Clear Sky Science · fr
Réseau de fusion d'informations de contours entre étapes pour la détection de petits objets dans les images aériennes
Pourquoi repérer de minuscules détails depuis le ciel est important
De la surveillance du trafic et la réponse aux catastrophes à la gestion des cultures, de plus en plus de zones sont observées depuis les airs par des drones. Pourtant, bien des éléments qui nous importent dans ces images aériennes — personnes, voitures ou animaux — n’occupent que quelques pixels. Cet article présente un nouveau système de vision par ordinateur, CEIFNet, conçu spécifiquement pour détecter ces tout petits objets de façon plus précise et plus rapide, même lorsqu’ils évoluent au milieu d’un encombrement urbain, de champs ou de bruits nocturnes.
Voir les petits éléments dans une grande image
Les systèmes standard de détection d’objets ont été conçus principalement pour des photos au niveau du sol, où une voiture ou une personne remplit généralement une part visible du cadre. Dans les images de drone, en revanche, la caméra peut se trouver à des centaines de mètres, si bien que chaque cible est minuscule et facilement floutée ou perdue quand l’image est réduite à l’intérieur d’un réseau neuronal. Les auteurs expliquent que des détecteurs monophases populaires comme la famille YOLO fonctionnent bien pour des scènes du quotidien mais peinent lorsque les objets sont à la fois minuscules et très variables en taille. Les multiples sous-échantillonnages, destinés à appréhender l’ensemble de la scène, ont tendance à effacer les signaux faibles de ces petites cibles.
Mêler une vision gros plan et le contexte d’ensemble
Pour y remédier, CEIFNet combine deux manières complémentaires de voir. Une voie utilise des filtres convolutionnels classiques, efficaces pour capturer des motifs locaux nets comme des angles et des textures. L’autre voie recourt à un mécanisme d’attention de type Transformer, qui excelle à relier des parties éloignées de l’image et à comprendre la scène dans son ensemble. Dans le bloc central, appelé bloc transformeur inter-étapes, les caractéristiques d’entrée sont divisées : la plupart des canaux passent par une voie convolutionnelle légère, tandis qu’une plus petite portion emprunte une voie d’attention qui raisonne sur les relations à longue portée. Elles sont ensuite recombinées, donnant au réseau à la fois des détails fins et une conscience globale sans faire exploser son coût de calcul.
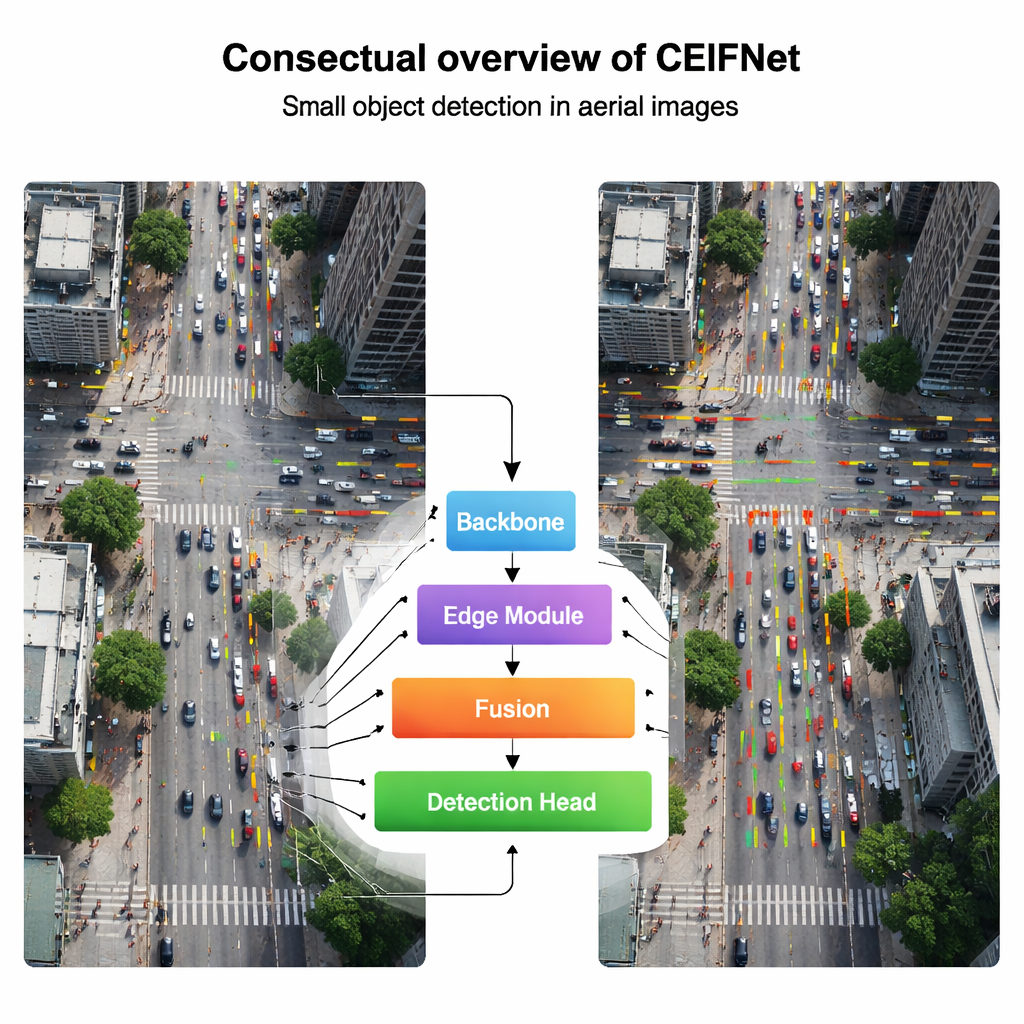
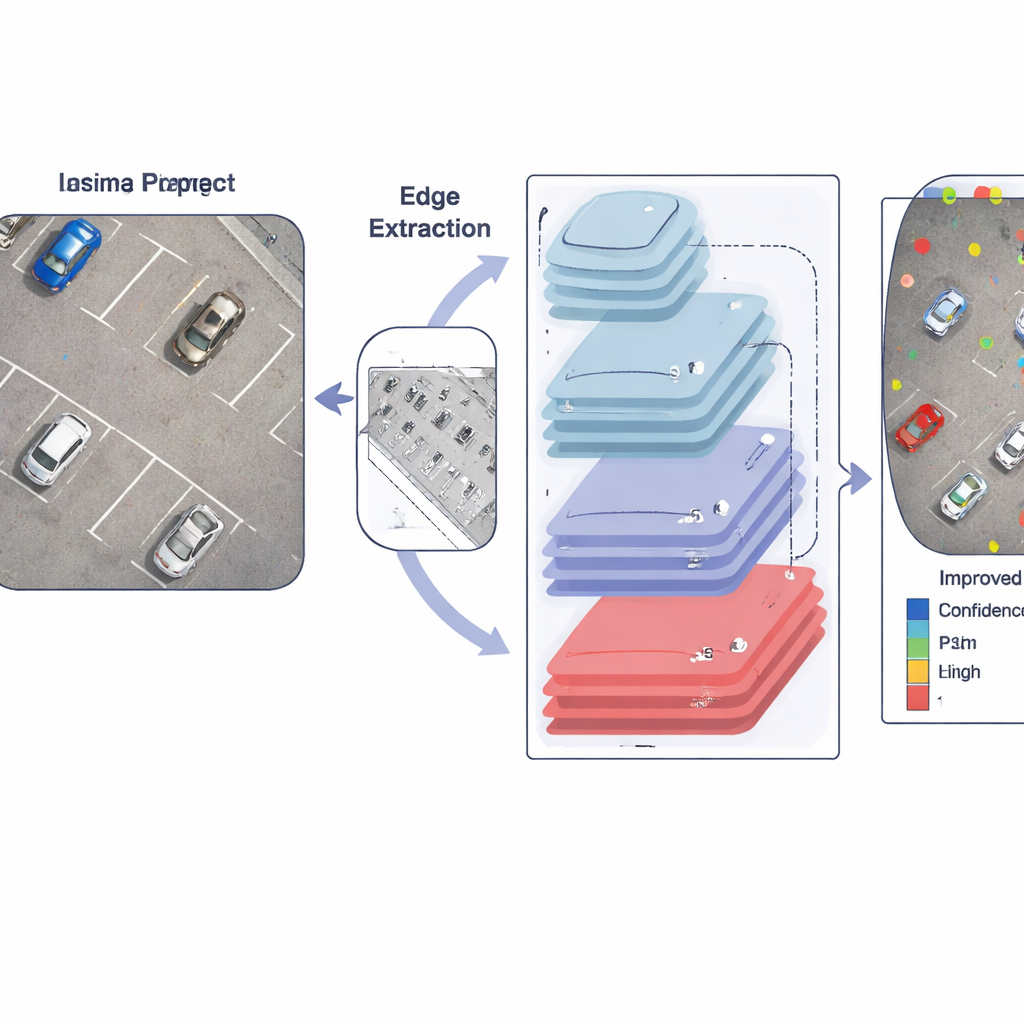
Utiliser les contours comme carte pour les petites cibles
Une idée clé de l’article est que les frontières d’objet — les contours — sont particulièrement utiles lorsque les cibles ne font que quelques pixels. Plutôt que de se reposer uniquement sur des filtres appris, les auteurs injectent délibérément l’information de contours dans le réseau. Un module dédié applique d’abord un opérateur de Sobel, un détecteur de contours simple mais robuste, pour mettre en évidence les changements brusques de luminosité, comme autour des silhouettes de voitures ou de personnes. Ces cartes de contours sont ensuite mises en pool à plusieurs tailles pour correspondre aux différentes échelles de caractéristiques et fusionnées via un module inter-canaux. Au fur et à mesure que l’image progresse dans le réseau, ces indices de contours affinés sont réinjectés dans les couches ultérieures, aidant le modèle à suivre où commencent et se terminent les petits objets malgré le flou et la réduction habituels.
S’adapter à la taille, à la position et à la complexité de la scène
En sortie, CEIFNet utilise une tête de détection dynamique capable d’ajuster son comportement en fonction de ce qu’elle voit. Plutôt que d’utiliser des filtres fixes, cette étape finale applique simultanément trois formes d’attention : elle peut préférer certaines tailles d’objets, se concentrer sur les emplacements les plus prometteurs dans l’image et mettre l’accent sur les canaux de caractéristiques les plus informatifs. Associée à une structure en pyramide de caractéristiques qui conserve une couche supplémentaire très fine, cela rend le système plus réactif aux cibles minuscules et densément regroupées dans des séquences de drone réalistes, des intersections bondées aux parkings occupés en passant par des scènes thermiques infrarouges la nuit.
Montrer les gains sur des scénarios réels de drone
Les chercheurs ont testé CEIFNet sur deux jeux de données exigeants de drones : VisDrone2019, composé de scènes urbaines et suburbaines en plein jour, et HIT-UAV, une collection infrarouge thermique où de nombreuses cibles sont faibles et petites. Sur les deux, le nouveau système a détecté les objets plus précisément qu’une solide référence basée sur YOLO et qu’une gamme d’autres détecteurs modernes, tout en restant suffisamment rapide pour une utilisation en temps réel sur une carte graphique puissante. Des expériences d’ablation soignées ont montré que chaque élément — le bloc hybride, le module de contours, la couche fine supplémentaire et la tête dynamique — a contribué à la performance globale.
Ce que cela signifie pour la technologie quotidienne
Pour les non-spécialistes, la conclusion est que CEIFNet offre une manière plus intelligente pour les drones de « remarquer les petites choses » dans de vastes scènes complexes. En préservant l’information de contours, en mélangeant détail local et contexte global, et en adaptant dynamiquement son attention, le réseau peut repérer des petits objets que d’autres systèmes manquent ou localisent mal. Cela rend la surveillance aérienne plus fiable pour des tâches comme la sécurité routière, la recherche et le sauvetage, et l’agriculture de précision, et ouvre la voie à de futurs systèmes capables d’extraire des informations fiables depuis des vues toujours plus hautes et plus larges de notre monde.
Citation: Xiao, J., Li, C., Chen, H. et al. Cross-stage edge information fusion network for small object detection in aerial images. Sci Rep 16, 7639 (2026). https://doi.org/10.1038/s41598-026-36251-5
Mots-clés: détection d'objets aériens, petits objets, imagerie par drone, vision basée sur les contours, apprentissage profond