Clear Sky Science · fr
Dissociation contenu-style pour la génération d'images multi-styles utilisant une architecture de diffusion latente
Pourquoi des styles d'image plus intelligents comptent
Des affiches de films et illustrations de jeux aux filtres des réseaux sociaux, nous attendons de plus en plus des images qu’elles soient à la fois visuellement percutantes et hautement personnalisées. Mais en coulisses, de nombreux systèmes de transfert de style peinent encore : ils peuvent déformer un visage, tordre l’architecture d’un bâtiment ou exiger du matériel lourd. Cet article présente un nouveau modèle d’IA qui promet des styles artistiques plus riches tout en préservant l’image d’origine et en fonctionnant de manière suffisamment efficace pour des appareils du quotidien.
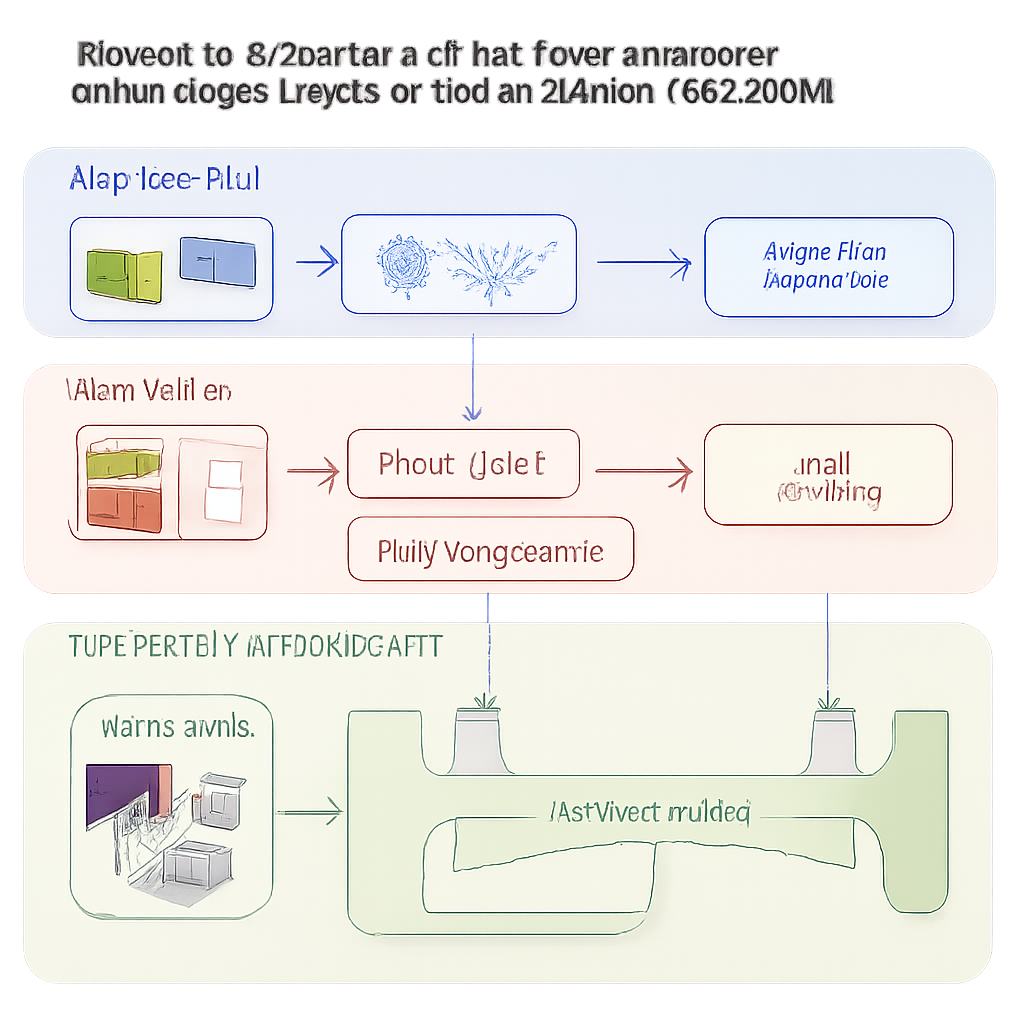
Séparer « ce que c’est » de « comment ça ressemble »
Au cœur de ce travail se trouve un modèle nommé Dual-Condition Lightweight Style Diffusion Model (DCLSDM). Son idée clé est de considérer la substance d’une image — les objets, la composition et la scène — comme un « canal », et le traitement artistique — couleurs, textures, coups de pinceau — comme un autre, et de les contrôler séparément. Plutôt que de laisser un seul réseau mêler ces deux aspects, DCLSDM utilise deux voies dédiées : l’une pour le contenu et l’autre pour le style. La voie contenu se concentre sur la compréhension des formes et des significations dans une image d’entrée ou une description textuelle, tandis que la voie style apprend le caractère visuel d’une œuvre choisie ou d’une description de style.
Comment le nouveau modèle est construit
DCLSDM s’appuie sur les modèles de diffusion, la même famille de techniques qui sous-tend de nombreux générateurs d’images modernes. Plutôt que de travailler directement sur des images en pleine résolution, il opère dans un espace « latent » compressé, bien plus efficace. Un module appelé Perceiver IO extrait le contenu : il reçoit une image ou une légende et distille la géométrie et la sémantique de la scène en une représentation compacte. Un module de style séparé lit une ou plusieurs images de style ou des textes et les convertit en vecteurs de caractéristiques de style. Ces caractéristiques de style peuvent être mélangées via un schéma d’interpolation pondéré, permettant des transitions fluides entre, par exemple, un rendu impressionniste et un rendu minimaliste sans la moyenne « boueuse » habituelle.
Préserver la structure tout en changeant le style
À l’intérieur du réseau de diffusion qui génère effectivement l’image, les deux types d’informations sont injectés par des voies indépendantes. Les signaux de contenu guident les couches du réseau qui traitent la structure — où les bords, les objets et la composition doivent se situer. Les signaux de style sont injectés via des couches d’attention dédiées qui façonnent principalement les textures, les couleurs et le travail du pinceau. Par-dessus cela, un composant appelé ControlNet ajoute une guidance structurelle supplémentaire en utilisant des cartes de contours ou de profondeur extraites du contenu original. Cette combinaison permet au système de repeindre un paysage d’été dans une palette hivernale, ou de rendre une photographie à la manière de Van Gogh, tout en conservant montagnes, arbres et bâtiments à leur place et sans distorsion.
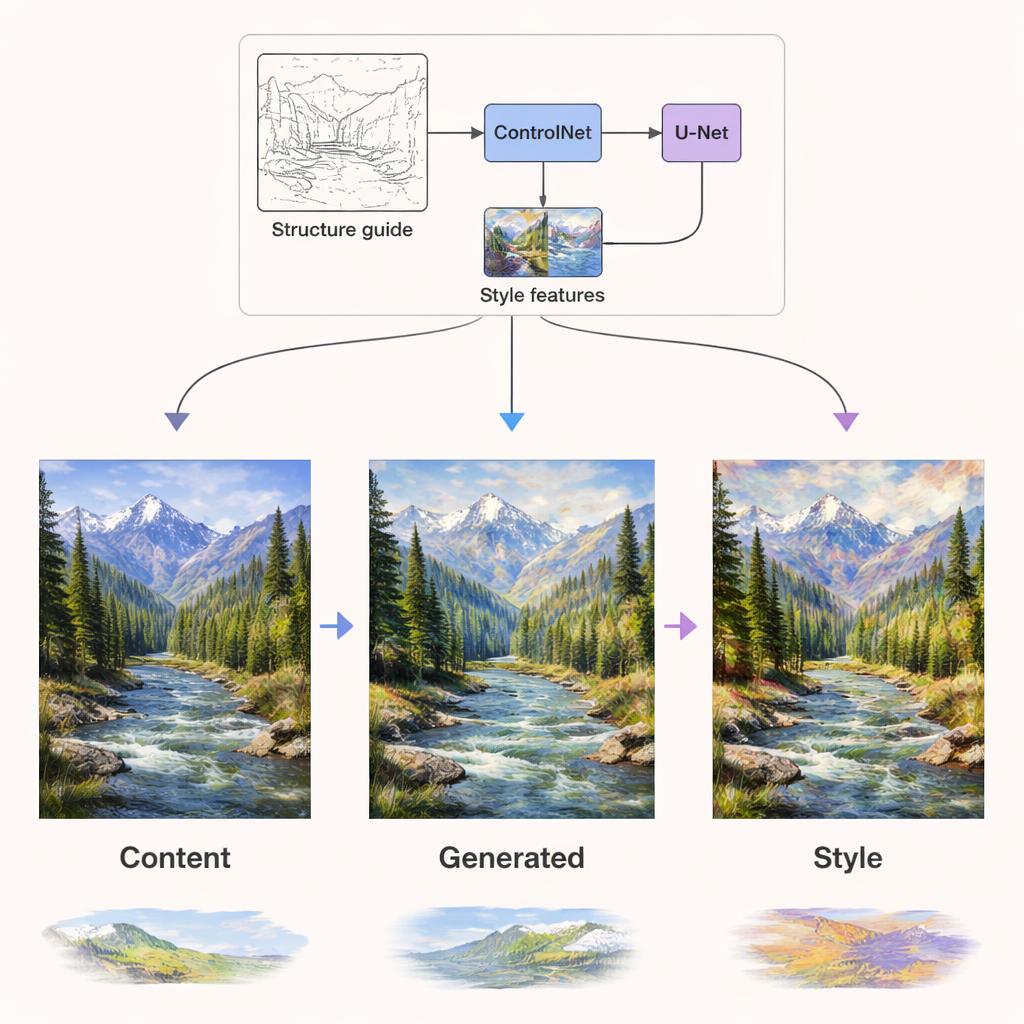
Meilleure qualité, plus de styles, moins de calcul
Les auteurs testent rigoureusement DCLSDM sur deux jeux de données publics : WikiArt, qui couvre des dizaines de mouvements artistiques, et Summer2Winter Yosemite, qui se concentre sur les changements saisonniers d’un paysage. Ils comparent leur modèle à une gamme de systèmes à la pointe utilisés en recherche et en industrie. Sur les mesures de similarité structurelle, de qualité visuelle perçue et de ressemblance des images générées avec de véritables œuvres, DCLSDM obtient systématiquement les meilleurs scores. Il s’exécute aussi plus rapidement, utilise moins de mémoire et comporte moins de paramètres que nombre de ses concurrents, tout en offrant un mélange flexible de styles multiples et en supportant des entrées de style basées sur l’image ou le texte.
Ce que cela signifie pour la créativité de tous les jours
Concrètement, ce travail montre qu’il est possible d’offrir aux utilisateurs un contrôle fin sur l’apparence d’une image sans sacrifier son contenu — et de le faire sur du matériel plus modeste. Les designers pourraient explorer rapidement de nombreux traitements artistiques d’une même mise en page, les applications mobiles pourraient proposer des filtres plus riches qui ne déforment pas les visages ou les scènes, et les projets de patrimoine culturel pourraient re-styliser de vieilles photos tout en préservant des détails structurels cruciaux. En séparant proprement contenu et style au sein d’un cadre de diffusion moderne, DCLSDM ouvre la voie à un futur où les outils d’images créatifs sont à la fois plus puissants et plus fiables pour un usage quotidien.
Citation: Chu, K., Shang, Y., Zhang, L. et al. Content style decoupling for multi style image generation using latent diffusion architecture. Sci Rep 16, 6642 (2026). https://doi.org/10.1038/s41598-026-36407-3
Mots-clés: transfert de style d'image, modèles de diffusion, dissociation contenu-style, génération d'art numérique, génération d'images efficace