Clear Sky Science · fr
Réseau antagoniste génératif convolutionnel à contexte atrous profond avec extraction de points clés de coin pour la classification des noix
Un tri plus intelligent pour les noix du quotidien
Des mélanges apéritifs aux beurres de noix, des milliards de noix traversent des usines chaque année, et chacune doit être triée par type et par qualité. Aujourd'hui, cela est souvent réalisé par des machines qui peinent encore lorsque les noix se ressemblent ou que les photos sont prises dans des conditions d'éclairage différentes. Cette étude présente un système d'intelligence artificielle puissant appelé DAC‑GAN capable de distinguer huit variétés courantes de noix avec une précision quasi parfaite, promettant un tri plus rapide, moins coûteux et plus fiable pour l'industrie alimentaire.
Pourquoi reconnaître les noix est difficile
Au premier abord, une noix de cajou et une cacahuète semblent faciles à différencier. Mais en conditions réelles de production, les noix peuvent être inclinées, cassées, se chevaucher ou être mal éclairées. Les programmes traditionnels reposent sur des indices simples conçus manuellement, comme la couleur ou la forme moyenne, qui s'effondrent facilement lorsque les conditions changent. L'apprentissage profond a amélioré la situation en permettant aux ordinateurs d'apprendre des motifs directement à partir des images, mais ces méthodes exigent généralement des jeux de données très grands et soigneusement équilibrés. Pour les noix, seules quelques milliers de photos annotées peuvent être disponibles, et certaines variétés peuvent se ressembler de façon troublante, entraînant des erreurs et des prédictions biaisées.
Produire plus et de meilleures images d'entraînement
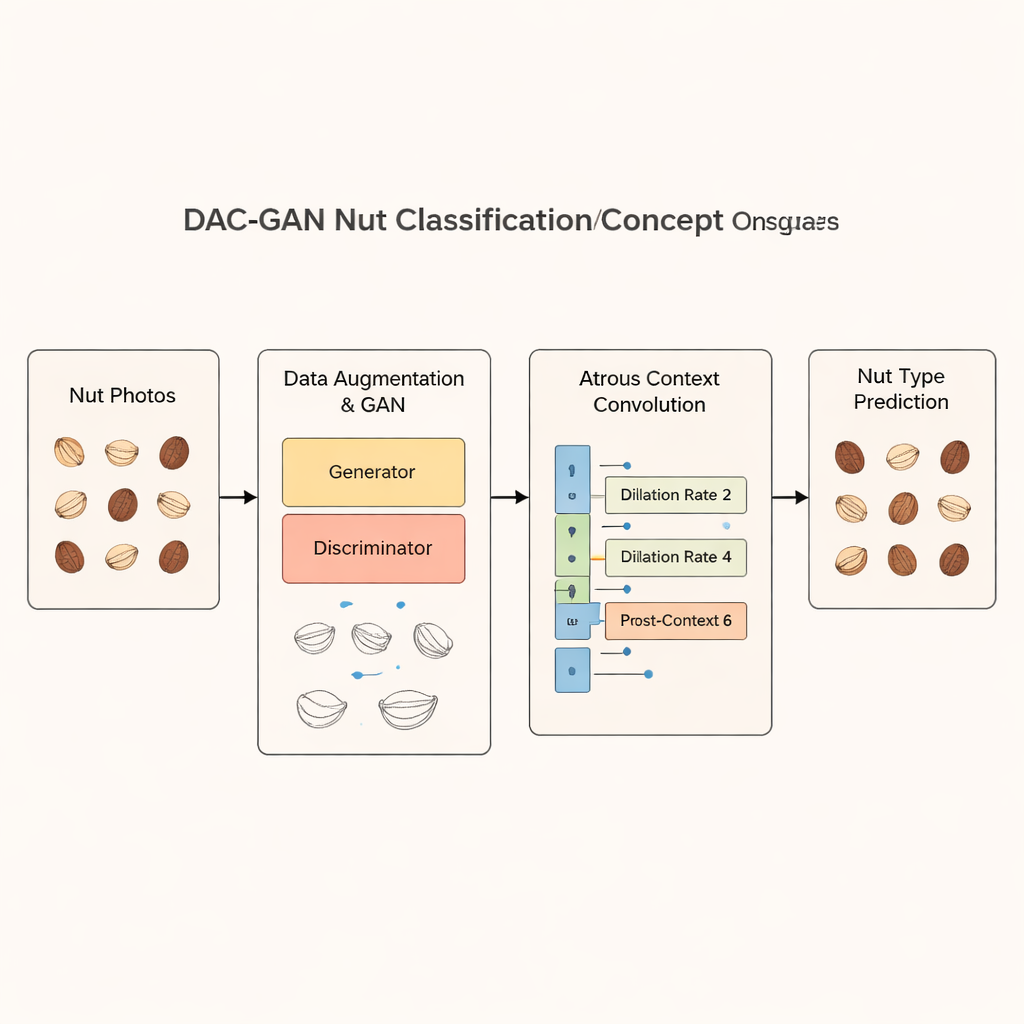
Les chercheurs partent d'une collection publique « Common Nut » contenant 4 000 photos réparties équitablement entre huit types de noix : noix du Brésil, noix de cajou, châtaigne, cacahuète, pacane, pistache, macadamia et noix. Pour entraîner un modèle robuste, ils ont besoin de bien plus d'exemples. DAC‑GAN aborde le problème en utilisant un type spécial de réseau neuronal appelé réseau antagoniste génératif (GAN). Une partie du GAN, le générateur, apprend à créer des images de noix réalistes à partir de bruit aléatoire, tandis qu'une autre partie, le discriminateur, apprend à différencier le vrai du faux. À mesure que les deux s'affrontent, le générateur devient capable de produire des noix synthétiques de haute qualité et très réalistes. En combinant ces images artificielles avec des retournements et rotations classiques, l'équipe étend le jeu de données à plus de 70 000 images tout en maintenant un équilibre parfait entre les classes de noix.
Apprendre au modèle à se concentrer sur les détails des noix
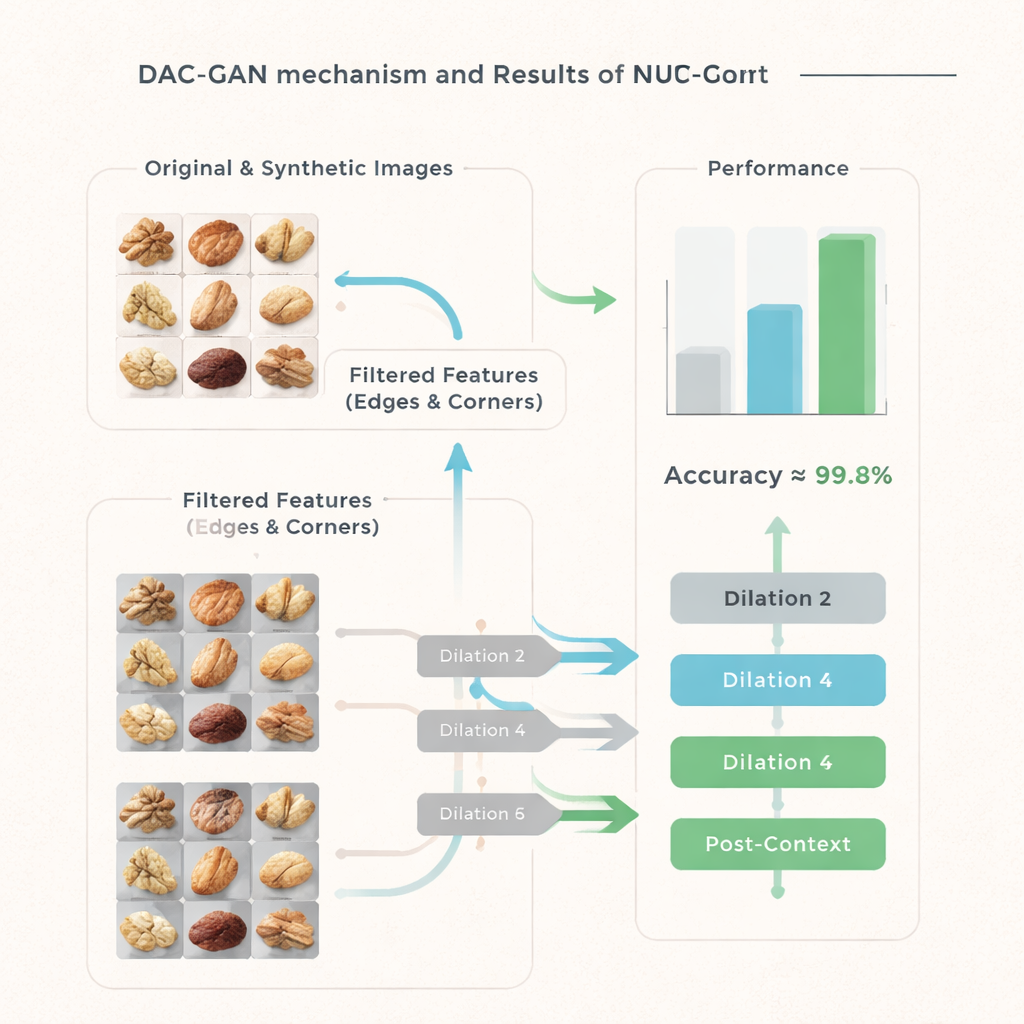
Ajouter simplement plus d'images ne suffit pas ; le modèle doit aussi se focaliser sur les bons indices visuels. DAC‑GAN introduit une étape de filtration qui convertit les photos de noix en niveaux de gris puis extrait des contours marqués, des arêtes et des points de coin distinctifs. Ces « caractéristiques de points clés de coin » captent où la forme de la noix se plie ou où la texture de la surface change, des détails qui distinguent souvent une variété d'une autre. Des filtres supplémentaires mettent en évidence les contours globaux du noyau et les motifs internes. Plutôt que d'alimenter des photos brutes dans le classifieur, le système travaille sur ces images de caractéristiques affinées, qui mettent l'accent sur la géométrie et la texture tout en atténuant les arrière-plans distrayants et les variations de couleur.
Voir la noix entière à plusieurs échelles
Le cœur de DAC‑GAN est une version affinée d'une technique appelée convolution atrous, ou dilatée. Les couches convolutionnelles ordinaires dans les réseaux profonds ne voient que de petits patchs à la fois. La convolution atrous espace les points d'échantillonnage afin que le modèle puisse appréhender une vue plus large sans perdre en résolution. Les auteurs ajoutent des blocs de « pré‑contexte » et de « post‑contexte » autour de cette opération centrale, qui résument l'image entière et réinjectent ce résumé dans la couche. En exécutant trois convolutions de ce type avec des taux de dilatation différents, le réseau apprend à capturer à la fois les petites stries à la surface d'une noix et sa silhouette globale, puis combine ces vues en une représentation riche et consciente du contexte avant de prendre une décision.
Quel est son niveau de performance ?
L'équipe soumet DAC‑GAN à une série étendue de tests. Ils le comparent à de nombreux réseaux neuronaux bien connus, des modèles classiques comme VGG et ResNet aux architectures plus récentes basées sur des transformeurs, avec et sans données synthétiques. Sur la précision, la précision positive, le rappel et le score F1 combiné, DAC‑GAN surpasse systématiquement toutes les alternatives de manière significative. Sur l'ensemble de test retenu composé d'images réelles de noix, il identifie correctement le type de noix dans 99,83 % des cas, avec seulement 25 erreurs sur 800 échantillons. Même les modèles concurrents les plus performants restent plusieurs points de pourcentage derrière, et les statistiques détaillées montrent que l'avantage de DAC‑GAN n'est pas dû au hasard mais est statistiquement très robuste.
Ce que cela signifie pour l'alimentation et au‑delà
Pour les non‑spécialistes, la conclusion est simple : en inventant intelligemment des images d'entraînement supplémentaires et en apprenant au réseau à se concentrer sur les contours, les coins et le contexte multi‑échelle, DAC‑GAN transforme un problème visuellement subtil en un problème qu'il peut résoudre presque parfaitement. En pratique, cette approche pourrait conduire à des machines de tri automatisées capables de traiter de gros volumes avec très peu d'erreurs, améliorant le contrôle qualité tout en réduisant le travail manuel. Parce que la méthode est générale, elle pourrait également être adaptée à d'autres produits alimentaires — ou même à des pièces industrielles — qui doivent être distingués sur la base de détails visuels fins dans des conditions d'imagerie imparfaites.
Citation: Devi, M.S., Jaiganesh, M., Priya, S. et al. Deep atrous context convolution generative adversarial network with corner key point extracted feature for nuts classification. Sci Rep 16, 6409 (2026). https://doi.org/10.1038/s41598-026-36238-2
Mots-clés: classification des noix, apprentissage profond, augmentation d'images, tri alimentaire, vision par ordinateur