Clear Sky Science · fr
Ségrégation des glandes colorectales en supervision faible via apprentissage auto-supervisé et pseudo-étiquetage basé sur l’attention
Pourquoi c’est important pour le diagnostic du cancer
Lorsque un pathologiste examine une biopsie du côlon au microscope, l’une des indications les plus importantes de la gravité d’un cancer est la forme et l’organisation de petites structures tubulaires appelées glandes. Tracer manuellement chaque glande est lent, coûteux et difficile à standardiser entre hôpitaux. Cette étude montre comment l’intelligence artificielle peut apprendre à repérer ces glandes presque aussi bien qu’un expert tout en utilisant beaucoup moins d’annotations détaillées, ce qui pourrait accélérer et affiner le diagnostic du cancer colorectal.
Le défi de dessiner chaque petit contour
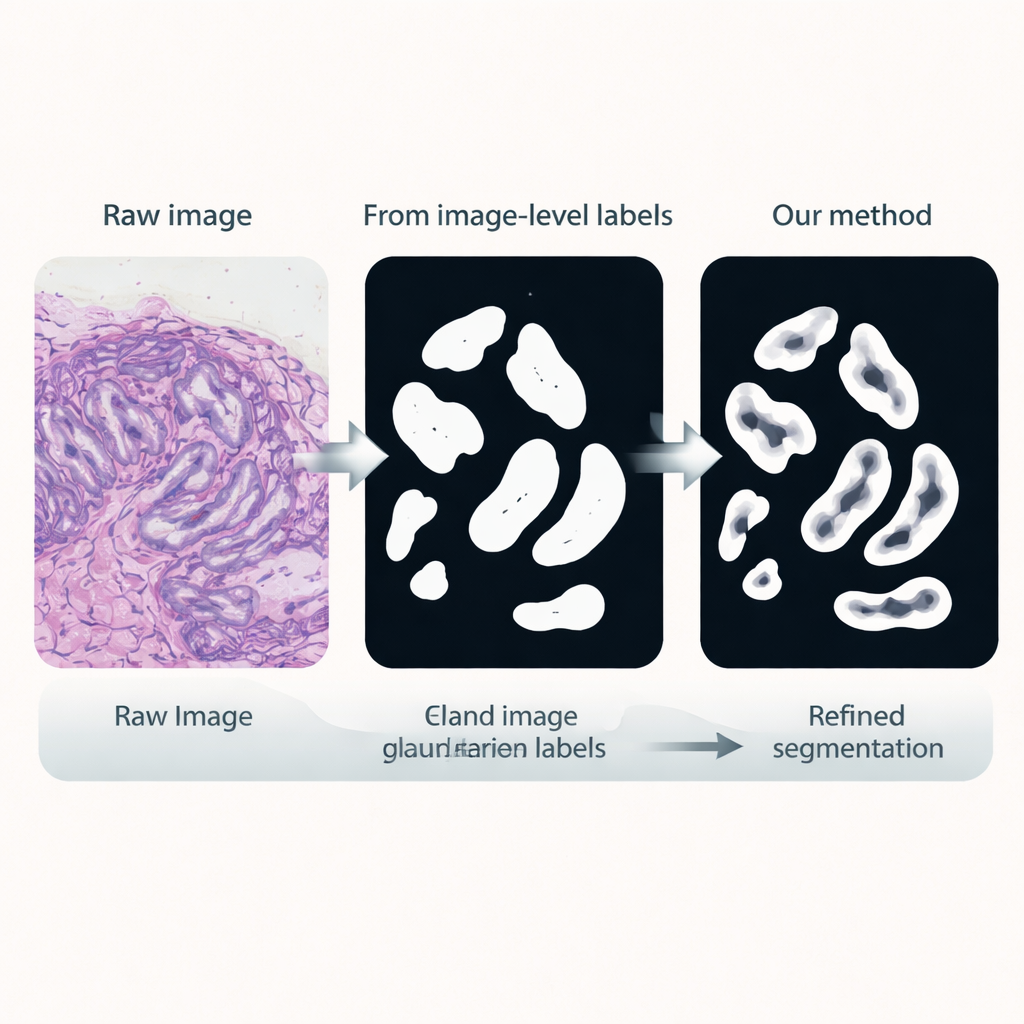
Le cancer colorectal fait partie des cancers les plus fréquents et mortels dans le monde, et l’évaluation de sa sévérité dépend fortement de l’apparence des glandes. Dans les tissus sains ou aux stades précoces, les glandes ressemblent à des tubes ronds et réguliers ; dans les tumeurs agressives, elles deviennent irrégulières, fusionnées ou à peine reconnaissables. Les ordinateurs peuvent être entraînés à segmenter, c’est‑à‑dire « colorier » chaque glande pour permettre des mesures automatiques, mais les systèmes profonds traditionnels exigent des contours pixel par pixel dessinés par des pathologistes experts. En pratique clinique, il est beaucoup plus facile d’obtenir des étiquettes au niveau de l’image, par exemple si une tuile de tissu contient ou non des glandes, ou si elle est bénigne ou maligne.
Apprendre à une IA à partir de lames non annotées et faiblement annotées
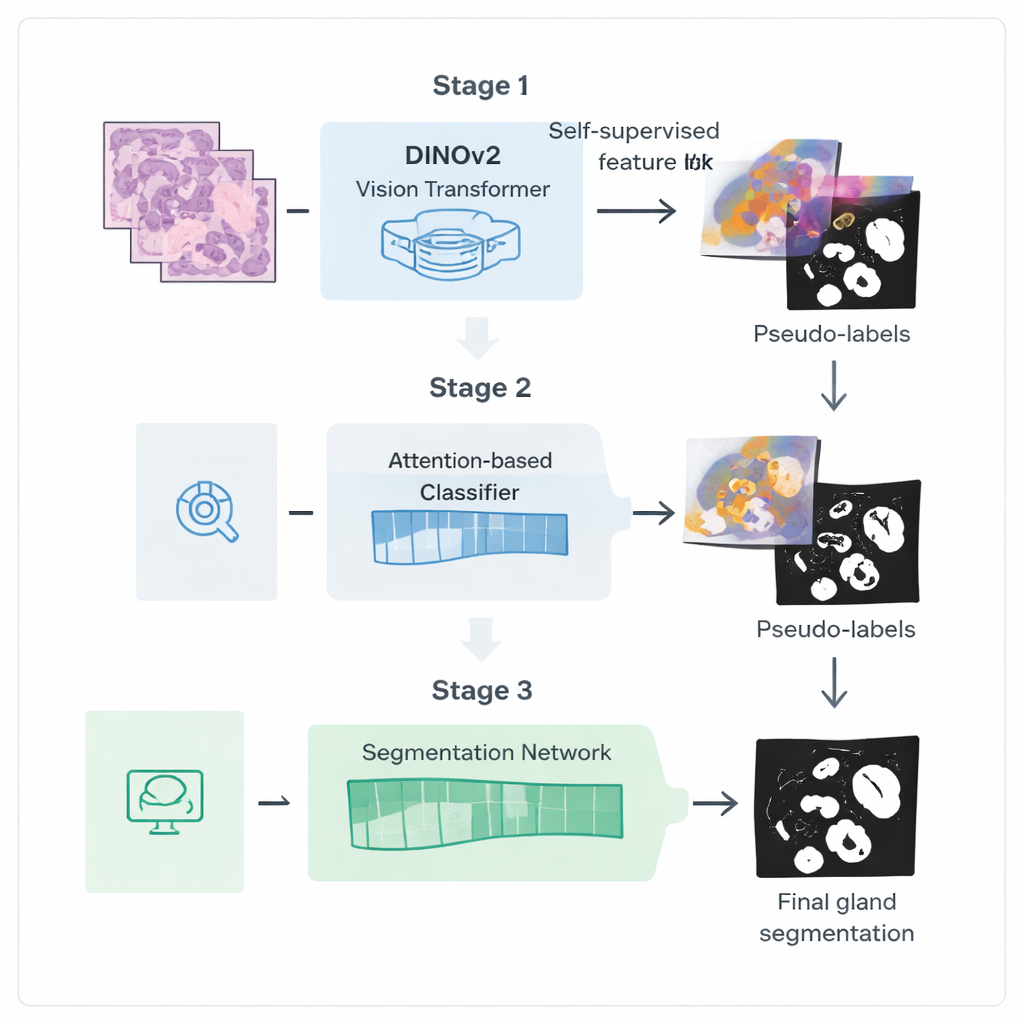
Les auteurs présentent une chaîne d’entraînement en trois étapes conçue pour tirer plus de valeur de ces annotations faibles. D’abord, ils partent d’un modèle de vision puissant appelé DINOv2, initialement entraîné sur des photographies naturelles, et l’exposent à des milliers d’images de biopsies colorectales non annotées. En demandant au modèle d’apparier différentes vues d’un même patch tissulaire, il apprend des caractéristiques visuelles adaptées aux couleurs et textures des lames d’histologie sans avoir besoin d’annotations. Cette étape crée un « encodeur » spécialisé qui transforme les images brutes en représentations internes riches capturant des structures de type glande.
Laisser l’IA montrer où elle regarde
Dans la deuxième phase, cet encodeur est intégré dans un réseau de classification qui ne nécessite que des étiquettes au niveau de l’image, comme la présence de glandes. Un mécanisme d’attention à l’intérieur du réseau apprend à attribuer des poids plus élevés aux régions de l’image qui importent pour sa décision. Ces cartes d’attention mettent effectivement en évidence les endroits où le réseau « pense » que se trouvent les glandes. Les chercheurs transforment ces cartes d’activation continues en masques binaires approximatifs par mélange et seuillage, puis les affinent avec une technique de lissage probabiliste appelée champ aléatoire conditionnel (Conditional Random Field). Le résultat est un ensemble de pseudo‑étiquettes raffinées : des contours de glandes générés par l’ordinateur qui ne sont pas parfaits, mais suffisamment bons pour guider un modèle de segmentation plus spécialisé.
Affiner les frontières des glandes
Dans la troisième étape, un réseau de segmentation dédié est entraîné en utilisant ces pseudo‑étiquettes comme substituts des annotations manuelles. Il réutilise l’encodeur affiné mais ajoute une tête décodeuse légère qui reconvertit les caractéristiques en un masque détaillé des glandes. De manière cruciale, la fonction de perte utilisée pendant l’entraînement accorde une attention particulière aux frontières : les erreurs qui déforment les bords des glandes sont pénalisées davantage que de petites erreurs à l’intérieur. Cet entraînement sensible aux contours favorise des contours nets et anatomiquement réalistes, essentiels pour mesurer précisément la forme et la séparation des glandes.
Quel est le niveau de performance en pratique ?
L’équipe a testé sa méthode sur deux jeux de référence standard de tissu colorectal. Sur le jeu GlaS, leur approche faiblement supervisée a non seulement surpassé d’autres méthodes utilisant aussi des étiquettes limitées, mais sur plusieurs mesures s’est rapprochée ou a même dépassé des systèmes classiquement supervisés qui reposent sur des annotations complètes au niveau pixel. Sur un jeu plus difficile appelé CRAG, riche en glandes très irrégulières et malignes, les performances ont chuté pour toutes les méthodes, mais le nouveau cadre a néanmoins surpassé d’autres approches à étiquettes faibles et a réduit l’écart avec les modèles pleinement supervisés. Des études d’ablation ont montré que chaque composant — l’affinage auto‑supervisé, le pseudo‑étiquetage basé sur l’attention avec post‑traitement, et la perte sensible aux contours — a contribué de manière significative aux améliorations.
Ce que cela signifie pour les outils de pathologie futurs
Pour un lecteur non spécialiste, l’idée principale est que ce travail ouvre la voie à des systèmes d’IA capables de fournir des cartes précises et nettes des structures glandulaires microscopiques tout en s’appuyant principalement sur des étiquettes au niveau de la lame, déjà courantes dans les archives hospitalières. En réduisant la dépendance aux tracés manuels fastidieux, l’approche pourrait rendre l’évaluation avancée des images et l’analyse quantitative plus réalisables dans de nombreux centres, aidant les pathologistes à diagnostiquer le cancer colorectal de façon plus cohérente et efficace, et potentiellement applicable à d’autres types de tissus et structures à l’avenir.
Citation: Wen, H., Wu, Y., Huang, D. et al. Weakly supervised colorectal gland segmentation through self-supervised learning and attention-based pseudo-labeling. Sci Rep 16, 5771 (2026). https://doi.org/10.1038/s41598-026-36256-0
Mots-clés: cancer colorectal, pathologie numérique, segmentation des glandes, apprentissage faiblement supervisé, vision auto-supervisée