Clear Sky Science · fr
Identification des facteurs de risque pour les grands équipements de loisirs à l’aide d’un mélange d’experts et de la fusion de modèles multiples
Pourquoi la sécurité des parcs à thème a besoin d’une lecture plus intelligente
Chaque année, des centaines de millions de personnes montent à bord de montagnes russes, de tours de chute et d’attractions tournantes en faisant confiance à des machines complexes et à des opérateurs occupés pour assurer leur sécurité. En coulisses, les autorités de contrôle et les ingénieurs produisent d’énormes volumes de rapports, de comptes rendus d’accidents et de plaintes publiques — mais la plupart de ces informations sont sous forme textuelle, difficiles à analyser rapidement. Cette étude examine comment une intelligence artificielle avancée peut « lire » ces documents à grande échelle, repérer plus tôt des schémas de danger et donner aux autorités une vision plus claire des lieux où les attractions présentent le plus de risques de défaillance.
Des rapports dispersés à une image unifiée des risques
La Chine compte désormais plus de 25 000 grandes attractions et plus de 700 millions de visiteurs par an. Malgré des améliorations globales de la sécurité, des accidents rares mais graves se produisent encore, souvent après que des inspections n’ont pas su détecter des signaux faibles enfouis dans des descriptions techniques ou des plaintes d’usagers. Les auteurs soutiennent que la supervision traditionnelle — fondée sur des contrôles manuels périodiques, le jugement d’experts et des journaux de maintenance — est trop lente et subjective pour un environnement aussi dynamique. Ils rassemblent une grande collection de textes réels comprenant rapports d’accident, lois et normes, dossiers d’inspection et de maintenance, et plaintes en ligne liées aux installations de loisirs. Après un nettoyage et un filtrage soigneux, ce corpus multi‑sources devient la matière première d’un système automatisé de surveillance des risques fondé sur les données. 
Apprendre aux ordinateurs le langage du risque
Pour donner un sens à ces textes désordonnés, les chercheurs s’appuient sur des modèles de langue modernes qui convertissent les phrases en vecteurs numériques capturant leur signification. Ils utilisent principalement un modèle chinois nommé BGE, qui représente chaque fragment de texte comme un point de 1 024 dimensions, complété par un ensemble compact de 30 caractéristiques basées sur des mots‑clés ciblant des termes tels que « maintenance », « inspection » et « rectification ». Cette double approche — contexte sémantique profond plus expressions de risque sélectionnées manuellement — aide le système à distinguer des différences subtiles entre, par exemple, des contrôles routiniers et des défaillances graves. L’équipe teste également un autre modèle d’embedding de pointe, Qwen3, pour vérifier si un autre socle linguistique améliore les performances ; en pratique, BGE s’avère légèrement supérieur pour cette tâche de sécurité.
Découvrir des schémas cachés et des points faibles clés
Avant de classer les textes en catégories de risque concrètes, les auteurs utilisent des méthodes non supervisées pour révéler des groupements naturels. Ils appliquent un k‑means aux embeddings et utilisent une méthode de visualisation appelée UMAP pour montrer que les rapports se répartissent en plusieurs grappes thématiques nettes. Ils construisent ensuite un graphe sémantique où chaque nœud correspond à un mot‑clé lié à la sécurité et où les liens indiquent une forte cooccurrence et similarité sémantique. Un algorithme de détection de communautés regroupe ces nœuds en ensembles correspondant à de grands thèmes tels que la sécurité des équipements et des structures, l’exploitation et la maintenance quotidiennes, la réponse d’urgence, et la gestion et la supervision. Dans ce réseau, certains termes — comme « maintenance », « inspection » et « responsabilité » — jouent le rôle de ponts entre les clusters, mettant en évidence des faiblesses transversales susceptibles de déclencher des accidents de façons diverses. À partir de cette structure, ils extraient 31 facteurs de risque centraux couvrant quatre dimensions principales, depuis la surveillance en temps réel des équipements jusqu’à la clarté des responsabilités professionnelles. 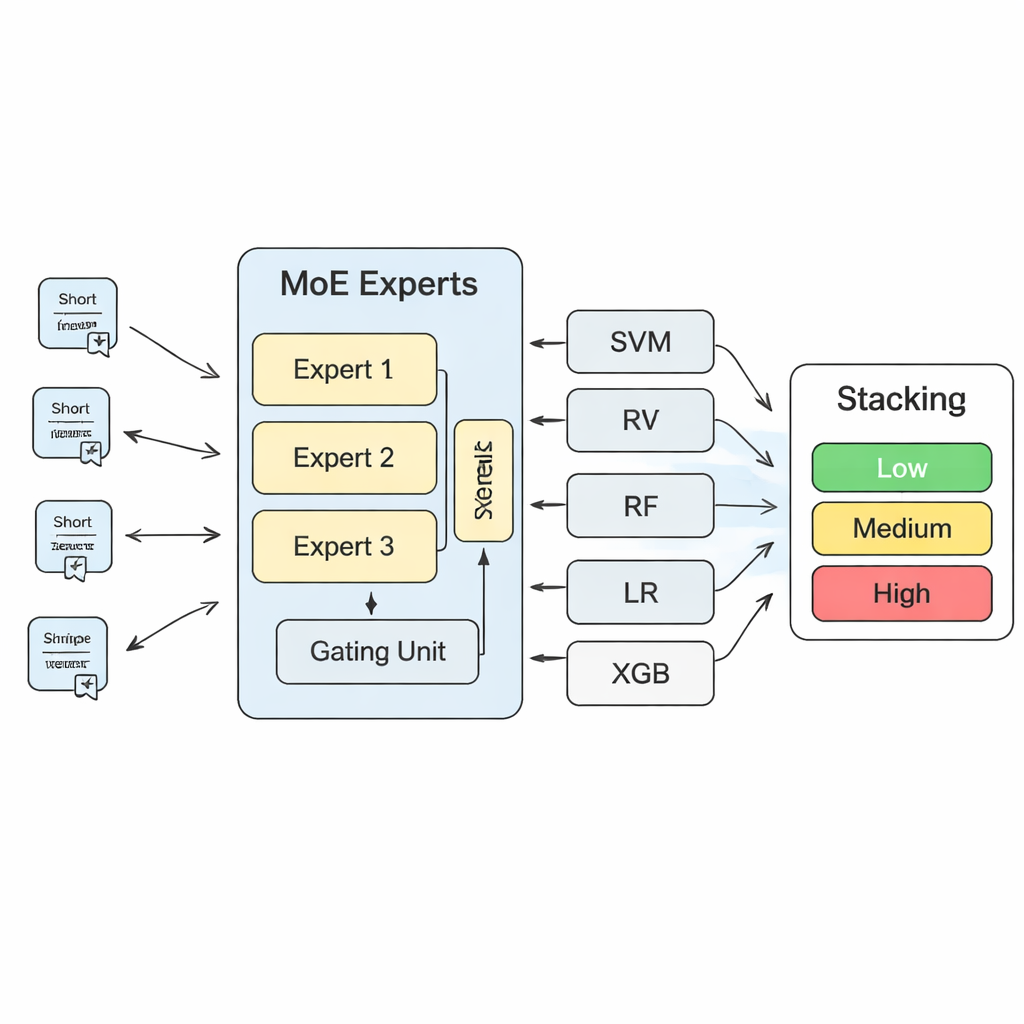
Assembler plusieurs modèles pour un juge de sécurité plus robuste
Pour transformer ces connaissances en prédictions de risque concrètes, l’étude construit un système d’apprentissage automatique à plusieurs couches. Au cœur se trouve un modèle de « mélange d’experts » (MoE) : plusieurs réseaux neuronaux, ou experts, apprennent chacun à se spécialiser sur différents types de schémas de risque, tandis qu’un composant de gating décide quels experts privilégier pour chaque nouveau texte. Les sorties de ce modèle MoE sont ensuite combinées avec les prédictions d’algorithmes plus classiques, tels que machines à vecteurs de support, forêts aléatoires, régression logistique et arbres à gradient boosté. Une couche finale de « stacking » — un autre modèle d’apprentissage — apprend à pondérer toutes ces opinions pour parvenir à une décision finale. À travers une validation croisée étendue, les auteurs constatent que l’utilisation de trois experts dans la couche MoE offre le meilleur compromis entre capacité du modèle et stabilité.
Ce que ces gains signifient pour la supervision sur le terrain
Comparé à n’importe quel modèle isolé, le système MoE plus Stacking améliore sensiblement la précision, la justesse, le rappel et une mesure de fiabilité appelée LogLoss. En termes pratiques, cela signifie moins d’avertissements manqués et moins de fausses alertes lors du tri de grands volumes de textes de sécurité. Le modèle peut fonctionner sur une station de travail ordinaire et fournir des évaluations rapides des risques pour de nouveaux rapports d’inspection ou plaintes, ce qui en fait un outil d’aide à la décision plutôt qu’un substitut au jugement humain. Les auteurs soulignent que leur approche pourrait être adaptée, au‑delà des attractions, à d’autres équipements spéciaux tels que les ascenseurs ou les téléphériques. Pour le grand public, l’essentiel est que, en apprenant aux ordinateurs à lire le langage de la sécurité — dans les documents techniques, les réglementations et les plaintes quotidiennes — les autorités peuvent détecter plus tôt des motifs de danger, cibler les inspections de manière plus intelligente et rendre une journée au parc un peu plus sûre pour tout le monde.
Citation: Hao, S., Xing, L. & Zhang, M. Risk factor identification for large scale amusement facilities using mixture of experts and fusion of multiple models. Sci Rep 16, 6804 (2026). https://doi.org/10.1038/s41598-026-36377-6
Mots-clés: sécurité des attractions, analyse de texte de risque, apprentissage automatique, mélange d’experts, surveillance de la sécurité publique