Clear Sky Science · fr
Transformers d’apprentissage profond basés sur la perception visuelle pour classer peintures et photographies via l’extraction de caractéristiques
Pourquoi c’est important pour les images du quotidien
À une époque où n’importe qui peut générer une image réaliste en quelques clics, il devient plus difficile de distinguer si une image est une photographie réelle, une peinture traditionnelle ou quelque chose créé entièrement par des algorithmes. Cette étude explore comment l’intelligence artificielle moderne peut automatiquement différencier les peintures réalisées par des humains des photos prises par caméra, et même des images générées par IA, aidant ainsi à protéger les marchés de l’art, les archives et les utilisateurs en ligne contre la confusion et la contrefaçon.
L’art, la photo et l’essor des images fabriquées par des machines
Peintures et photographies peuvent paraître similaires au premier abord à l’écran, mais elles portent des empreintes visuelles très différentes. Les peintures montrent souvent des coups de pinceau visibles, des couleurs stylisées et des compositions plus abstraites, tandis que les photographies contiennent généralement des détails plus nets et un éclairage naturel. Parallèlement, les nouveaux générateurs d’images produisent des œuvres imitant de mieux en mieux les deux médias. Musées, galeries, collectionneurs et plateformes numériques ont de plus en plus besoin d’outils capables de déterminer rapidement et de manière fiable le type d’image traité, à la fois pour authentifier les œuvres et pour gérer l’afflux de contenu synthétique.
Un nouveau pipeline pour apprendre aux machines à voir
Les chercheurs ont construit un pipeline complet d’analyse d’images basé sur un Vision Transformer, un modèle d’apprentissage profond récent initialement développé pour le traitement du langage et désormais adapté aux images. Ils ont entraîné ce système sur un jeu de données public Kaggle contenant 1 361 peintures et 3 747 photographies, représentant une grande variété de scènes et de styles. Chaque image est d’abord standardisée : elle est redimensionnée, légèrement recadrée, puis augmentée par des retournements, de petites rotations, des modifications de luminosité et une réduction du bruit afin que le modèle voie de nombreuses variations réalistes. Après cette préparation, le Vision Transformer divise chaque image en petits patchs et apprend comment les différentes parties de l’image se rapportent les unes aux autres à l’échelle du cadre. 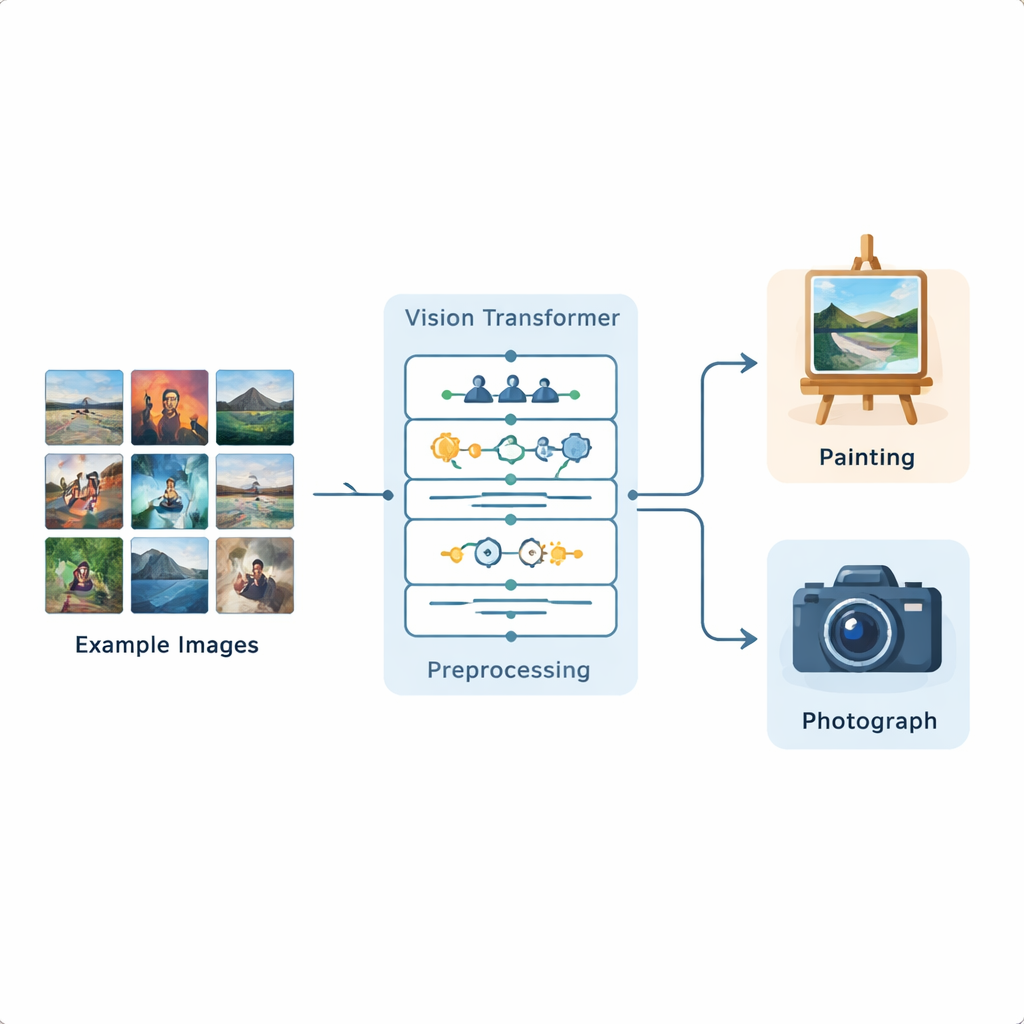
Comment le modèle se concentre sur les bons détails
Contrairement aux réseaux neuronaux antérieurs qui examinaient surtout des motifs locaux, le Vision Transformer utilise un mécanisme d’« attention » pour décider quelles parties d’une image importent le plus pour la tâche. Il s’interroge, pour chaque patch, sur l’importance à accorder à tous les autres patchs. Cela lui permet de mieux percevoir la structure globale : la manière dont les couleurs se déploient sur une toile, comment la lumière tombe dans une scène, ou comment les textures se répètent. Pour vérifier que le modèle ne devine pas au hasard, les auteurs appliquent également une méthode de visualisation appelée Grad-CAM, qui met en évidence les régions spécifiques ayant influencé chaque décision. Pour les peintures, ces mises en évidence se situent souvent sur les textures des coups de pinceau et les zones stylisées ; pour les photographies, elles se concentrent autour des contours fins, des surfaces réalistes et des transitions d’éclairage. 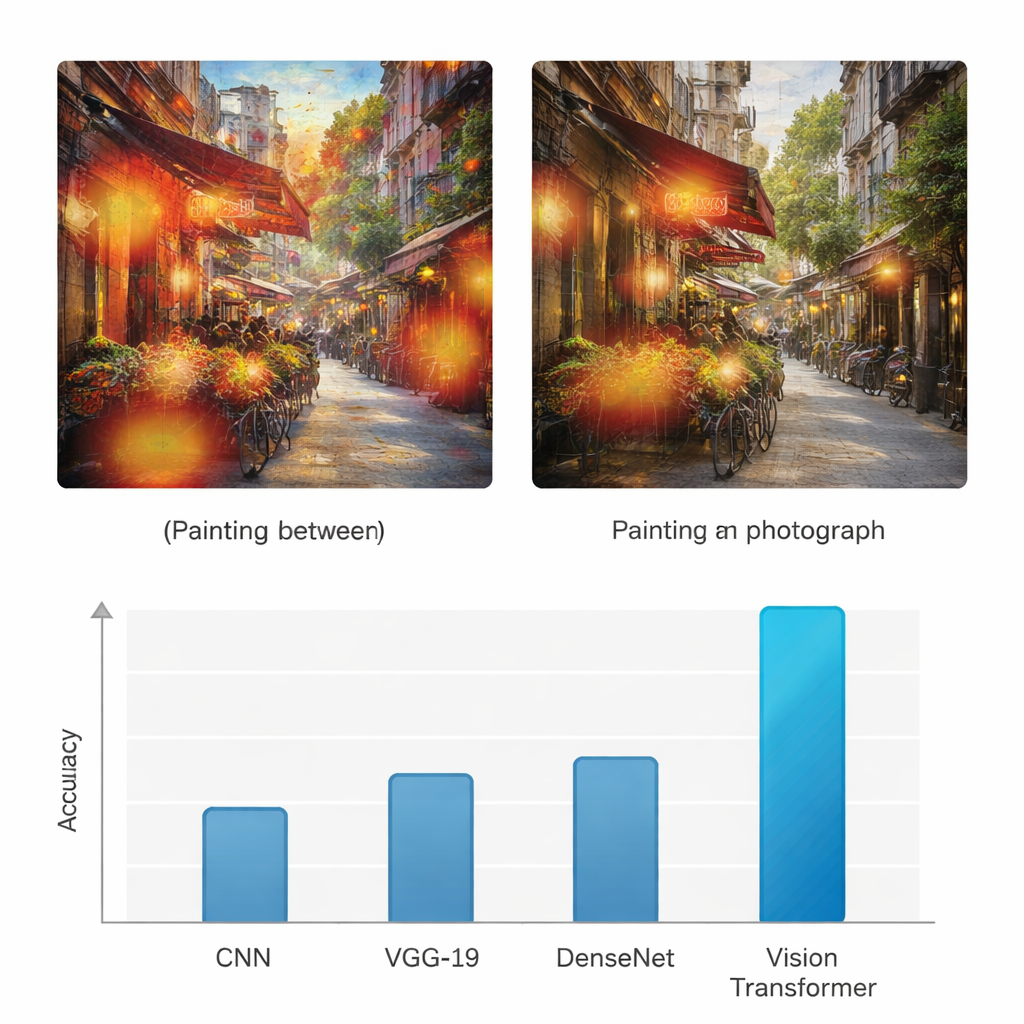
Surpasser les méthodes de reconnaissance d’images antérieures
Pour évaluer si cette approche apporte réellement une valeur ajoutée, l’étude compare le Vision Transformer à trois architectures d’apprentissage profond largement utilisées : un réseau neuronal convolutionnel standard (CNN), le réseau VGG-19 et DenseNet. Tous les modèles sont entraînés et testés sur le même ensemble de données, et évalués avec des mesures courantes telles que la précision, la précision prédictive, le rappel et le score F1, qui équilibrent détections correctes et erreurs pour les deux classes. Alors que les réseaux de référence atteignent des précisions dans une fourchette allant du milieu des 70 % au milieu des 80 %, le Vision Transformer obtient une précision de 95 % pour les peintures et les photographies, avec des valeurs de précision et de rappel également élevées. Les auteurs réalisent en outre plusieurs tests statistiques pour confirmer que cette amélioration n’est pas due au hasard, montrant que le modèle basé sur le transformer est de manière fiable supérieur sur des essais répétés et selon différents critères d’évaluation.
Ce que cela signifie pour l’art, la confiance et la technologie
Les résultats suggèrent que les modèles transformer modernes peuvent servir d’outils puissants et expliquables pour séparer peintures et photographies et pour signaler les images générées par IA qui imitent l’un ou l’autre médium. Pour les non-spécialistes, la conclusion est que les ordinateurs peuvent désormais détecter des indices subtils — tels que la facture du pinceau, la douceur ou les gradients d’éclairage — que même des observateurs humains attentifs pourraient manquer, et ce à grande échelle. De tels systèmes pourraient aider les galeries et les collectionneurs à vérifier des œuvres, assister conservateurs et archivistes dans l’organisation de vastes collections numériques, et soutenir les plateformes en ligne dans l’étiquetage ou le filtrage du contenu synthétique. À mesure que les générateurs d’images brouillent la frontière entre réalité et invention, des méthodes comme celle présentée ici offrent un moyen pratique de maintenir la confiance dans ce que nous voyons.
Citation: Yu, L. Visual perception based deep learning transformers for classifying paintings and photographs through feature extraction. Sci Rep 16, 5326 (2026). https://doi.org/10.1038/s41598-026-36298-4
Mots-clés: images générées par IA, authentification d’art, classification d’images, vision transformer, analyse de l’art numérique