Clear Sky Science · fr
Un modèle de sentiment profond combinant contexte piloté par ALBERT et architecture optimisée par EHO
Pourquoi une lecture des sentiments plus intelligente est importante
Chaque jour, des millions de personnes partagent des avis sur des produits, des services, la politique et des événements sur Internet. Transformer ce flux de texte en informations fiables est essentiel pour les entreprises, les administrations et les chercheurs. Pourtant, notre langage en ligne est confus : plaisanteries sarcastiques, argot, fautes de frappe et émotions rares peuvent facilement tromper les ordinateurs. Cet article présente un nouveau système d’analyse de sentiment qui vise à mieux lire ces émotions, tout en consommant moins de ressources informatiques que de nombreux modèles d’intelligence artificielle actuels.
Des simples comptes de mots à une lecture consciente du contexte
Les premiers outils d’analyse de sentiment traitaient le texte comme un sac de mots déconnectés, comptant la fréquence de termes comme « bon » ou « terrible ». Cette approche ignorait l’ordre des mots et le contexte subtil, comme « pas mal » signifiant quelque chose de proche de « plutôt bien ». Les méthodes d’apprentissage profond ont progressé en traitant le texte comme des séquences, mais elles nécessitaient souvent d’importants jeux de données annotés et de lourds calculs. Les modèles Transformer tels que BERT ont encore amélioré la précision, mais leur grande taille les rend coûteux à déployer dans des contextes réels comme les plateformes de service client ou la surveillance des réseaux sociaux. Les auteurs de cet article répondent à ce défi en combinant plusieurs composants plus légers mais puissants en un système rationalisé.
Un cerveau plus léger pour comprendre le texte
Au cœur du modèle se trouve ALBERT, un cousin compact du modèle de langage BERT. ALBERT transforme chaque mot d’une phrase en une représentation numérique contextualisée, capturant comment le sens varie selon les mots voisins. Contrairement aux modèles volumineux, ALBERT réduit l’utilisation de la mémoire en partageant des paramètres entre les couches et en compressant son vocabulaire de mots. Cela facilite son exécution sur du matériel standard sans sacrifier beaucoup de compréhension. Ces représentations de mots basées sur ALBERT deviennent l’entrée d’une séquence de couches spécialisées qui se concentrent sur la façon dont les sentiments se déploient au sein d’une phrase.
Laisser deux systèmes de mémoire travailler ensemble
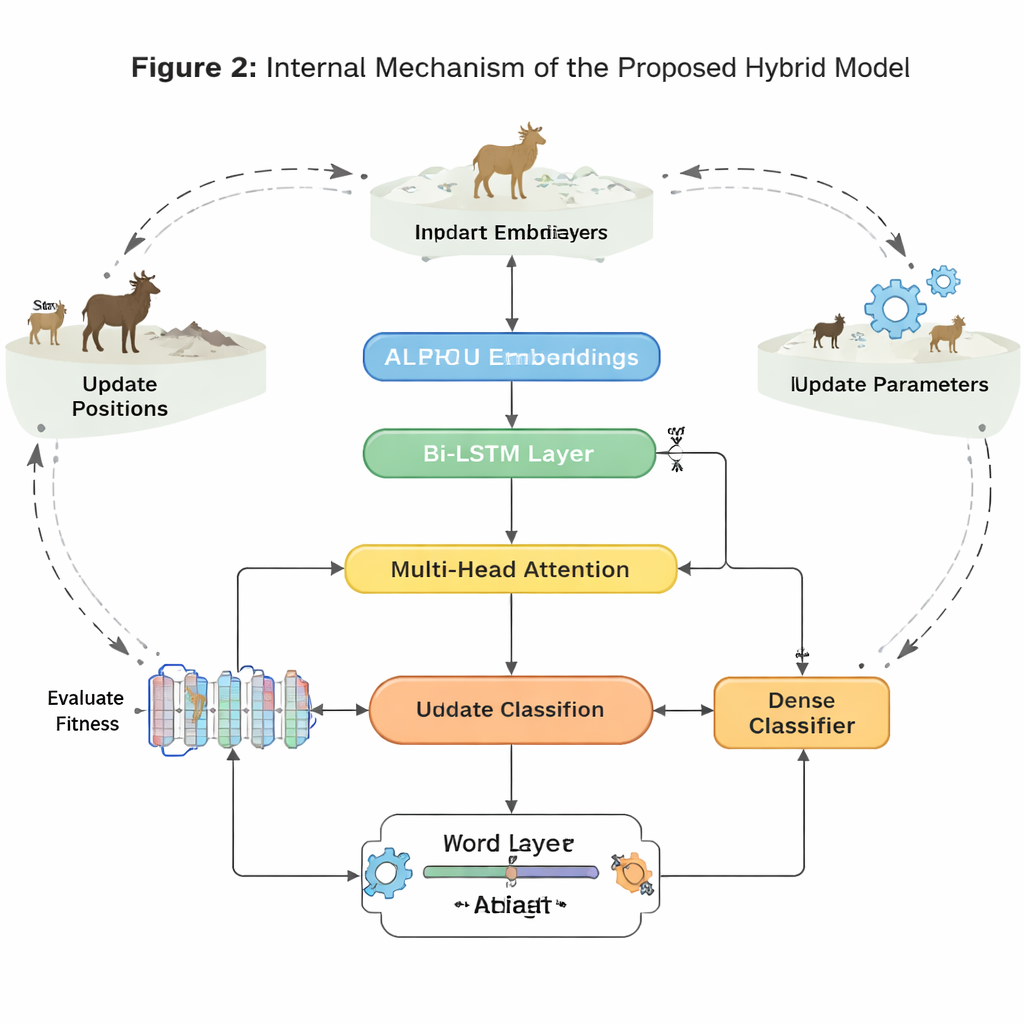
Pour suivre comment le sens évolue mot par mot, le système utilise deux types de réseaux récurrents : des GRU (Gated Recurrent Units) et des LSTM (Long Short-Term Memory), chacun exécuté dans les directions avant et arrière. Les GRU sont efficaces pour suivre des expressions courtes avec moins de paramètres, tandis que les LSTM sont meilleurs pour retenir des informations sur de plus longues portions de texte. En empilant une couche GRU bidirectionnelle au-dessus d’une couche LSTM bidirectionnelle et en ajoutant un mécanisme d’attention, le modèle peut mettre en évidence les parties les plus chargées en sentiment de chaque phrase — comme la tournure « sauf la durée de la batterie » dans un avis par ailleurs positif. Ce design hybride vise à saisir à la fois les variations rapides de ton et le contexte de plus longue portée qui peut inverser le sentiment global.
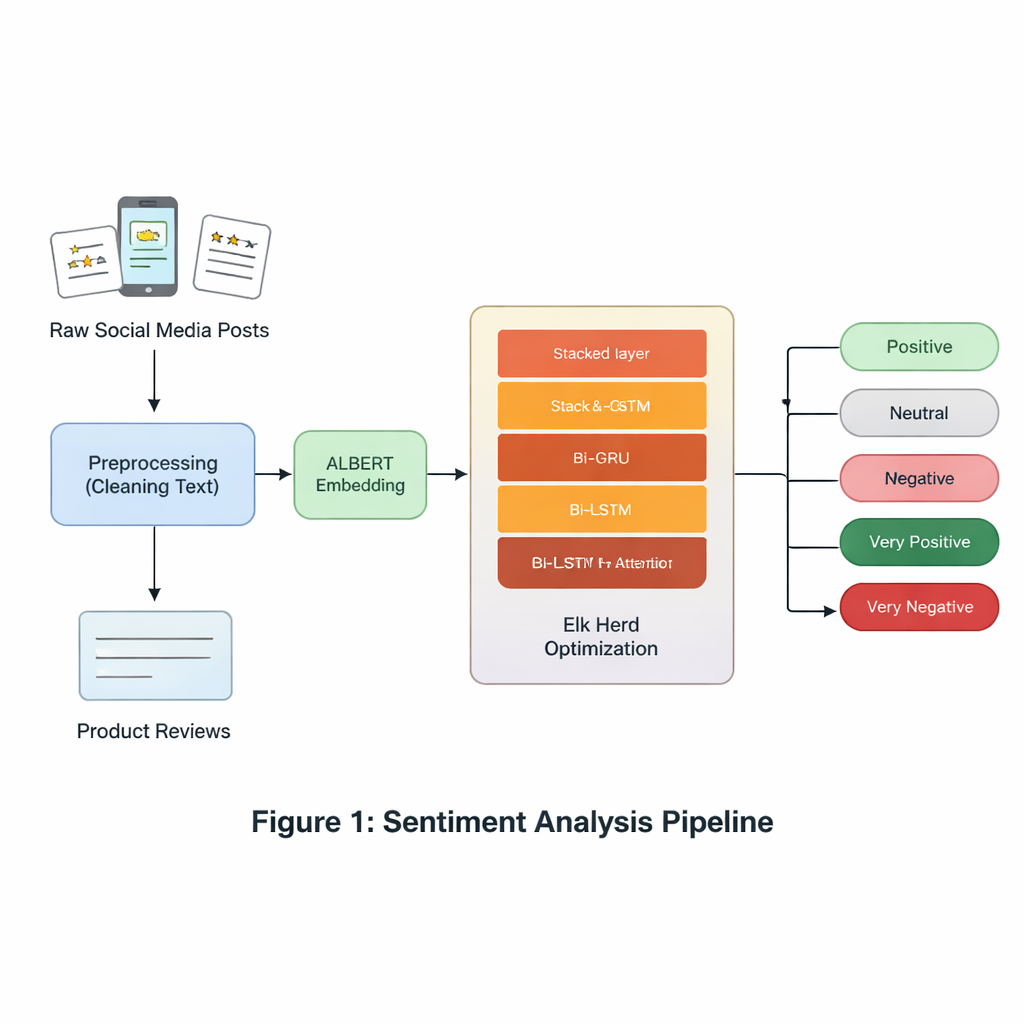
Un réglage inspiré de la nature pour les cas difficiles
Au-delà de l’architecture, les auteurs s’attaquent à un obstacle clé du monde réel : les jeux de données de sentiment sont souvent déséquilibrés et bruyants. Des émotions comme le dégoût ou la surprise, ainsi que les énoncés neutres, apparaissent moins fréquemment que les classes clairement positives ou négatives, poussant de nombreux modèles à les ignorer. Pour contrer cela, l’article utilise l’Elk Herd Optimization, une stratégie de recherche inspirée de la nature modélisant les déplacements, la compétition et la formation de groupes chez les élans. Après que le réseau de neurones ait produit des vecteurs internes de sentiment, cette étape d’optimisation affine la façon dont ces vecteurs représentent chaque classe, en particulier les classes rares, en améliorant itérativement un score de « fitness ». Ce processus aide le modèle à éviter des solutions superficielles et améliore sa capacité à distinguer des émotions subtiles ou sous-représentées.
Mettre le modèle à l’épreuve
Les auteurs évaluent leur système sur six jeux de données largement utilisés, incluant des tweets, des avis de restaurants et d’ordinateurs portables, et un benchmark de critiques de films à cinq niveaux qui distingue les opinions très positives et très négatives des opinions plus modérées. Sur ces sources variées, la nouvelle approche dépasse systématiquement plusieurs concurrents avancés basés sur des graphes et des Transformers tant en précision qu’en score F1, une métrique qui équilibre les bonnes détections et les cas manqués. Les gains sont particulièrement prononcés sur la tâche à cinq classes des critiques de films et sur les classes de sentiment sous-représentées, montrant que la méthode peut traiter à la fois des émotions fines et des données déséquilibrées. Une étude d’ablation, où les composants sont retirés un à un, confirme que ALBERT, le design combiné GRU–LSTM, l’attention et l’optimisation inspirée des élans contribuent chacun à la performance globale.
Ce que cela signifie pour les applications courantes
Pour les non-spécialistes, la leçon principale est que cette recherche offre une manière plus efficace et plus fiable d’interpréter de grands volumes d’opinions en ligne. En combinant un modèle de langage compact avec des couches mémorielles complémentaires et une étape de réglage inspirée biologiquement, le système lit mieux entre les lignes, surtout lorsque les sentiments sont subtils ou que les données sont biaisées. Cela en fait une solution prometteuse pour des usages concrets comme le suivi de la satisfaction client, la surveillance des attitudes en santé publique ou l’évaluation des réactions aux politiques et aux événements, où la précision et le coût de calcul comptent tous deux.
Citation: Oqaibi, H., Sharma, S. A deep sentiment model combining ALBERT-driven context and EHO-optimized architecture. Sci Rep 16, 5784 (2026). https://doi.org/10.1038/s41598-026-36389-2
Mots-clés: analyse de sentiment, ALBERT, apprentissage profond, classification de texte, optimisation métaheuristique