Clear Sky Science · fr
Apprentissage de groupes dans les systèmes de recommandation : vers une modélisation de groupe adaptative et implicite
Pourquoi des groupes plus intelligents comptent en ligne
Des soirées cinéma entre amis aux vacances en famille, beaucoup de nos choix sont pris en groupe. Pourtant, la plupart des plateformes en ligne réfléchissent encore en termes d’individus. Cet article pose une question simple aux implications importantes : et si nos sites de streaming, applications de shopping et portails de voyage pouvaient découvrir et s’adapter discrètement à des groupes naturels de personnes et d’éléments par eux‑mêmes, au lieu de s’appuyer sur des listes de groupes fixes et fabriquées ? Les auteurs proposent une nouvelle manière pour les systèmes de recommandation d’apprendre automatiquement ces groupes, afin de produire des suggestions qui paraissent équitables et satisfaisantes pour tous les participants.
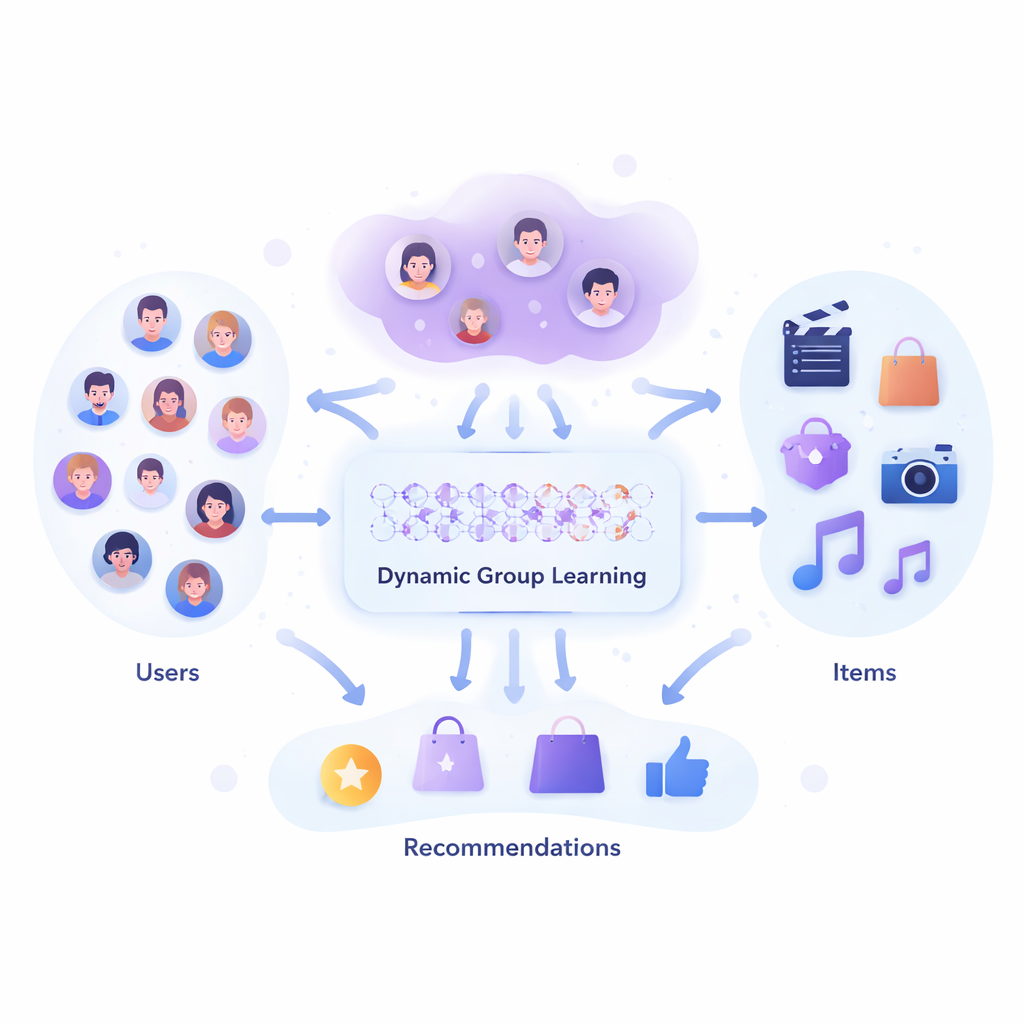
Des équipes fixes aux foules flexibles
Les outils actuels de recommandation de groupe partent souvent d’une idée rigide de qui appartient à qui : un cercle d’amis prédéfini, une classe, ou des clusters construits une fois par un outil statistique. Le système cherche alors un élément « suffisamment bon » pour ce groupe figé. Mais la vie réelle est plus complexe. L’ensemble de personnes qui choisissent un film ce soir peut être différent de celui qui réserve des vacances le mois prochain, et les éléments eux‑mêmes peuvent se regrouper naturellement en bundles, comme des playlists ou des forfaits de voyage. L’article soutient que plutôt que de traiter la formation des groupes comme une étape séparée et ponctuelle, elle devrait être intégrée au cœur de la façon dont le recommandateur apprend à partir des données.
Une carte cachée des personnes et des objets
Les auteurs présentent un modèle qu’ils nomment Deep Dynamic Group Learning Model, ou DDGLM. Au fond, le système construit une carte cachée où personnes et éléments sont représentés comme des points dans un espace mathématique. Plutôt que d’affecter chaque personne ou produit à un seul groupe fixe, le modèle leur permet d’appartenir à plusieurs « groupes doux » qui se chevauchent, avec différents degrés d’appartenance. Un paramètre de température affine ces appartenances au fur et à mesure de l’apprentissage, de sorte qu’au moment de l’utilisation opérationnelle, chaque personne ou élément est effectivement placé dans le groupe qui convient le mieux à la tâche. Ces groupes appris ne reposent pas seulement sur des traits visibles comme l’âge ou le genre, mais sur leur utilité à aider le système à prédire les notes ou choix réels des utilisateurs.
Harmoniser individus et groupes
DDGLM va plus loin en exigeant que la représentation d’une personne en tant qu’individu et celle en tant que membre d’un groupe concordent. Il ajoute un terme supplémentaire à son processus d’apprentissage qui rapproche en douceur les représentations individuelles et de groupe. Cela empêche les profils de groupe de dériver vers des motifs irréalistes qu’aucun membre ne reflète vraiment, tout en permettant au modèle de capturer des goûts partagés. Grâce à ces représentations, le système peut gérer quatre situations courantes de manière unifiée : recommander un élément à une personne, un élément à un groupe, un ensemble d’éléments à une personne, ou un ensemble à un groupe. Dans chaque cas, les recommandations se réduisent à de simples comparaisons entre les personnes pertinentes et les groupes d’éléments à l’intérieur de la carte cachée.
Les groupes adaptatifs aident‑ils vraiment ?
Pour tester l’efficacité de cette idée, les auteurs ont mené des expérimentations étendues sur des collections bien connues de notes de films appelées MovieLens‑100K et MovieLens‑1M. Ils ont comparé DDGLM à des méthodes qui forment des groupes au hasard, via un clustering traditionnel, ou par d’anciens cadres de recommandation unifiés. Sur les quatre scénarios — individuel, groupe, paquet et paquet‑vers‑groupe — le modèle dynamique produisait des prédictions de notes plus précises et de meilleures suggestions en tête de liste. Il était particulièrement performant lorsque des groupes ou des bundles intervenaient, là où les approches statiques peinaient. Des tests statistiques rigoureux ont confirmé que ces gains n’étaient pas dus au hasard, et des expérimentations sur les temps d’exécution ont montré que la méthode scale bien lorsque le nombre d’utilisateurs, d’éléments et de groupes augmente.
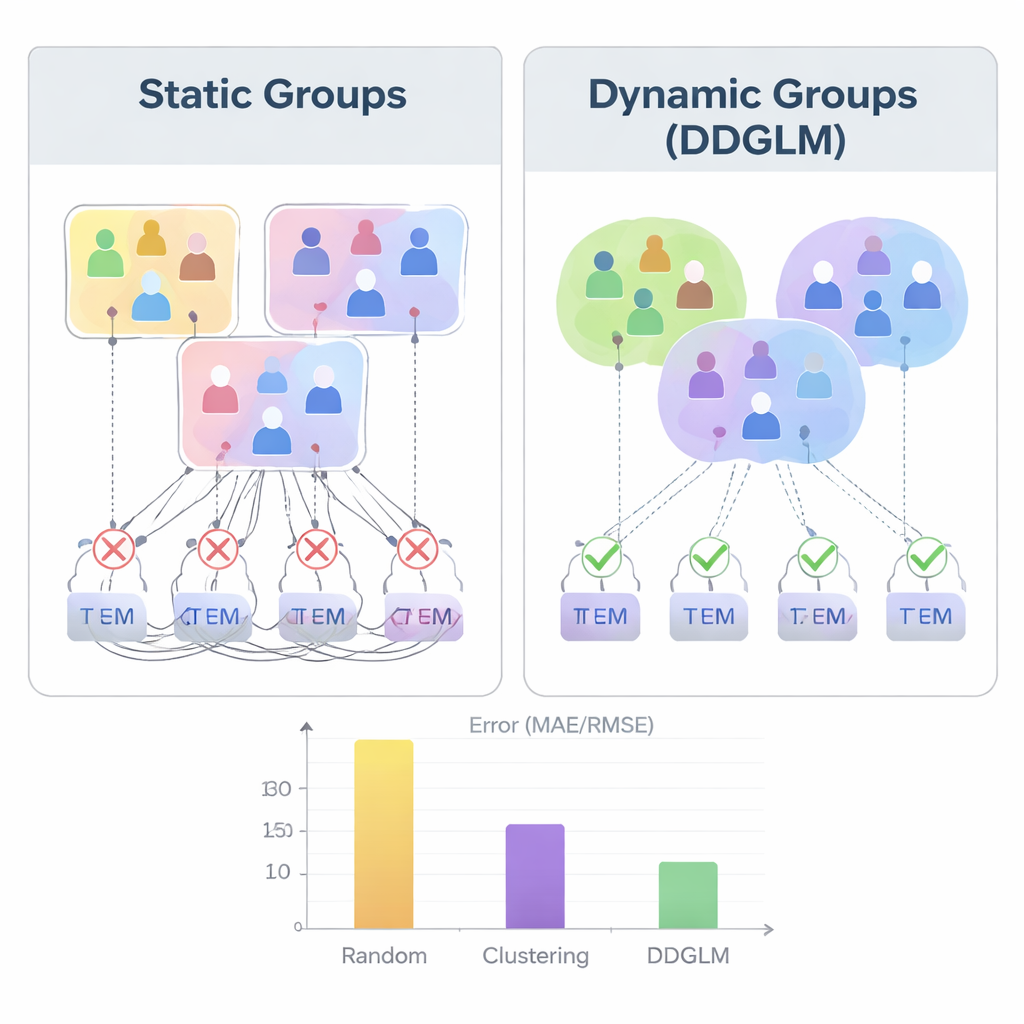
Ce que cela signifie pour les utilisateurs quotidiens
Pour les non‑spécialistes, la conclusion est simple : les systèmes de recommandation s’améliorent quand on leur permet de découvrir des regroupements utiles à la volée, plutôt que d’être liés à des définitions de groupe rigides choisies à l’avance. En apprenant quels utilisateurs et quels éléments ont tendance à aller ensemble dans les données — et en mettant constamment à jour ces schémas — DDGLM peut générer des suggestions qui reflètent mieux les goûts partagés, que ce soit un film pour une famille, une playlist pour une fête, ou un forfait de voyage pour un groupe. L’étude montre que traiter la formation de groupes comme quelque chose que le système peut apprendre conduit à des recommandations plus précises, adaptables et potentiellement plus équitables dans les services numériques que nous utilisons au quotidien.
Citation: Busireddy, N.R., Kagita, V.R. & Kumar, V. Group learning in recommendation systems: towards adaptive and implicit group modeling. Sci Rep 16, 5918 (2026). https://doi.org/10.1038/s41598-026-36356-x
Mots-clés: systèmes de recommandation de groupe, apprentissage dynamique de groupe, recommandations personnalisées, filtrage collaboratif, apprentissage profond