scénarios réels de textes courts tels que des publications sur les réseaux sociaux et des requêtes. Ils ont comparé quatre approches : des versions utilisant des embeddings Word2Vec traditionnels, le modèle de langage ELMo, un système basé sur BERT sans l'étape du plus court chemin, et leur pipeline complet BiLSTM-CRF-BERT-SPA. Sur des milliers de textes, leur méthode complète a amélioré la précision, le rappel et le score F1 d'environ un quart en moyenne par rapport aux autres. En termes pratiques, le système était à la fois meilleur pour repérer les entités correctes et pour le faire de manière cohérente sur différentes tailles de données.
Ce que cela signifie pour la technologie quotidienne
Pour les non‑spécialistes, la conclusion est simple : en combinant un puissant modèle de compréhension du langage (BERT) avec une recherche de plus court chemin basée sur un graphe, les auteurs donnent aux ordinateurs un moyen plus fiable de décider à quoi se réfère vraiment un nom ambigu dans des textes courts et bruyants. Cela peut rendre les moteurs de recherche plus intelligents, aider les plateformes sociales à mieux comprendre les publications et améliorer des outils en aval comme les systèmes de recommandation et les graphes de connaissances. Bien que la méthode soit actuellement orientée vers le chinois et qu'elle nécessite encore des améliorations d'efficacité, elle montre comment le mélange d'IA moderne et d'algorithmes classiques peut réduire fortement la confusion dans l'interprétation de notre langage courant par les machines.
Citation: Liu, X., Zhang, D., Xiao, T. et al. A short text entity disambiguation method based on BERT model and shortest path algorithm. Sci Rep 16, 5720 (2026). https://doi.org/10.1038/s41598-026-36411-7
Mots-clés: désambiguïsation d'entités, texte court, BERT, graphe de connaissances, traitement du langage naturel