Clear Sky Science · fr
Réseau neuronal profond Inception avec connexions résiduelles pour la reconnaissance des caractères manuscrits tamouls
Conserver l’écriture manuscrite à l’ère numérique
Des anciens manuscrits sur feuilles de palmier aux notes quotidiennes, une grande partie du patrimoine écrit tamoul reste sur papier. Transformer cet ensemble riche de pages manuscrites en texte numérique interrogeable est essentiel pour préserver la culture, soutenir l’éducation et développer de meilleures technologies linguistiques. Cet article présente un nouveau système de vision par ordinateur, appelé TamHNet, qui lit l’écriture manuscrite tamoule avec une précision quasi parfaite, même lorsque certaines lettres se ressemblent de façon trompeuse.
Pourquoi les lettres tamoules posent problème aux ordinateurs
Le tamoul est parlé par plus de 80 millions de personnes et utilise un alphabet de 247 caractères, comprenant voyelles, consonnes et de nombreuses combinaisons des deux. Beaucoup de lettres ne diffèrent que par de minuscules boucles ou des traits supplémentaires, et les rédacteurs varient énormément dans la façon dont ils forment chaque caractère. Des paires comme எ/ஏ ou ஒ/ஓ peuvent paraître presque identiques au premier coup d’œil, et des caractères comme ல et வ peuvent facilement être confondus. Les programmes informatiques antérieurs et même des systèmes d’apprentissage automatique modernes ont souvent peiné sur ces subtilités, entraînant des erreurs de lecture et une numérisation peu fiable des documents.
Constituer un jeu de données manuscrit représentatif
Pour entraîner et évaluer leur système dans des conditions réalistes, les chercheurs ont créé un nouveau jeu de données de caractères isolés tamouls à partir d’échantillons manuscrits recueillis auprès de 1 000 étudiants universitaires. Plutôt que de s’appuyer sur des images synthétiques ou générées par ordinateur, ils ont collecté de vrais caractères écrits au stylo couvrant 12 voyelles, 18 consonnes et 214 combinaisons courantes. L’équipe a soigneusement annoté ces échantillons et rendu le jeu de données public afin que d’autres groupes puissent comparer les méthodes et construire sur ce travail. En organisant l’écriture en 104 symboles de base qui couvrent les 247 caractères, ils ont réduit les redondances tout en représentant l’ensemble des formes apparaissant dans l’écriture manuscrite réelle.
Nettoyer, déformer et enseigner aux images
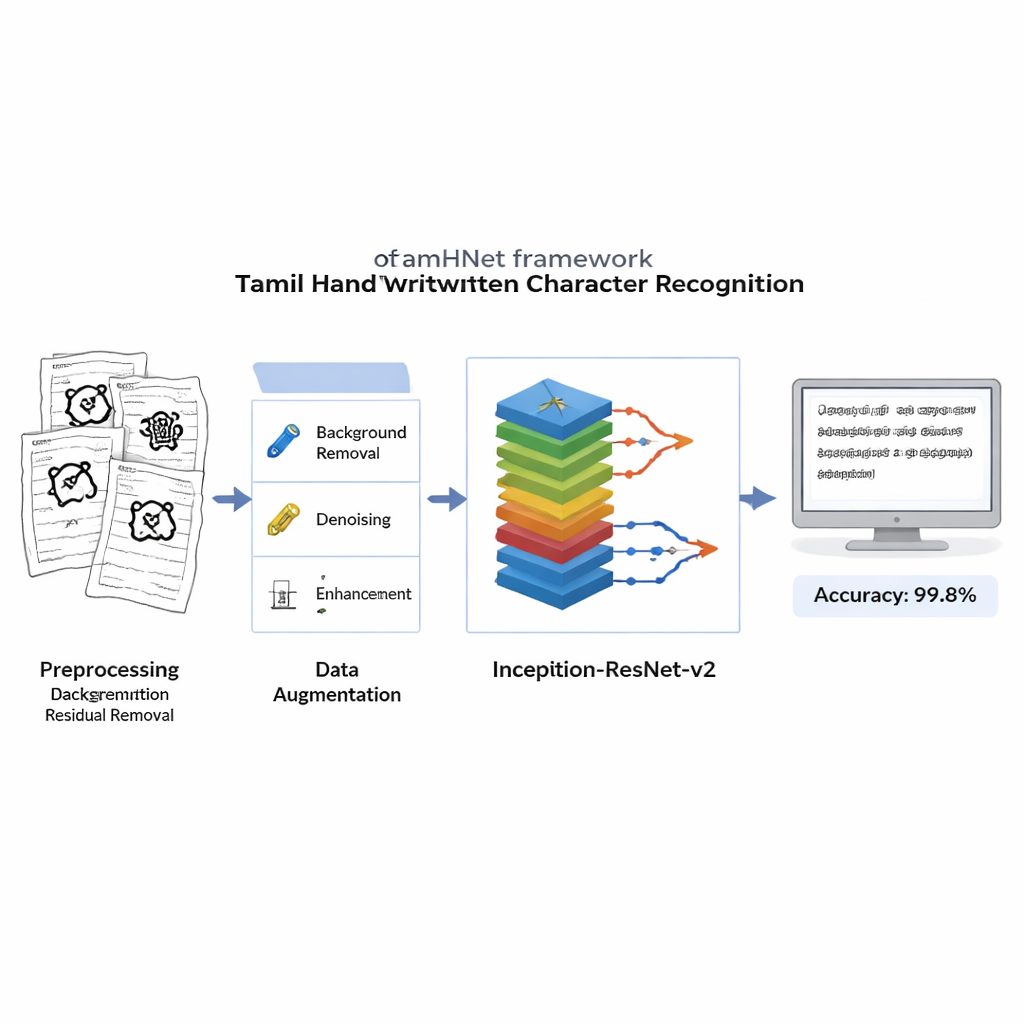
Avant tout apprentissage, chaque image scannée est nettoyée pour éliminer les arrière-plans bruyants, les bavures et l’éclairage inégal tout en préservant les traits délicats qui définissent chaque lettre. Les images sont converties en noir et blanc net et redimensionnées à un format standard afin que l’ordinateur voie chaque exemple de la même manière. Pour rendre le système robuste aux différentes habitudes d’écriture, les auteurs appliquent ensuite des distorsions contrôlées : ils déplacent légèrement des points clés de l’image et appliquent des déformations douces, générant de nouvelles versions de chaque caractère qui restent identifiables pour un humain. Cet ensemble d’entraînement étendu aide le modèle à reconnaître les caractères même lorsqu’ils sont inclinés, compressés ou écrits avec des proportions inhabituelles.
Un réseau profond qui apprend les différences subtiles
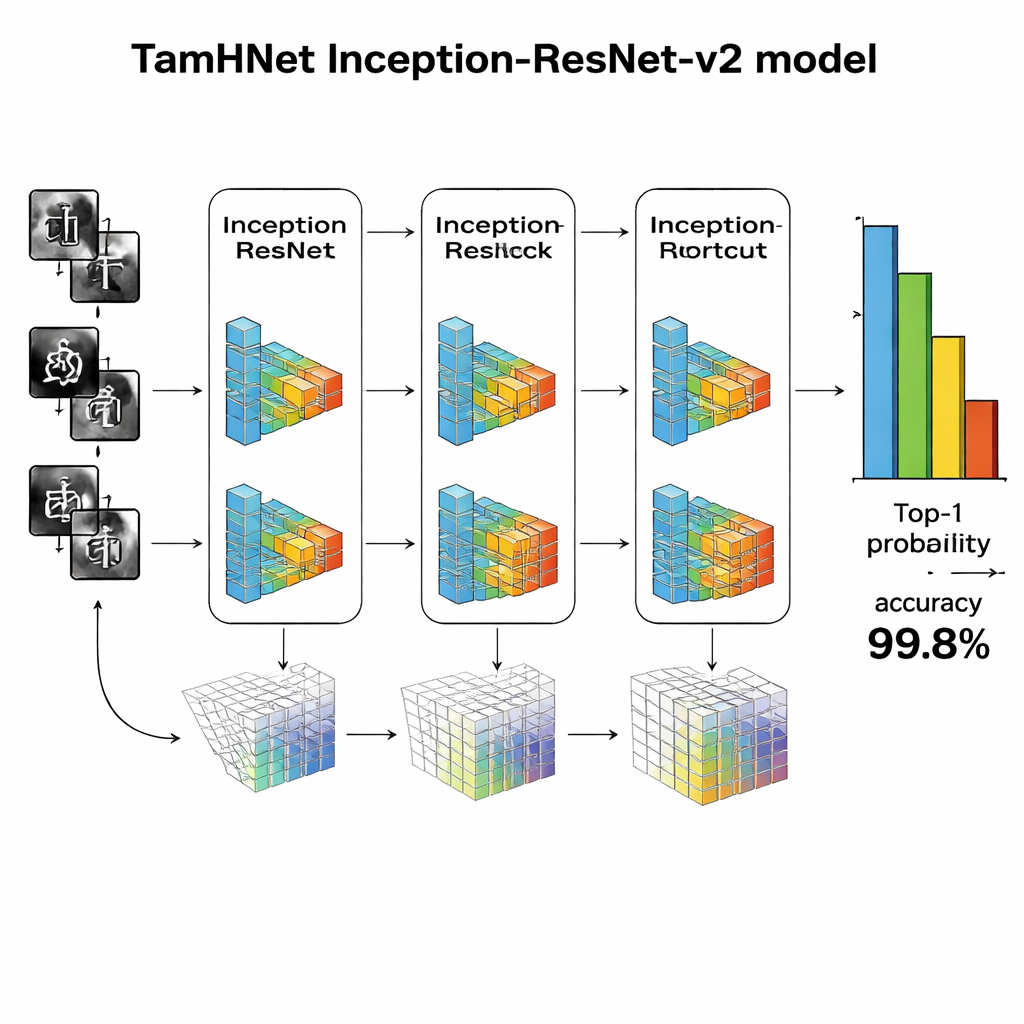
Au cœur de TamHNet se trouve une puissante architecture d’apprentissage profond appelée Inception-ResNet-v2, initialement conçue pour la reconnaissance d’objets généraux. Les auteurs adaptent et ajustent finement ce réseau spécifiquement pour l’écriture tamoule. Le modèle traite chaque image à travers de nombreuses couches qui transforment progressivement les pixels bruts en motifs de plus haut niveau, tels que des arêtes, des courbes et des parties de caractères. Des connexions de raccourci particulières, appelées liens résiduels, stabilisent l’entraînement et aident le réseau à se concentrer sur de petites différences cruciales entre des lettres similaires. Plutôt que d’ajuster tous les paramètres internes d’un coup, l’équipe « dégèle » sélectivement les couches les plus utiles et les met au point pour cette tâche. Ils utilisent une technique d’optimisation appelée Adam, qui adapte automatiquement la vitesse de modification de chaque paramètre, permettant au réseau d’apprendre efficacement à partir d’une écriture complexe et parfois désordonnée.
Quelle est la performance du système pour lire l’écriture manuscrite
Les chercheurs évaluent TamHNet sur le nouveau jeu de données en utilisant des mesures standard de qualité de reconnaissance. Le système atteint environ 99,8 % de précision sur 104 classes de caractères, surpassant une large gamme de méthodes antérieures basées sur les machines à vecteurs de support, les réseaux convolutionnels traditionnels et d’autres architectures avancées d’apprentissage profond. Des tests détaillés montrent que même des lettres aux formes extrêmement proches sont correctement distinguées dans la plupart des cas, et des courbes statistiques confirment que le modèle confond très rarement un caractère avec un autre. Par rapport aux travaux précédents, cela représente un progrès net en termes de fiabilité pour la reconnaissance des caractères manuscrits tamouls.
Ce que cela signifie pour les lecteurs et les archives
Pour les non-spécialistes, l’idée principale est que les ordinateurs deviennent considérablement meilleurs pour lire l’écriture manuscrite tamoule. Un système comme TamHNet peut alimenter des outils qui transforment des piles de cahiers, des manuscrits historiques et des formulaires manuscrits en texte numérique interrogeable avec une correction humaine minimale. Bien que le modèle actuel ne gère pas encore certains symboles à points et des variantes anciennes de l’écriture, les auteurs exposent des plans pour l’étendre aux styles d’écriture anciens. En termes pratiques, cette recherche nous rapproche d’une numérisation à grande échelle et précise des documents tamouls, contribuant à sauvegarder le patrimoine culturel et à faciliter l’accès au savoir écrit pour les générations futures.
Citation: Periyasamy, H., Natarajan, S. & Amirtharajan, R. Deep inception neural network with residual connections for Tamil handwritten character recognition. Sci Rep 16, 6053 (2026). https://doi.org/10.1038/s41598-026-36330-7
Mots-clés: reconnaissance des caractères manuscrits tamouls, reconnaissance optique de caractères, apprentissage profond, Inception-ResNet, préservation numérique