Clear Sky Science · fr
Comparaison des performances des grands modèles de langage dans l’évaluation des connaissances sur la thérapie par capture de neutrons au bore
Tuteurs intelligents pour un nouveau type de radiothérapie contre le cancer
La thérapie par capture de neutrons au bore, ou TCNB, est une forme émergente de traitement par radiation qui vise à détruire les tumeurs tout en épargnant les tissus sains voisins. À mesure que cette thérapie complexe passe des laboratoires de recherche aux hôpitaux, les médecins et les stagiaires doivent maîtriser un grand volume de connaissances spécialisées. Cette étude pose une question d’actualité : les chatbots d’intelligence artificielle populaires peuvent‑ils aider à enseigner et à soutenir la TCNB, et si oui, dans quelle mesure sont‑ils fiables ?
Qu’est‑ce qui distingue la TCNB de la radiothérapie classique ?
La TCNB fonctionne très différemment des traitements standard par rayons X ou protons. Les patients reçoivent des médicaments contenant une forme particulière de bore qui s’accumule à l’intérieur des cellules tumorales. Lorsque ces cellules sont ensuite exposées à un faisceau de neutrons, les atomes de bore subissent une petite réaction nucléaire qui libère des particules à courte portée, tuant la cellule cancéreuse de l’intérieur tout en laissant le tissu adjacent largement indemne. Cette approche hautement ciblée est particulièrement prometteuse pour les tumeurs difficiles à traiter ou pauvres en oxygène. Jusqu’à récemment, la TCNB dépendait de réacteurs nucléaires comme sources de neutrons, ce qui limitait son usage clinique. L’approbation de machines TCNB à base d’accélérateurs au Japon en 2020, et l’ouverture de nouveaux centres dans des pays tels que la Chine, ont transformé la TCNB en une option réaliste pour davantage de patients — et créé un besoin urgent de formation et de certification ciblées.
Mise à l’épreuve de quatre IA de premier plan
Pour évaluer la capacité des chatbots généralistes à traiter des sujets liés à la TCNB, les chercheurs ont construit un test de 47 questions couvrant les notions de base, les recherches récentes, la pratique clinique et des exercices de calcul et de raisonnement. Les questions ont été rédigées en chinois et en anglais et incluaient des faits simples (comme des définitions) ainsi que des problèmes plus exigeants nécessitant du raisonnement ou des calculs numériques. Quatre grandes familles d’IA — représentées par des systèmes largement utilisés de différentes entreprises — ont été testées à travers cinq périodes distinctes, dans deux langues et selon deux modalités d’interrogation (questions directes simples et questions intégrées dans un court scénario clinique). Des spécialistes des soins oncologiques ont noté chaque réponse selon une grille de référence, et l’équipe a aussi suivi la fréquence à laquelle les IA reconnaissaient leur incertitude en disant par exemple « je ne sais pas ».
Qui a le mieux répondu, et sur quels types de questions ?
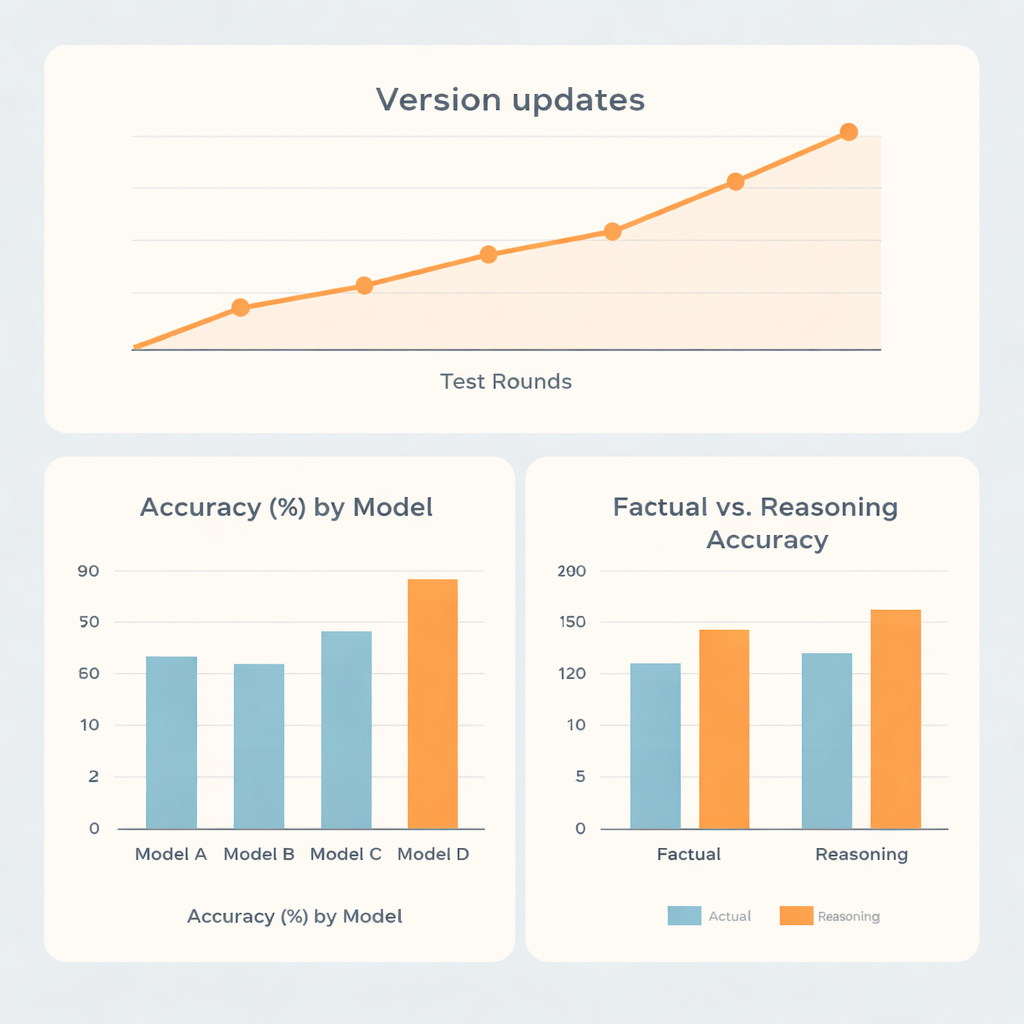
Globalement, deux familles de modèles ont clairement surpassé les deux autres. Le système le plus performant a atteint environ 73 % de bonnes réponses, le second environ 70 %, tandis que les modèles restants affichaient des scores proches de 62 % et 56 %. Fait intéressant, les meilleurs ne se contentaient pas d’exceller sur des faits mémorisés. Ils ont montré une supériorité marquée sur les questions nécessitant du raisonnement, plutôt que sur le rappel pur d’informations, ce qui suggère que ces systèmes sont relativement forts pour des tâches de réflexion en plusieurs étapes, comme des calculs de dose ou des problèmes de type planification, dans ce domaine médical restreint. Un modèle présentait des scores presque identiques pour les items factuels et de raisonnement, tandis qu’un autre restait en retrait globalement malgré de meilleures performances relatives sur le raisonnement que sur les faits.
Mises à jour, langues et propension à dire « je ne sais pas »
Étant donné que les systèmes d’IA évoluent fréquemment, les chercheurs ont aussi examiné l’évolution des performances sur cinq sessions de test réparties de la fin 2023 à la mi‑2025. Les mises à jour majeures entraînaient généralement des sauts nets de précision, alors que des ajustements mineurs au sein d’une même version avaient peu d’effet. Une famille de modèles est passée de moins de 60 % à plus de 80 % de précision au fil du temps, soulignant la rapidité des progrès technologiques. De façon surprenante, la langue utilisée (chinois ou anglais) ou la forme de la question (directe ou intégrée dans un rôle) n’avaient que de faibles effets comparés aux forces intrinsèques de chaque modèle. Plus marquantes étaient les différences dans la façon dont les systèmes faisaient preuve de franchise lorsqu’ils se trompaient. Certains modèles reconnaissaient leur incertitude dans près d’une erreur sur cinq, tandis qu’un autre le faisait rarement, offrant souvent des réponses assurées mais erronées.
Ce que cela signifie pour les médecins, les étudiants et les patients
L’étude conclut que les meilleurs chatbots généralistes actuels peuvent déjà fournir des explications et des exercices raisonnablement précis sur la TCNB, ce qui en fait des aides prometteuses pour l’éducation et l’auto‑apprentissage. Cependant, aucun de ces systèmes ne peut encore être totalement fiable pour répondre correctement à toutes les questions sur la TCNB, et leurs manières d’exprimer — ou de dissimuler — l’incertitude varient d’une façon qui a des conséquences pour la sécurité. Pour l’instant, ces outils doivent être considérés comme des assistants intelligents susceptibles de soutenir, mais pas de remplacer, le jugement d’experts. Les auteurs soutiennent que des modèles d’IA spécifiquement dédiés à la TCNB, accompagnés de normes claires sur l’utilisation de tels outils en clinique et en formation, seront nécessaires avant que l’IA puisse jouer un rôle de premier plan et fiable dans cette forme hautement spécialisée de prise en charge du cancer.
Citation: Shen, S., Wang, S., Gao, M. et al. Performance comparison of large language models in boron neutron capture therapy knowledge assessment. Sci Rep 16, 5321 (2026). https://doi.org/10.1038/s41598-026-36322-7
Mots-clés: thérapie par capture de neutrons au bore, radiothérapie du cancer, éducation médicale, intelligence artificielle, grands modèles de langage