Clear Sky Science · fr
Substitution dialectale comme méthode adversariale pour évaluer la robustesse du TAL en arabe
Pourquoi l’arabe quotidien embrouille les ordinateurs intelligents
Beaucoup d’applications lisent désormais du texte arabe pour juger le sentiment, trier des informations ou répondre à des questions. Pourtant, ces systèmes apprennent principalement à partir de l’arabe standard moderne (ASM), alors que les locuteurs réels mélangent quotidiennement des dialectes régionaux. Cet article montre comment remplacer un seul mot par sa forme égyptienne ou du Golfe peut tromper des modèles de langue de pointe, soulevant des inquiétudes pour quiconque s’appuie sur l’IA arabe dans le service client, la surveillance des médias ou la sécurité en ligne.
Une langue, de nombreuses voix
L’arabe n’est pas une façon uniforme de parler. L’ASM est utilisé à l’école, dans les journaux et dans l’écriture officielle, mais les conversations quotidiennes reposent sur des dialectes tels que l’égyptien et l’arabe du Golfe. Ces variantes diffèrent dans le vocabulaire, les formes des mots et parfois la structure des phrases. Par exemple, un mot simple comme « maintenant » prend des formes très différentes selon les régions. Pour les lecteurs humains, ces variations sont naturelles et faciles à comprendre. Pour des modèles informatiques entraînés presque exclusivement sur l’ASM, en revanche, les mots dialectaux peuvent sembler étrangers, transformant une phrase claire en quelque chose de déroutant.
Transformer les dialectes en test de résistance pour l’IA
Pour mesurer la fragilité réelle des modèles de langue arabe, l’auteur conçoit un test simple en deux étapes. D’abord, le modèle est interrogé à plusieurs reprises pour identifier le mot unique d’une phrase qui pèse le plus dans sa décision — souvent un adjectif fort, un verbe clé ou un nom thématique. Ensuite, ce mot est remplacé par l’équivalent égyptien ou du Golfe à l’aide d’un grand modèle « dialectiseur » finement ajusté. Le reste de la phrase est laissé intact et le sens demeure le même pour les lecteurs humains. Cela fait de la phrase modifiée un exemple adversarial réaliste : un ajustement minime et naturel conçu pour tromper le système sans altérer le message voulu.
Tester des avis d’hôtels et des articles d’actualité
L’étude attaque quatre modèles d’apprentissage profond bien connus : deux grands transformeurs (AraBERT et CAMeLBERT) et deux réseaux plus petits (un modèle convolutionnel et un LSTM bidirectionnel). Ils sont entraînés sur deux grands jeux de données en ASM : des avis d’hôtels pour l’analyse de sentiment et des articles de presse pour la classification de sujets. À partir de chaque jeu de test, l’auteur prélève 1 280 exemples et applique la procédure de substitution dialectale. Même si un seul mot de chaque phrase est changé, l’impact est saisissant. Pour les avis d’hôtels, la précision d’AraBERT passe de 94 % sur le texte propre à environ 72 % avec des substitutions du Golfe et 65 % avec des substitutions égyptiennes. CAMeLBERT chute encore davantage, autour de 63 % et 55 %. Les classificateurs de nouvelles souffrent aussi : le modèle convolutionnel perd environ 18 à 22 points de pourcentage, et le LSTM montre des déclins similaires.
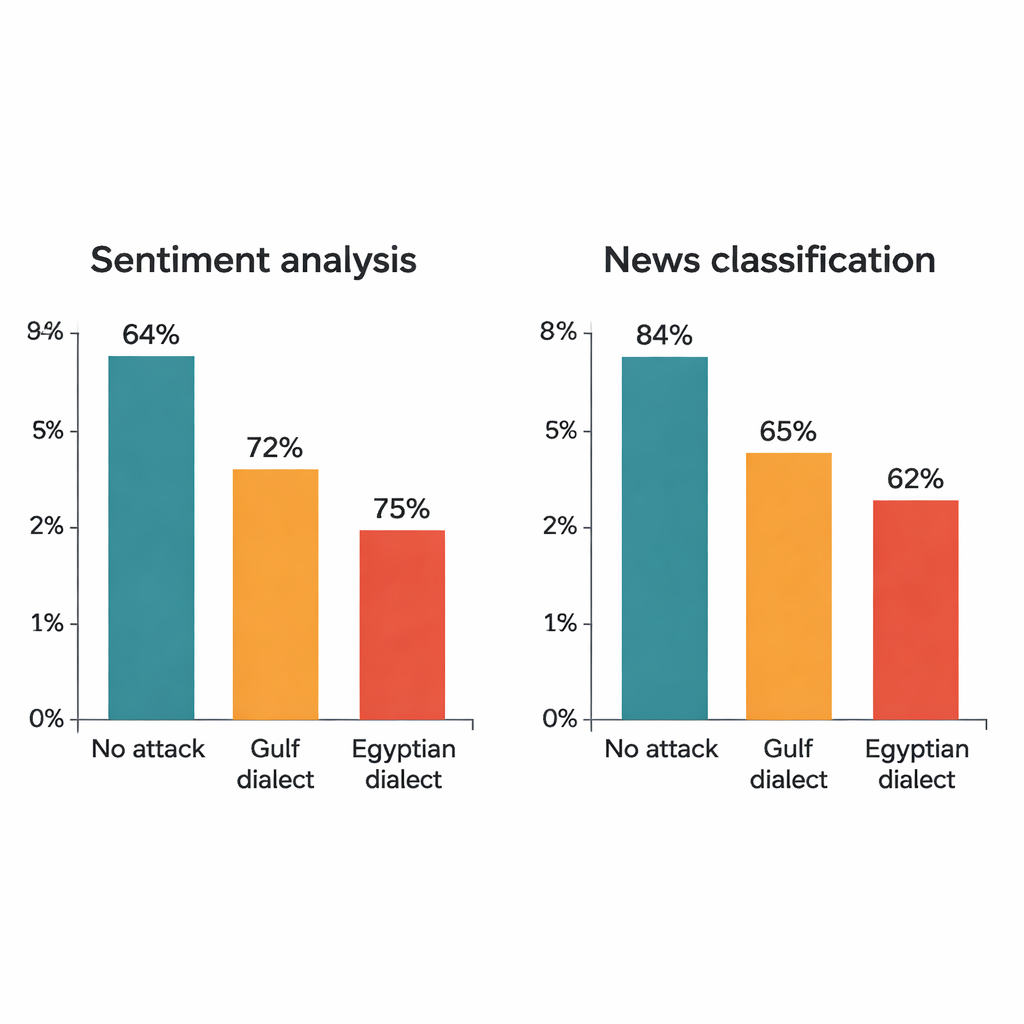
Ce qui coince à l’intérieur des modèles
Un examen plus attentif révèle que les mots les plus vulnérables correspondent à la façon dont les gens lisent réellement un texte. Dans les avis d’hôtels, près de la moitié des mots ciblés sont des adjectifs tels que « bon » ou « terrible », qui portent un poids émotionnel clair. Dans les articles d’actualité, la plupart des mots sélectionnés sont des noms et des noms propres signalant des sujets comme la politique, le sport ou la finance. Lorsque ces mots déclencheurs sont remplacés par des formes dialectales, les modèles entraînés uniquement sur l’ASM ne les reconnaissent souvent pas. Les transformeurs se révèlent particulièrement fragiles : leur dépendance aux fragments de sous-mots et leur attention concentrée sur quelques jetons fortement pondérés font qu’un seul mot dialectal suffit à renverser une prédiction. Les modèles plus petits, qui répartissent l’attention plus uniformément sur la phrase, se font aussi duper mais sont légèrement plus robustes.
Égyptien versus Golfe : tous les dialectes ne se valent pas
Les attaques montrent aussi que l’arabe égyptien tend à déstabiliser davantage les modèles que l’arabe du Golfe. Des études linguistiques confirment cela : les variétés du Golfe restent souvent plus proches de l’ASM au niveau du vocabulaire et de la structure, tandis que l’égyptien a absorbé des formes plus distinctes par l’histoire et le contact avec d’autres langues. En conséquence, les substitutions du Golfe ressemblent parfois suffisamment à l’original en ASM pour que le modèle puisse encore s’en sortir, alors que les substitutions égyptiennes sont plus susceptibles de sortir du domaine connu du modèle. Des tests statistiques confirment que les baisses de performance observées ne sont pas aléatoires — elles reflètent des angles morts systématiques dans la façon dont les systèmes actuels gèrent la diglossie arabe.
Ce que cela signifie pour l’IA en arabe
Pour les utilisateurs quotidiens, la conclusion est simple : l’IA arabe d’aujourd’hui peut être facilement perturbée par des mots dialectaux ordinaires, même lorsque les humains trouvent le texte parfaitement clair. Un seul terme dialectal dans un avis d’hôtel peut faire basculer le jugement d’un modèle de positif à négatif, ou mal étiqueter le sujet d’un article de presse. Pour les chercheurs et les développeurs, le message est un appel à construire des systèmes « conscients de la diglossie » qui s’entraînent à la fois sur l’ASM et sur les dialectes régionaux, et à utiliser des tests de résistance réalistes comme la substitution dialectale pour évaluer la robustesse. D’ici là, toute application qui suppose « l’arabe, c’est juste l’ASM » prend le risque de graves malentendus sur le terrain.
Citation: Alshemali, B. Dialectal substitution as an adversarial approach for evaluating Arabic NLP robustness. Sci Rep 16, 5996 (2026). https://doi.org/10.1038/s41598-026-36252-4
Mots-clés: TAL en arabe, variation dialectale, exemples adversariaux, analyse de sentiment, classification de texte