Clear Sky Science · fr
IASUNet : extraction de bâtiments basée sur Swin-UperNet à attention améliorée
Pourquoi repérer chaque bâtiment depuis l’espace est important
À mesure que les villes s’étendent et que le climat évolue, savoir précisément où se trouvent les bâtiments — et comment ils changent au fil du temps — est devenu essentiel. De la planification de quartiers plus sûrs et du suivi de constructions illégales à l’orientation des opérations de secours après des inondations ou des séismes, des cartes détaillées des bâtiments sont désormais un ingrédient central des villes intelligentes et résilientes. Cet article présente IASUNet, un nouveau système d’intelligence artificielle qui apprend à repérer automatiquement les bâtiments dans des images satellite à haute résolution avec une précision remarquable, même dans des scènes réelles encombrées et complexes.
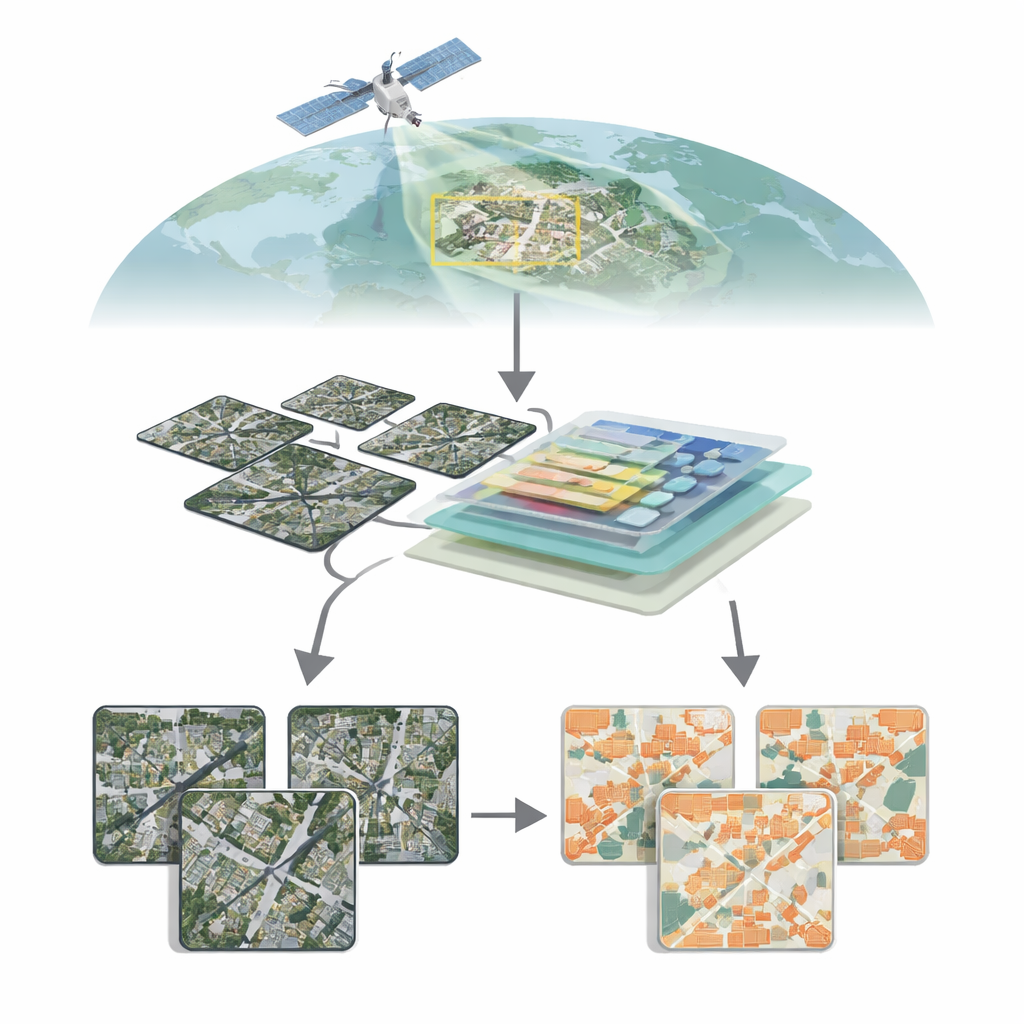
Voir les villes depuis le ciel
Les satellites modernes peuvent photographier la Terre avec un niveau de détail extraordinaire, révélant toitures individuelles, routes et même ruelles étroites. Transformer cette mer de pixels en cartes nettes de bâtiments reste cependant loin d’être trivial. Les bâtiments varient énormément en taille, forme, couleur et environnement : tours de verre au centre-ville, maisons basses en banlieue, bâtiments agricoles dispersés à la campagne. Dans les zones rurales ou mixtes, les bâtiments peuvent n’occuper qu’une fraction infime de chaque image, tandis que la végétation, le sol et l’eau dominent. Les méthodes traditionnelles de vision par ordinateur, basées principalement sur des réseaux de neurones convolutionnels, peinent parfois à saisir le panorama global d’une scène tout en respectant des contours fins, ce qui conduit à manquer de petites structures ou à obtenir des bords flous.
Une attention plus intelligente aux détails
IASUNet relève ces défis en combinant deux idées puissantes : un encodeur basé sur Transformer appelé Swin Transformer, et un décodeur flexible connu sous le nom d’UperNet. Le Swin Transformer découpe une image en nombreux petits patchs et apprend comment ils se relient à travers l’ensemble de la scène, plutôt que de ne regarder qu’à l’intérieur d’une fenêtre de taille fixe. Cela aide le modèle à comprendre le contexte plus large — par exemple si un rectangle lumineux se situe à l’intérieur d’un îlot urbain dense ou au milieu d’un champ isolé — tout en conservant le détail. En complément, les auteurs intègrent à plusieurs stades un mécanisme d’attention appelé Convolutional Block Attention Module (CBAM). Le CBAM apprend, canal par canal et région par région, quelles caractéristiques de l’image sont les plus susceptibles d’appartenir à des bâtiments et lesquelles constituent du bruit de fond, renforçant les premières et supprimant les secondes avant que le décodeur ne recompose la carte complète des bâtiments.
Rééquilibrer les chances quand les bâtiments sont rares
Un autre obstacle pratique est le déséquilibre : dans de nombreuses scènes satellite, la plupart des pixels représentent des routes, des champs, des arbres ou de l’eau, tandis que les bâtiments forment de petites îles. Les méthodes d’entraînement standard ont tendance à privilégier ce qui apparaît le plus souvent, ce qui risque d’apprendre à un modèle à traiter les bâtiments moins fréquents comme des détails secondaires. Pour contrer cela, les auteurs adaptent une fonction de perte appelée Focal Cross‑Entropy. Cette stratégie réduit l’influence des pixels « faciles » d’arrière‑plan et amplifie l’impact des pixels de bâtiments difficiles à classer lors de l’entraînement. En conséquence, le modèle accorde une attention supplémentaire aux structures petites, faibles ou atypiques qui pourraient autrement être négligées, améliorant le rappel sans noyer la carte de fausses alertes.
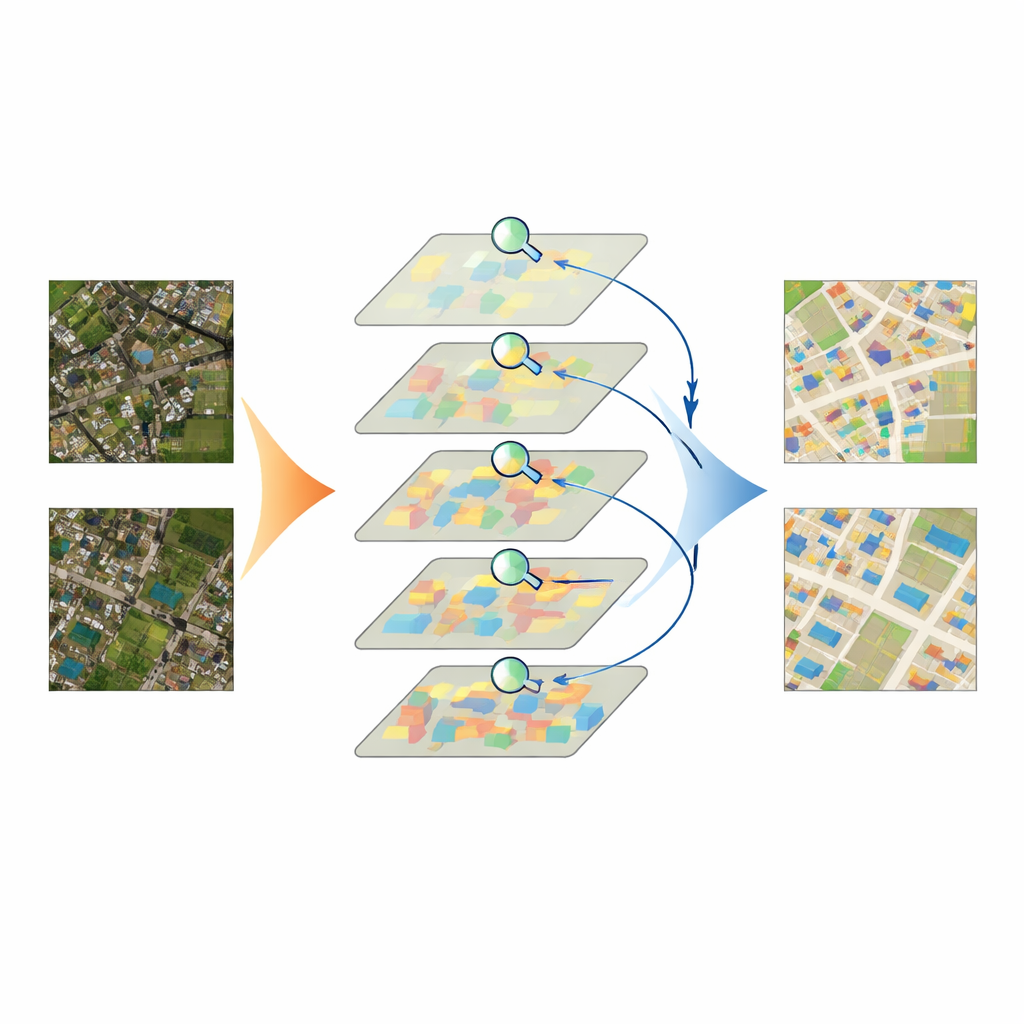
Mettre le modèle à l’épreuve
L’équipe a testé IASUNet sur trois ensembles de données de bâtiments bien connus provenant d’Allemagne, de Nouvelle‑Zélande et des États‑Unis, ainsi que sur une collection soigneusement sélectionnée d’images satellites chinoises qu’ils ont préparée et contrôlée eux‑mêmes. Sur ces bancs d’essai, IASUNet a systématiquement égalé ou surpassé les approches de pointe, y compris de puissants réseaux convolutionnels et d’autres modèles basés sur des Transformers. Sur l’ensemble Potsdam, extrêmement détaillé, il a atteint un recouvrement quasi parfait entre les régions prédictes et réelles des bâtiments, tout en restant à des vitesses d’exécution pratiques sur un matériel graphique moderne. Même sur des paysages plus irréguliers, où les bâtiments sont dispersés, partiellement cachés ou très serrés, IASUNet a tracé des contours plus nets, capturé davantage de petites cibles et évité nombre des omissions et erreurs de bord observées chez les méthodes concurrentes.
Des pixels à de meilleures villes
Concrètement, l’étude montre que l’on peut désormais apprendre aux ordinateurs à lire les panoramas urbains depuis l’orbite avec une clarté sans précédent. En orientant soigneusement « l’attention » du modèle vers les bonnes zones d’une image et en pondérant délibérément les pixels de bâtiments rares mais cruciaux, IASUNet transforme des images satellite brutes en cartes de bâtiments précises et à jour avec un surcoût de calcul modéré. De telles cartes peuvent alimenter la planification urbaine, les études sur l’énergie et les îlots de chaleur, la réglementation de l’usage des sols et l’évaluation rapide des dégâts après des catastrophes. Bien que le travail soit techniquement poussé, sa conclusion est simple : une IA plus intelligente peut offrir aux décideurs une vision plus nette et plus fiable de l’environnement bâti, aidant les villes à croître de manière plus sûre et plus durable.
Citation: Zhang, H., Ma, Y., Wang, G. et al. IASUNet: building extraction based on impoved attention Swin-UperNet. Sci Rep 16, 7969 (2026). https://doi.org/10.1038/s41598-026-36270-2
Mots-clés: Télédétection, extraction de bâtiments, segmentation sémantique, réseaux de transformeurs, cartographie urbaine