Clear Sky Science · fr
Méthode d’allocation de ressources pour l’internet des objets cognitif basée sur un algorithme d’apprentissage par renforcement multi‑agent
Pourquoi les données de votre voiture doivent rester « fraîches »
Les voitures modernes partagent en permanence des informations sur leur position, leur vitesse et leur environnement avec d’autres véhicules et des dispositifs routiers. Pour que les fonctions de sécurité et les futures fonctions de conduite autonome fonctionnent correctement, ces informations doivent être non seulement exactes, mais aussi récentes : une alerte de freinage arrivée avec une seconde de retard peut être inutile. Cet article explore comment maintenir ces données aussi à jour que possible sur des réseaux sans fil encombrés, en utilisant une nouvelle méthode de contrôle fondée sur l’apprentissage qui permet aux véhicules de décider eux‑mêmes comment et quand transmettre.
Des routes intelligentes qui partagent les ondes
L’étude considère un réseau routier futur où des milliers de voitures connectées se partagent un spectre radio limité avec des utilisateurs existants tels que les abonnés de téléphonie mobile. Ce cadre, appelé Internet des objets cognitif, suppose que les voitures sont des « invités polis » : elles ne peuvent emprunter des fréquences que si cela ne perturbe pas les utilisateurs primaires. En parallèle, les véhicules doivent communiquer rapidement entre eux et avec des stations de base pour permettre des avertissements de collision, la coordination du trafic et des services de divertissement. Trouver un équilibre entre ces exigences est difficile parce que les voitures roulent vite, les signaux s’atténuent en traversant les îlots urbains et les canaux disponibles changent d’un instant à l’autre.
Mesurer la fraîcheur, pas seulement la vitesse
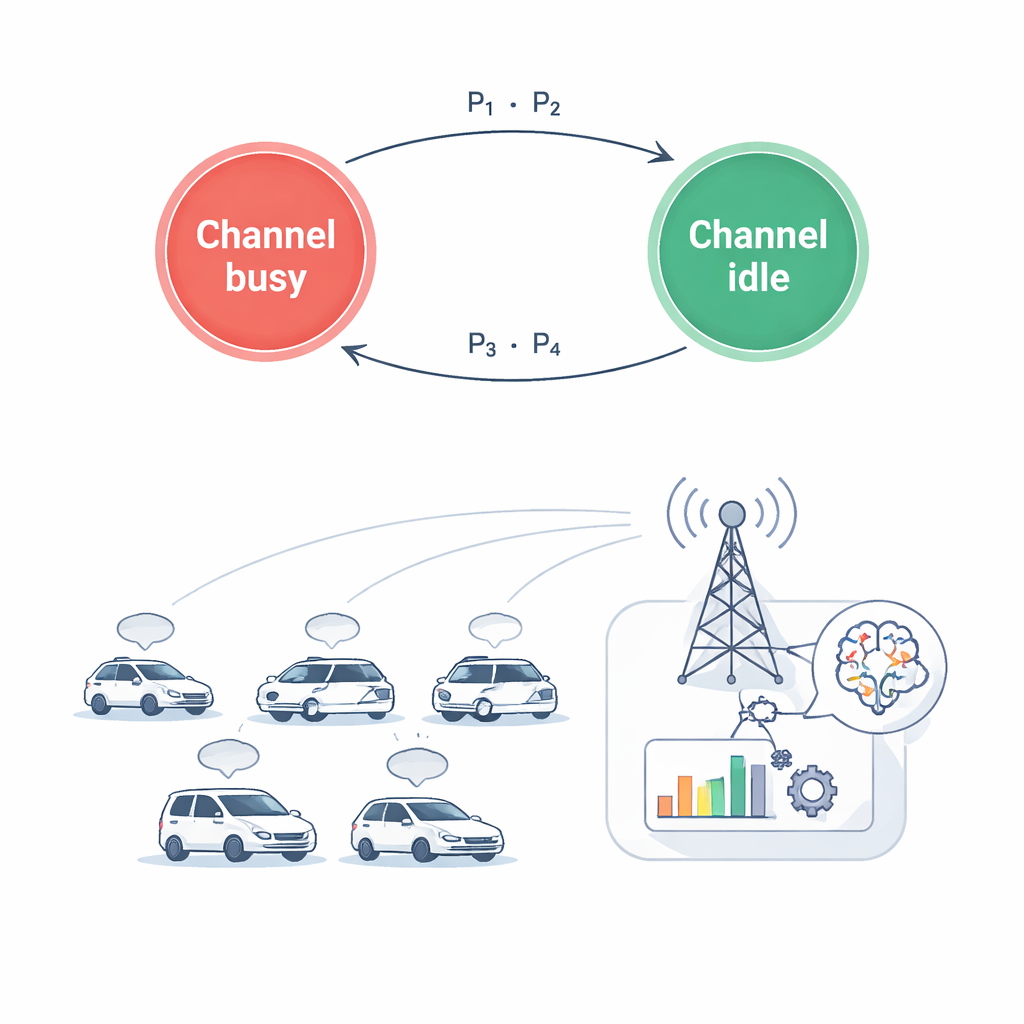
La conception réseau traditionnelle se concentre souvent sur l’augmentation du débit ou la réduction du délai moyen. Toutefois, pour les messages critiques de sécurité des véhicules, ce qui compte vraiment, c’est l’âge de la dernière mise à jour de statut lorsqu’elle atteint le récepteur. Les auteurs utilisent une métrique appelée Âge de l’Information, qui augmente avec le temps écoulé depuis la dernière mise à jour réussie et est réinitialisée lorsqu’un nouveau message arrive. Dans leur modèle, chaque paire de véhicules envoie de façon répétée des blocs de données. Si la liaison sans fil est forte et que le niveau de puissance choisi est suffisamment élevé, le bloc courant est transmis rapidement et l’âge retombe ; si la connexion est mauvaise ou la puissance limitée, des données non transmises s’accumulent et l’âge continue d’augmenter. L’objectif est de choisir les canaux radio et les niveaux de puissance de façon à maintenir cet âge le plus bas possible, tout en économisant de l’énergie et en protégeant les utilisateurs primaires des interférences.
Apprendre aux voitures à coopérer par essai et erreur
Parce que l’environnement sans fil évolue rapidement et que chaque voiture ne perçoit qu’une information locale, les auteurs posent le problème comme une tâche d’apprentissage plutôt que comme une formule fixe. Chaque voiture agit comme un agent intelligent qui observe à répétition sa situation : quels canaux semblent occupés, quelle est la qualité de ses liaisons radio, combien de données restent à envoyer et quel est l’âge de sa dernière mise à jour. Sur la base de cette vision partielle, elle choisit une action combinant une décision discrète (quel canal utiliser, ou rester silencieux) et une décision continue (quelle puissance de transmission utiliser). Après l’action, le système mesure la fraîcheur de l’information, la puissance consommée et si des utilisateurs primaires ont été perturbés. Ce retour est transformé en signal de récompense qui guide les agents, sur de nombreux épisodes simulés, vers de meilleures décisions conjointes.
Un algorithme d’apprentissage sur mesure pour des décisions mixtes
Pour entraîner ces agents, les auteurs développent une version multi‑agent améliorée d’une méthode populaire appelée Proximal Policy Optimization. Leur variante, IMAPPO, utilise un module d’entraînement central qui voit l’état global et évalue la qualité des actions combinées de tous les véhicules, tandis que chaque voiture apprend une règle de décision privée qu’elle peut appliquer en temps réel. Une innovation clé est un réseau de décision amélioré capable de gérer naturellement à la fois le choix binaire d’occupation des canaux et l’intervalle continu des niveaux de puissance possibles. Dans des simulations de rues en quadrillage, avec des véhicules et des stations de base placés à des positions réalistes et des effets radio tels que l’évanouissement et les interférences pris en compte, la méthode proposée est comparée à plusieurs algorithmes d’apprentissage de pointe et à une référence aléatoire.
Des données plus fraîches avec moins d’énergie
Les résultats montrent que la nouvelle méthode peut maintenir des informations sensiblement plus fraîches tout en consommant moins d’énergie. Pour différents nombres de véhicules et différentes quantités de données à envoyer, IMAPPO réduit l’Âge de l’Information moyen d’environ jusqu’à la moitié par rapport à un accès aléatoire simple, et surpasse d’autres méthodes d’apprentissage avancées avec des écarts significatifs. Parallèlement, elle réduit la puissance globale utilisée par les véhicules, contribuant à préserver l’autonomie des batteries et à limiter les interférences pour les autres utilisateurs du spectre. Pour un lecteur non spécialiste, cela signifie qu’un contrôle plus intelligent et fondé sur l’apprentissage de qui parle, quand et à quel volume sur la « voie » sans fil pourrait rendre les véhicules connectés et autonomes plus sûrs, plus efficaces et plus respectueux des ondes radio encombrées qu’ils doivent partager.
Citation: Wang, R., Shen, Y., Wang, D. et al. A cognitive internet of things resource allocation method based on multi-agent reinforcement learning algorithm. Sci Rep 16, 7756 (2026). https://doi.org/10.1038/s41598-026-36380-x
Mots-clés: véhicules connectés, partage du spectre sans fil, âge de l’information, apprentissage par renforcement, internet des objets