Clear Sky Science · fr
Pré‑entraînement contrastif langage-image guidé par l’objet pour la reconnaissance zéro‑exemple
Des yeux plus fins pour des cieux et des mers encombrés
Les systèmes modernes de sécurité et d’intervention en cas de catastrophe s’appuient sur des caméras dans le ciel et en mer pour repérer avions, navires et autres objets critiques. Mais apprendre à un ordinateur à distinguer un avion de chasse d’un avion de ligne, ou un navire militaire d’un cargo, est étonnamment difficile lorsque les scènes sont encombrées, les données rares et de nouveaux modèles d’équipements apparaissent sans cesse. Cet article présente OG‑CLIP, un nouveau système d’IA conçu pour reconnaître des cibles militaires et civiles sur lesquelles il n’a jamais été explicitement entraîné, en combinant des connaissances à grande échelle avec une focalisation visuelle plus précise sur les objets qui comptent.
Pourquoi l’IA traditionnelle manque la cible
La plupart des systèmes de reconnaissance d’images apprennent à partir d’énormes collections de photos annotées : chaque image est liée à une liste fixe de catégories, comme « chat » ou « voiture ». Cette approche montre ses limites dans des domaines spécialisés comme la défense et la télédétection, où les données sont sensibles, l’annotation exige des experts et la diversité des équipements est immense. Les modèles vision‑langage plus récents, comme CLIP, associent images et courtes légendes récupérées sur le web, ce qui leur permet de reconnaître de nouveaux concepts décrits par des mots. Pourtant, dans l’imagerie militaire, ces modèles peinent encore : les légendes sont souvent vagues, l’arrière‑plan (nuages, vagues) domine les pixels, et leurs représentations internes ne sont pas suffisamment flexibles pour s’exécuter efficacement aussi bien sur de petits drones que sur des serveurs puissants. OG‑CLIP s’attaque frontalement à ces trois problèmes.
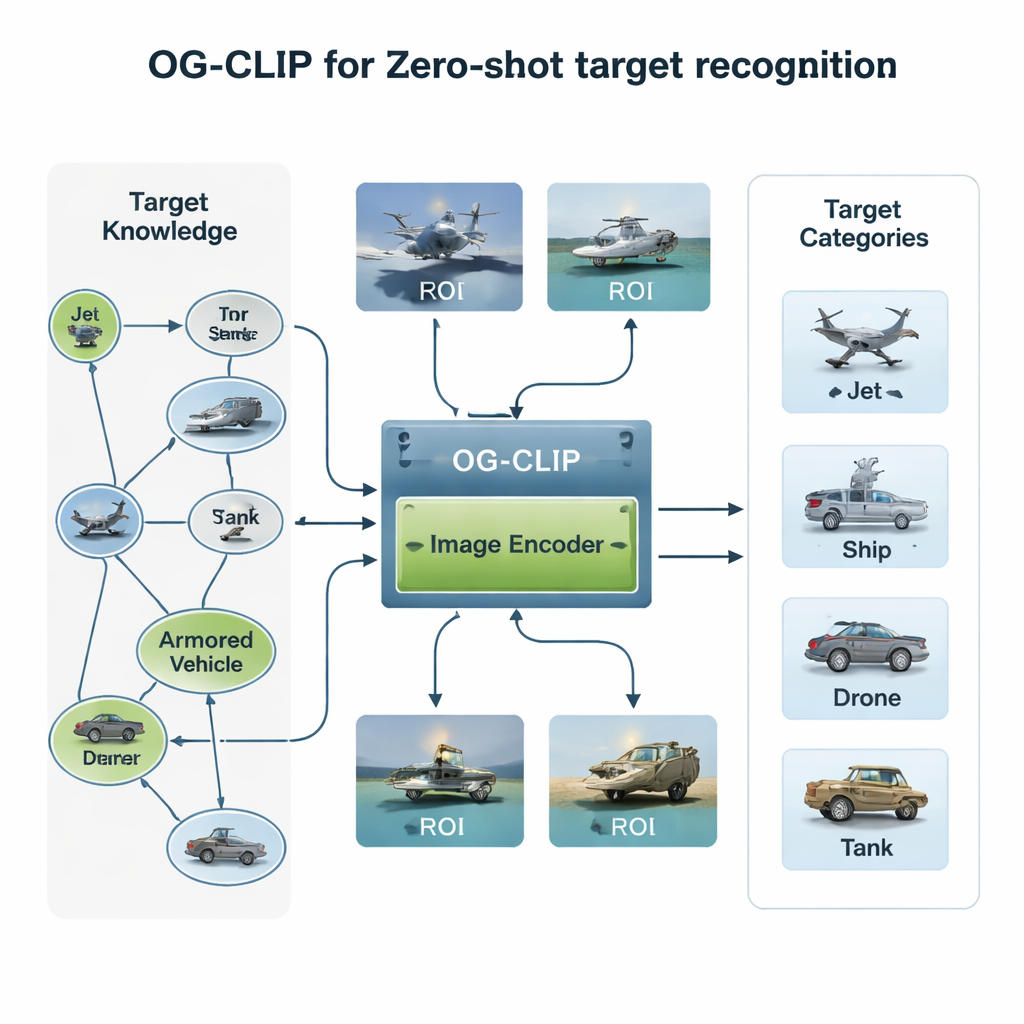
Construire un univers d’entraînement riche en connaissances
Le premier ingrédient d’OG‑CLIP est un univers d’entraînement soigneusement conçu. Les auteurs ont assemblé une base de données de 5 000 types de cibles — allant de chasseurs et bombardiers à des bâtiments de guerre et des avions civils — et les ont organisés dans un graphe de connaissances détaillé. Chaque entrée comprend des faits structurés tels que l’envergure, le poids et la configuration d’armement, tirés de références de défense publiques, d’encyclopédies et de documents techniques. Ils ont ensuite collecté environ un million d’images à partir de jeux de données publics, de recherches web, d’archives internes anciennes et même de scènes simulées par des moteurs de jeu. Pour garantir la fiabilité des données, ils ont groupé les images à l’aide d’un modèle existant pour repérer les valeurs atypiques, procédé à une revue experte et filtré les mauvaises annotations. Enfin, ils ont utilisé des outils avancés vision‑langage pour transformer le graphe de connaissances en descriptions en langage naturel riches pour chaque image, de sorte que le système n’apprenne pas seulement « ceci est un jet », mais « un avion monocouloir avec des ailettes orientées vers le haut » ou « un bombardier furtif de type aile volante ».
Apprendre au modèle à ignorer le bruit
La deuxième innovation réside dans l’endroit où le modèle regarde. Dans de nombreuses images satellite ou aériennes, le navire ou l’avion réel occupe seulement une petite portion de l’image, entouré d’un ciel, d’une mer ou d’un terrain distrayant. OG‑CLIP ajoute un module de région d’intérêt (ROI) qui imite la façon dont un humain balaierait l’image pour se concentrer sur l’objet clé plutôt que sur le cadre entier. Un outil de segmentation à la pointe identifie automatiquement les objets probables dans l’image, produisant des masques souples qui mettent en valeur la cible et atténuent l’arrière‑plan. Ces masques sont injectés, conjointement avec l’image d’origine, dans l’ossature visuelle du modèle, de sorte que son attention se concentre naturellement sur des caractéristiques distinctives comme la forme des ailes, la configuration du pont ou la silhouette de la coque. Ce design en plug‑in peut être ajouté à des systèmes existants sans réécrire leur architecture centrale, leur offrant un regard plus « guidé par l’objet ».

Adapter le niveau de détail au matériel
Le troisième élément répond à une préoccupation pratique mais cruciale : tous les appareils ne peuvent pas se permettre le même niveau de détail. Une station sol satellite peut traiter des caractéristiques riches et de haute dimension, tandis qu’un petit drone a besoin de calculs plus rapides et plus légers. Les méthodes traditionnelles fixent une taille de représentation unique, ou entraînent plusieurs modèles séparés pour différentes tailles. OG‑CLIP utilise à la place une représentation de type « Matriochka », empaquetant l’information à plusieurs niveaux de détail dans un seul vecteur, comme des poupées imbriquées. Le système peut découper des portions plus courtes ou plus longues de ce vecteur — descriptions plus grossières ou plus fines de ce qui se trouve sur l’image — sans réentraînement. Un mécanisme de pondération incite chaque niveau à conserver l’information la plus utile pour la classification, et un terme de perte additionnel pousse les niveaux à rester sémantiquement cohérents entre eux.
Que vaut‑il en pratique ?
Pour évaluer OG‑CLIP, les chercheurs ont construit un ensemble de test exigeant de 99 catégories de cibles, incluant 51 types d’avions militaires, 29 types de bâtiments de guerre et 19 cibles civiles ou mixtes. De manière cruciale, aucune de ces catégories n’apparaît dans les données d’entraînement, si bien que le système doit s’appuyer sur sa compréhension apprise du langage et des motifs visuels — un test « zéro‑exemple ». Par rapport à plusieurs solides bases CLIP, OG‑CLIP a amélioré l’exactitude moyenne de plus de 11 points de pourcentage, atteignant 84,28 % au global. Il s’est montré particulièrement performant sur des scènes encombrées et complexes et sur les distinctions fines entre modèles proches, comme différents chasseurs, où le module ROI et les descriptions riches issues du graphe de connaissances lui ont donné un avantage net. Des études d’ablation ont montré que chaque composant — les données du graphe de connaissances, la focalisation ROI et les représentations adaptatives — apportait des gains mesurables.
Ce que cela signifie pour la surveillance en conditions réelles
Pour les non‑spécialistes, la conclusion principale est qu’OG‑CLIP constitue une avancée vers des systèmes de sécurité et de surveillance capables de reconnaître plus fiablement des avions et navires inconnus à partir d’images du monde réel, même lorsque les exemples annotés sont rares. En combinant des connaissances expertes structurées, une focalisation automatique sur l’objet d’intérêt et des niveaux de détail ajustables, l’approche rend l’IA vision‑langage à la fois plus intelligente et plus pratique. Au‑delà de la défense, des idées similaires pourraient aider la surveillance environnementale, la réponse aux catastrophes et l’inspection industrielle à interpréter des scènes complexes tout en s’exécutant sur une large gamme de matériels.
Citation: Zheng, C. Object-guided contrastive language-image pre-training for zero-shot target recognition. Sci Rep 16, 6425 (2026). https://doi.org/10.1038/s41598-026-36314-7
Mots-clés: reconnaissance zéro‑exemple, modèles vision‑langage, détection d’objet, télédétection, graphes de connaissances