Clear Sky Science · fr
Optimisation de la prédiction de la mortalité liée à la septicémie grâce à un cadre hybride d'apprentissage fédéré et d'IA explicable
Pourquoi des infections mortelles prennent encore les hôpitaux au dépourvu
La septicémie est l’une des urgences les plus dangereuses de la médecine moderne. Une infection banale — des voies urinaires, des poumons ou même de la peau — peut déclencher soudainement une réaction généralisée qui fait tomber les organes vitaux en panne et entraîne la mort en quelques heures. Les médecins savent qu’agir tôt sauve des vies, mais il reste difficile d’identifier quels patients vont basculer vers une défaillance. Cette étude examine comment une nouvelle combinaison d’intelligence artificielle préservant la confidentialité et d’explications « boîte‑transparente » pourrait aider les hôpitaux à repérer plus tôt les patients à haut risque de septicémie, sans exposer les dossiers médicaux sensibles.
Des grilles d’évaluation simples aux outils intelligents et gourmands en données
Jusqu’à présent, de nombreux hôpitaux se sont appuyés sur des listes de contrôle et des systèmes de score tels que SOFA et qSOFA. Ces outils surveillent quelques mesures de base — comme la tension artérielle et la fréquence respiratoire — et donnent une idée approximative de la gravité de l’état d’un patient. Mais ils sont souvent appliqués tardivement et ignorent les flux riches d’informations désormais stockés dans les dossiers de santé électroniques et les moniteurs au chevet. En conséquence, ils peuvent manquer les motifs complexes qui annoncent une défaillance d’organe liée à la septicémie et le décès. Les chercheurs se sont tournés vers l’apprentissage automatique, capable de trier des milliers de points de données par patient, mais ce changement pose deux nouveaux problèmes : les hôpitaux hésitent à mutualiser leurs données brutes par crainte de violations de la vie privée, et de nombreux modèles avancés fonctionnent comme des « boîtes noires » opaques que les cliniciens peinent à appréhender.
Un réseau d’hôpitaux qui apprennent sans se partager leurs secrets
Les auteurs proposent un cadre qui traite à la fois la confidentialité et la confiance. Ils utilisent l’apprentissage fédéré, une stratégie dans laquelle chaque hôpital entraîne le même jeu de modèles de prédiction sur ses propres données de soins intensifs — fréquence cardiaque, tension artérielle, taux d’oxygène, analyses de laboratoire, et plus — sans jamais envoyer les dossiers patients à un serveur central. Seules les mises à jour des modèles sont en revanche combinées de manière sécurisée dans le cloud pour former un modèle global renforcé. Ainsi, le système apprend à partir d’un large et divers ensemble de patients tout en maintenant leurs dossiers derrière le pare‑feu de chaque établissement. Pour éviter que le modèle n’apprenne simplement que « la plupart des patients survivent », l’équipe a aussi rééquilibré les données afin que les cas de septicémie mortels et non mortels soient mieux représentés, en utilisant une technique qui crée des exemples synthétiques réalistes des issues moins fréquentes.
Ouvrir la boîte noire pour les médecins au chevet
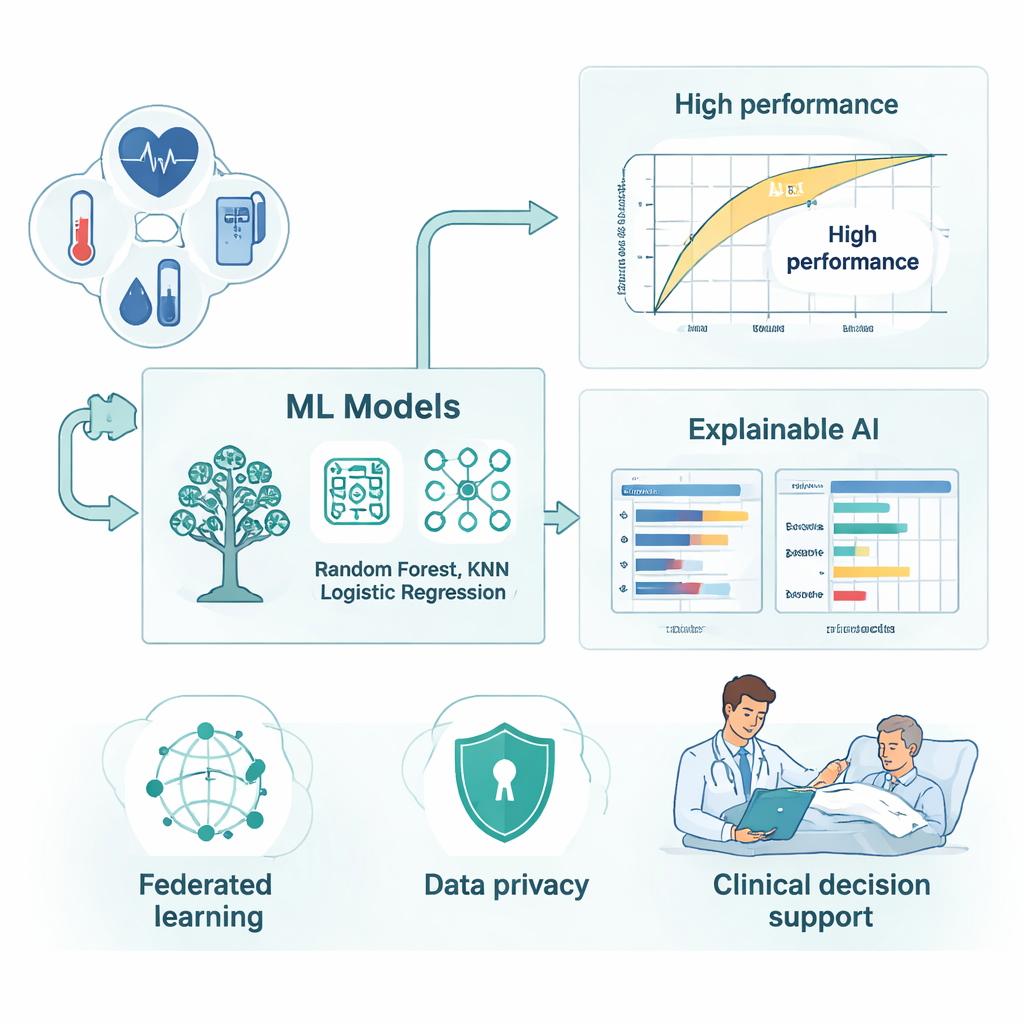
Dans ce dispositif fédéré, les chercheurs ont entraîné plusieurs modèles d’apprentissage automatique bien connus, notamment Random Forest, LightGBM, XGBoost, K‑Nearest Neighbors et la régression logistique. Ils ont ensuite enveloppé ces modèles dans une couche d’« IA explicable » conçue pour montrer non seulement un score de risque, mais aussi le raisonnement qui le sous‑tend. Des outils tels que SHAP et LIME décomposent chaque prédiction en contributions de caractéristiques cliniques spécifiques — combien une augmentation de la fréquence respiratoire, un séjour en soins intensifs plus long ou une chute de la saturation en oxygène pousse un patient vers la catégorie à haut risque. Les graphiques de dépendance partielle offrent une vue d’ensemble, révélant, par exemple, comment le danger prédit augmente régulièrement une fois que la fréquence respiratoire ou la durée de séjour dépasse certains seuils. Ces explications aident les cliniciens à voir quand l’alerte du modèle concorde avec leur propre jugement et quand elle peut réagir à des tendances cachées dans les données qui méritent un examen plus approfondi.
Des performances solides sans sacrifier la confidentialité
En utilisant un grand jeu de données de septicémie disponible publiquement, construit à partir de dossiers de soins intensifs, l’équipe a testé son approche à la fois dans un entraînement centralisé traditionnel et dans le contexte fédéré plus réaliste. Les modèles ensemblistes — en particulier Random Forest et les méthodes de gradient‑boosting — se sont distingués. Dans le cas centralisé, le meilleur modèle a correctement classé presque tous les patients et obtenu une discrimination quasi parfaite entre survivants et non‑survivants. Lorsqu’on a entraîné les mêmes modèles dans un réseau simulé de cinq hôpitaux virtuels avec des compositions de patients différentes, les performances n’ont légèrement diminué que de façon marginale, tout en restant très élevées. Ce compromis minime a permis des gains importants en matière de confidentialité et d’indépendance institutionnelle : aucune donnée patient brute n’a quitté les serveurs locaux, et le système a tout de même détecté la grande majorité des cas à haut risque.
Ce que cela signifie pour les patients et les cliniciens
Pour un non‑spécialiste, la conclusion est simple : en permettant aux hôpitaux « d’apprendre ensemble » sans partager leurs dossiers réels, et en obligeant l’ordinateur à expliciter son raisonnement, ce cadre rapproche la prédiction du risque de septicémie d’une utilisation concrète. Les médecins pourraient recevoir des alertes précoces et explicables indiquant qu’une infection d’un patient bascule vers une défaillance d’organe, appuyées par des indications claires sur les signes vitaux et les résultats de laboratoire qui motivent cet avertissement. Selon l’étude, un tel système peut rester précis même sous des règles strictes de confidentialité et dans des conditions hospitalières variées. S’il est validé en environnement clinique réel, cet hybride d’apprentissage fédéré et d’IA explicable pourrait devenir un filet de sécurité important en réanimation, permettant de détecter davantage de patients atteints de septicémie avant qu’il ne soit trop tard.
Citation: Fuzail, M.Z., Din, I.u., Ahmed, S. et al. Optimizing sepsis mortality prediction using hybrid federated learning and explainable AI framework. Sci Rep 16, 5218 (2026). https://doi.org/10.1038/s41598-026-36245-3
Mots-clés: septicémie, prévision de la mortalité, apprentissage fédéré, IA explicable, soins intensifs