Clear Sky Science · fr
Cadre d'apprentissage par renforcement pour les tests adaptatifs informatisés utilisant une approche multi‑armed bandit
Des tests plus intelligents pour la classe numérique
Toute personne ayant passé un examen long et uniforme sait à quel point cela peut être ennuyeux et injuste. Certaines questions sont beaucoup trop faciles, d'autres impossibles, et le score final ne reflète pas toujours vraiment ce que vous savez. Cet article présente une nouvelle façon de construire des tests informatiques qui s'adaptent, en temps réel, aux réponses de chaque personne. En empruntant des idées à l'intelligence artificielle moderne, les auteurs visent à rendre les examens plus courts, plus précis et mieux adaptés à la véritable compétence de chaque candidat.
Pourquoi les tests fixes sont insuffisants
Les examens traditionnels proposent à tous les étudiants la même série de questions. Cela simplifie la création des tests, mais gaspille de l'information : les étudiants performants doivent répondre à de nombreuses questions faciles, tandis que les étudiants en difficulté sont rapidement submergés. Les tests adaptatifs informatisés tentent de remédier à cela en choisissant chaque question suivante en fonction des réponses précédentes, mais la plupart des systèmes actuels reposent encore sur des modèles statistiques anciens et des règles manuelles. Ces approches traditionnelles ont du mal à capturer des schémas de réponse complexes et ne parviennent souvent pas à rendre compte pleinement des grandes variations entre apprenants dans des environnements en ligne à grande échelle.
Intégrer l'IA moderne aux évaluations
Les auteurs proposent un nouveau cadre qui combine apprentissage profond et apprentissage par renforcement pour piloter des examens adaptatifs de bout en bout. Le système fonctionne en cycles répétés. D'abord, un réseau neuronal convolutionnel unidimensionnel (1D‑CNN) analyse les réponses récentes d'une personne, la difficulté des questions et d'autres statistiques synthétiques. À partir de ce flux de données, il produit un seul nombre représentant le niveau de compétence actuel de la personne sur une échelle normalisée, de manière similaire à la façon dont les théories de test traditionnelles décrivent l'aptitude, mais appris directement à partir des données. Ce réseau est entraîné à reconnaître des motifs subtils comme la réussite régulière sur des questions plus difficiles ou des erreurs inattendues sur des questions faciles. 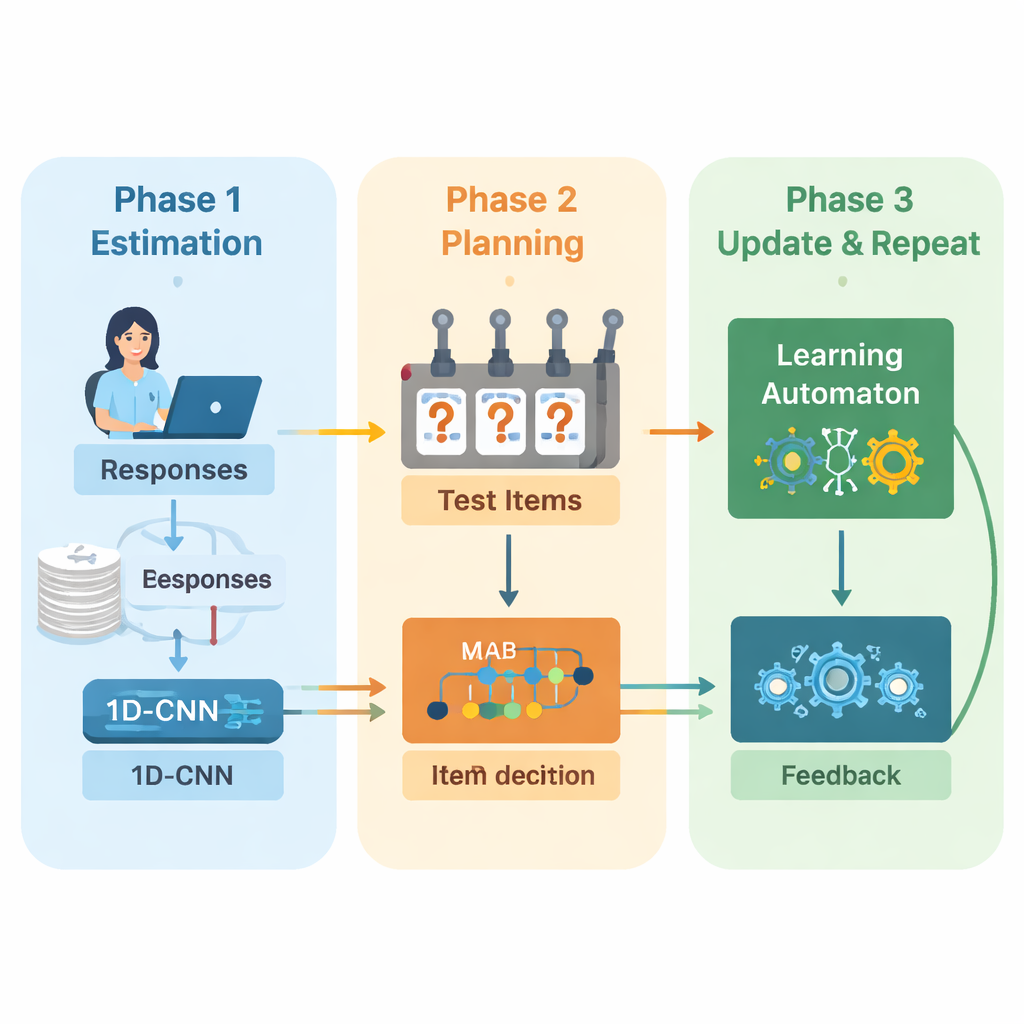
Choisir la bonne question suivante
Une fois que le système a une estimation actualisée de l'aptitude, il doit décider de la question à poser ensuite. Les auteurs utilisent ici une stratégie dite de « multi‑armed bandit », un outil classique de la théorie de la décision où chaque action possible est traitée comme tirer le levier d'une machine à sous. Dans ce contexte, chaque question de la banque d'items constitue un bras. L'algorithme examine les questions dont la difficulté correspond approximativement à l'estimation de compétence actuelle, puis choisit celles qui sont susceptibles d'être les plus informatives. Il équilibre deux objectifs : obtenir un bon ajustement de difficulté, pour que les réponses ne soient ni trop faciles ni trop difficiles, et couvrir autant de domaines de contenu que possible, afin que le test n'ignore pas des sujets importants. Un score de récompense qui combine ces deux objectifs guide le processus de sélection.
Apprendre de ses propres décisions
Pour continuer à s'améliorer au fil du test, le système ajoute un autre composant d'apprentissage appelé automate d'apprentissage. Ce module observe comment l'estimation de compétence évolue au cours des cycles et si la précision du candidat s'améliore ou décline. Il ajuste un petit ensemble de probabilités résumant si le modèle s'attend à ce que la compétence augmente, reste stable ou diminue. Ces probabilités sont ensuite renvoyées comme entrée supplémentaire au réseau neuronal lors du cycle suivant. De cette façon, le moteur de test apprend non seulement sur l'étudiant, mais aussi sur ses propres décisions passées — récompensant les tendances qui ont conduit à des estimations exactes et pénalisant celles qui ne l'ont pas été. 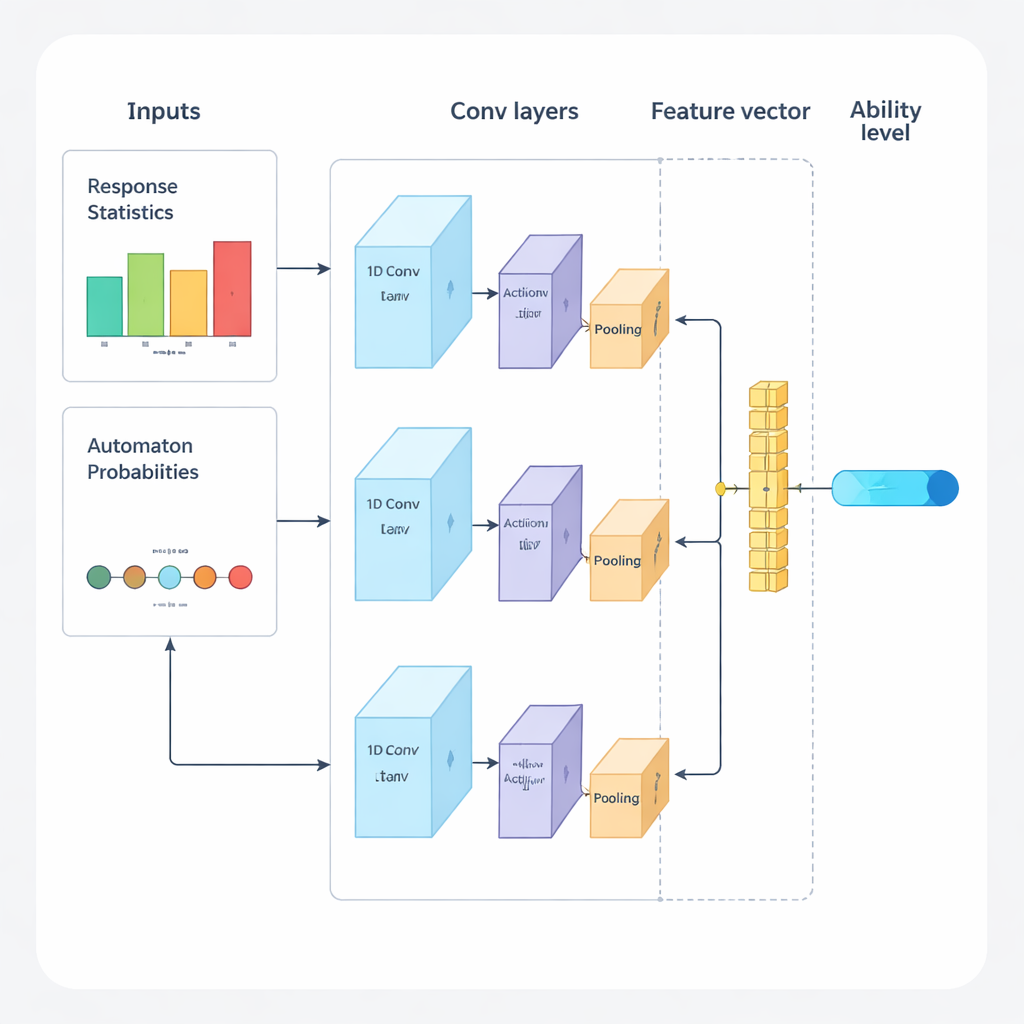
Quelle efficacité en pratique ?
Les chercheurs ont évalué leur cadre en utilisant un grand ensemble de données d'examens multilingues et des milliers de candidats simulés dont les niveaux de compétence véritables étaient connus. Ils ont comparé leur approche à plusieurs méthodes adaptatives de pointe. Sur une série de mesures d'erreur et de corrélation, le nouveau système a produit des estimations de compétence plus précises tout en nécessitant moins de questions. Ses erreurs — mesurées par des statistiques courantes telles que l'erreur quadratique moyenne et l'erreur absolue moyenne — étaient nettement inférieures à celles des méthodes concurrentes. Parallèlement, il a réparti l'utilisation des questions de manière plus homogène dans la banque d'items, réduisant le risque que certaines questions soient trop exposées et divulguées.
Ce que cela signifie pour les examens de demain
En termes concrets, ce travail suggère que les futurs tests informatisés pourraient ressembler davantage à une séance de tutorat personnalisée qu'à un examen rigide. Les questions cibleraient rapidement le bon niveau de difficulté pour chaque personne, exploreraient l'ensemble des sujets pertinents et se termineraient une fois que le système serait confiant quant à votre niveau — souvent avec moins d'items que les tests actuels. Bien que la méthode dépende encore de bonnes données d'entraînement et de puissance de calcul, et n'ait été essayée jusqu'à présent que sur un seul jeu de données, elle ouvre la voie à une nouvelle génération d'évaluations plus intelligentes, plus équitables et plus efficaces, qui s'adaptent naturellement aux apprenants individuels.
Citation: Tang, B., Li, S. & Zhao, C. Reinforcement learning framework for computerized adaptive testing using multi armed bandit approach. Sci Rep 16, 7441 (2026). https://doi.org/10.1038/s41598-026-36394-5
Mots-clés: tests adaptatifs informatisés, évaluation éducative, apprentissage profond, apprentissage par renforcement, multi-armed bandit