Clear Sky Science · fr
Apprentissage méta pour la reconnaissance de tâches ouvertes avec peu d’exemples
Pourquoi enseigner à l’IA avec très peu d’exemples importe
Les systèmes d’IA modernes peuvent reconnaître des visages, des animaux et des objets du quotidien avec une précision remarquable — mais généralement seulement après avoir vu des millions d’images étiquetées. Dans de nombreuses situations réelles, comme diagnostiquer une maladie rare ou repérer un nouveau type de défaut sur une chaîne de fabrication, nous ne disposons tout simplement pas d’autant de données. Cet article explore comment entraîner des modèles d’IA capables d’apprendre de nouvelles tâches visuelles à partir d’une poignée d’exemples, même lorsque ces tâches sont très différentes de ce sur quoi le modèle a été entraîné. Il présente une méthode appelée Open-MAML qui vise à rendre ce type d’apprentissage flexible et peu gourmand en données plus fiable et prévisible.
Des exercices fixes en classe aux contrôles surprises ouverts
La plupart des recherches sur le « few-shot learning » évaluent les systèmes d’IA dans des conditions très contrôlées. Le modèle est entraîné et testé sur des tâches très similaires, par exemple en devant toujours distinguer exactement cinq catégories (appelé « 5-way ») avec un exemple par catégorie (« 1-shot »). C’est comme n’entraîner un élève qu’avec des quiz de cinq questions et un exemple d’entraînement par type de question. Les déploiements réels sont bien plus désordonnés : le nombre de catégories peut varier, et la quantité de données étiquetées pour chacune peut augmenter ou diminuer dans le temps. Les auteurs appellent cette situation plus réaliste le cadre de la tâche ouverte, où les modèles doivent traiter des tâches avec un nombre de classes et d’exemples différent de ce qu’ils ont vu pendant l’entraînement. 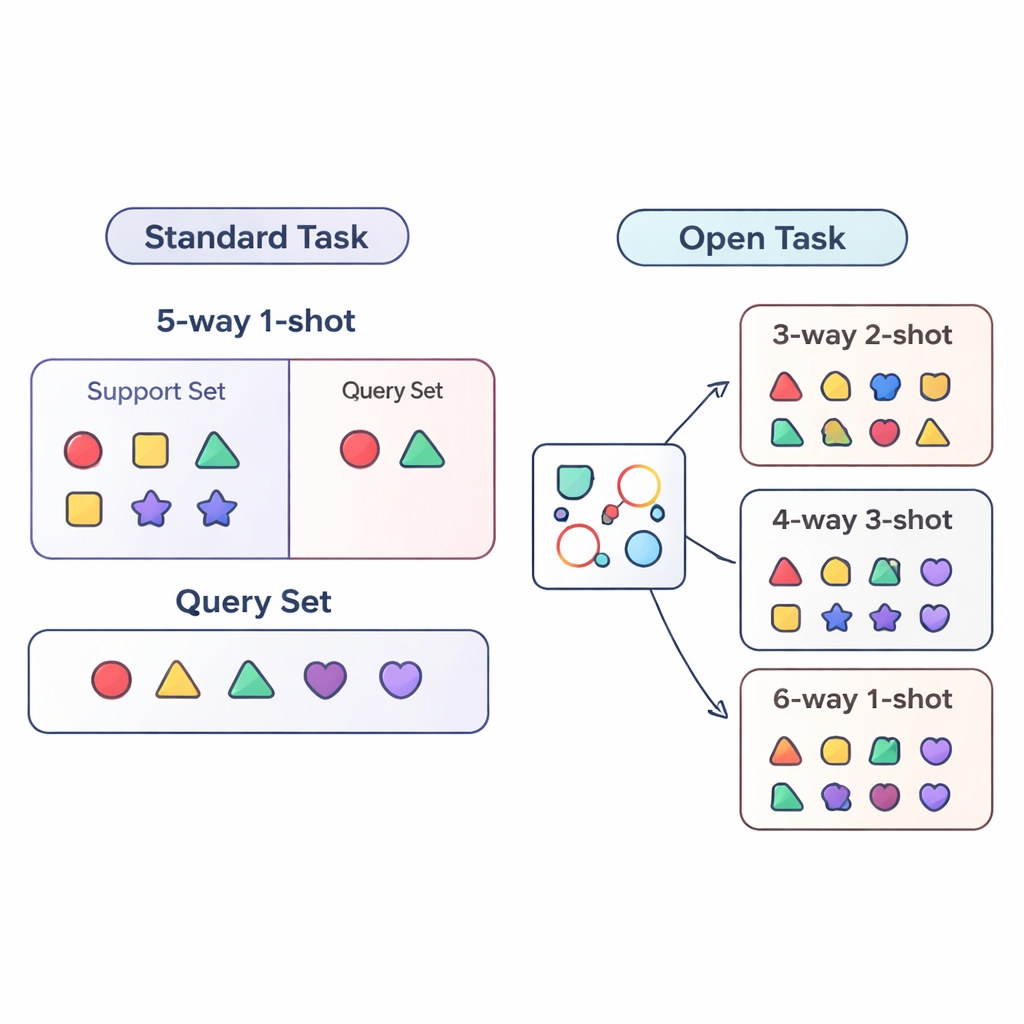
Redéfinir la façon dont nous testons les apprenants à peu d’exemples
Pour étudier ce monde de tâches ouvertes de manière systématique, l’article propose trois régimes d’évaluation. Dans le régime cross-way, seul le nombre de classes change : le modèle peut être entraîné sur cinq classes mais testé sur trois ou quinze. Dans le régime cross-shot, le nombre d’exemples par classe varie, d’une seule image étiquetée à plusieurs. Le cas le plus difficile est cross-way–cross-shot, où le nombre de classes et la quantité de données par classe changent simultanément. Les auteurs examinent également ce qui se passe lorsque le style visuel des données change, en entraînant sur un jeu de données d’objets générique et en testant sur un jeu d’oiseaux à discrimination fine. Ces configurations sont conçues pour révéler si une méthode peut réellement généraliser au-delà d’une seule recette d’entraînement fixe.
Comment Open-MAML s’adapte en temps réel
Open-MAML s’appuie sur une stratégie de méta-apprentissage populaire appelée Model-Agnostic Meta-Learning (MAML), qui entraîne un modèle pour qu’il puisse s’adapter rapidement à une nouvelle tâche en quelques pas de gradient. Le MAML standard, toutefois, suppose que le nombre de catégories au moment du test correspond à celui de l’entraînement et utilise une couche de classification finale fixe. Open-MAML introduit trois ajustements clés pour briser cette limitation. Premièrement, il utilise la construction dynamique du classifieur : lorsqu’une nouvelle tâche comporte plus de classes qu’auparavant, il crée des unités de sortie supplémentaires en copiant la moyenne des unités existantes, offrant au modèle un point de départ neutre mais pertinent. Deuxièmement, il ajuste le taux d’apprentissage interne en fonction du nombre de classes et d’exemples de la tâche, de sorte que l’adaptation reste stable que les données soient rares ou abondantes. Troisièmement, il ajoute un régularisateur appelé AdaDropBlock qui masque temporairement des régions contiguës dans les cartes de caractéristiques pendant l’entraînement, incitant le modèle à utiliser des indices visuels plus divers plutôt que de surajuster des détails fragiles et limités. 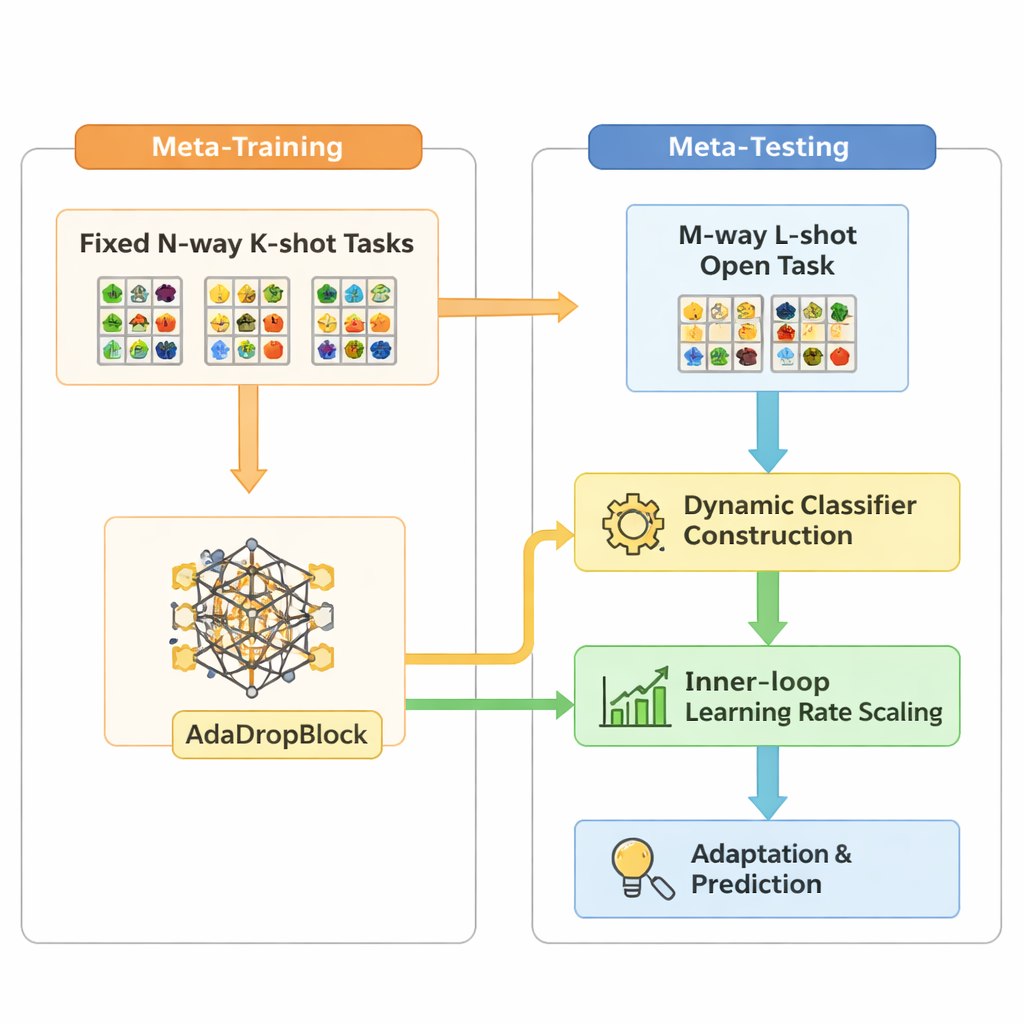
Mettre l’apprentissage flexible à l’épreuve
Les chercheurs évaluent Open-MAML sur des bancs d’essai classiques de few-shot et dans les nouveaux scénarios de tâche ouverte, en le comparant à plusieurs références bien connues. Celles-ci incluent des modèles entraînés de zéro pour chaque tâche, des modèles utilisant un extracteur de caractéristiques pré-entraîné solide plus un classifieur affiné, et des méthodes basées sur des métriques qui classent les images selon leur distance aux « prototypes » de classe. Toutes les méthodes partagent le même réseau de base afin que les différences proviennent de la stratégie d’apprentissage et non de l’architecture. Sur des dizaines de milliers de tâches de test, Open-MAML obtient systématiquement une précision supérieure — typiquement de 1 à 7 points de pourcentage en mieux lorsque seul le nombre de classes ou d’exemples change, et de 3 à 6 points en mieux lorsque les deux varient. Les gains sont encore plus marqués dans les scénarios plus difficiles avec davantage de classes, plus de shots, ou un passage au jeu d’oiseaux, ce qui suggère que ses mécanismes d’adaptation aident réellement dans des territoires complexes et inconnus.
Ce que cela signifie pour les systèmes d’IA du monde réel
Pour un lecteur général, le message principal est que tous les apprenants à peu d’exemples ne se valent pas une fois que l’on quitte la zone de confort du laboratoire. Une méthode qui brille sur un seul benchmark fixe peut trébucher lorsque le nombre de catégories ou la quantité de données étiquetées change. Open-MAML montre qu’en anticipant explicitement de tels changements structurels — en laissant le classifieur grandir ou rétrécir, en adaptant le taux d’apprentissage à la taille de la tâche et en régularisant les caractéristiques de façon indépendante de la tâche — les systèmes d’IA peuvent mieux faire face aux conditions changeantes qu’ils rencontreront en pratique. Dans des contextes comme l’imagerie médicale, la surveillance satellite ou l’inspection industrielle, où à la fois l’ensemble des catégories et la disponibilité des étiquettes sont en flux constant, cette robustesse aux tâches ouvertes pourrait rendre le few-shot learning bien plus utilisable en dehors des bancs d’essai soigneusement sélectionnés de la recherche.
Citation: Han, X., Shi, D., Wang, Z. et al. Meta-learning for few-shot open task recognition. Sci Rep 16, 5624 (2026). https://doi.org/10.1038/s41598-026-36291-x
Mots-clés: apprentissage par peu d’exemples, méta-apprentissage, reconnaissance de tâches ouvertes, classification d’images, généralisation