Clear Sky Science · fr
Prévision de la qualité des eaux de surface via un réseau neuronal hybride MLA-Mamba optimisé par GRPO
Pourquoi prédire l’état des rivières est important
Les rivières et les lacs sont nos sources d’eau potable, nos ressources pour l’irrigation et des habitats pour la faune. Pourtant leur qualité peut évoluer rapidement lorsque des polluants arrivent des exploitations agricoles, des usines ou des zones urbaines. Les autorités ne le constatent souvent qu’après que les dommages sont survenus. Cette étude examine comment l’intelligence artificielle moderne peut fonctionner comme un système d’alerte précoce performant, en prévoyant des variations de la qualité de l’eau plusieurs jours à l’avance afin de donner aux gestionnaires le temps de réagir.
Outils anciens, nouveaux défis
Pendant des décennies, les scientifiques ont tenté de prédire la qualité de l’eau à l’aide de formules mathématiques et de statistiques classiques. Ces méthodes simulent soit la chimie et l’écoulement en détail, soit ajustent les mesures passées avec des courbes relativement simples. Les deux approches peinent face à la réalité complexe des rivières, où le temps, les rejets en amont et l’activité biologique interagissent de façon non linéaire. Elles manquent souvent les pics de pollution soudains ou n’intègrent pas correctement la façon dont les conditions à une station se répercutent en aval. Par conséquent, les prévisions peuvent être trop grossières pour servir de base à des décisions sûres.
Apprendre à un réseau neuronal à « lire » une rivière
Les auteurs proposent un nouveau modèle d’apprentissage profond, appelé MLA-Mamba, conçu spécifiquement pour cette complexité spatiale et temporelle. Plutôt que d’examiner un capteur isolé, le modèle ingère une semaine de données horaires provenant de plusieurs stations de surveillance, ainsi que des informations complémentaires comme la température de l’eau, le débit et l’acidité. Il apprend ensuite à prédire quatre indicateurs clés signalant la pollution organique et l’apport en nutriments : un indice de demande chimique en oxygène (CODMn), l’ammoniaque (NH3–N), le phosphore total (TP) et l’azote total (TN). Le modèle combine deux composants spécialisés. L’un se concentre sur les motifs temporels, repérant cycles, dérives lentes et effets retardés. L’autre analyse l’espace, apprenant comment les stations en amont et voisines évoluent conjointement. En fusionnant ces points de vue, le réseau construit une image plus riche de l’évolution de la qualité de l’eau.
Capturer à la fois les tendances temporelles et l’influence en amont
Dans le cadre MLA-Mamba, le module « Mamba » se concentre sur la dimension temporelle. Il analyse de longues séquences de mesures, en s’appuyant sur des idées issues des modèles d’état et des réseaux récurrents modernes pour conserver des informations datant de plusieurs jours sans être submergé. Cela lui permet de reconnaître des schémas saisonniers et des impacts persistants d’événements passés. En parallèle, un module « Multi-Head Local Attention » pondère l’importance de chaque station par rapport aux autres à un instant donné, avec un biais intégré en faveur des sites proches sur le même tronçon. Si une station en amont enregistre soudainement une hausse d’ammoniaque, le mécanisme d’attention peut rapidement concentrer l’analyse sur ce signal lors de la prévision en aval. Une configuration multi-tâches permet au modèle d’apprendre les quatre indicateurs simultanément, de sorte que les variations d’un polluant éclairent aussi les attentes pour les autres.
Un entraînement plus intelligent pour des données environnementales bruyantes
L’entraînement d’un tel réseau sur des enregistrements capteurs réels est délicat : les données sont bruitées, il existe des manques et les méthodes d’optimisation classiques peuvent rester bloquées. Pour y remédier, les chercheurs introduisent une stratégie d’entraînement sur mesure qu’ils appellent Gradient Reparameterization Optimization (GRPO). GRPO ajuste la vitesse d’apprentissage de chaque paramètre du réseau en fonction du comportement de son gradient au fil du temps, accélérant approximativement dans les directions stables et ralentissant lorsque les mises à jour se mettent à osciller. Il impose aussi une taille de pas minimale pour éviter que l’apprentissage n’stagne sur des régions plates de la surface d’erreur. L’équipe utilise par ailleurs le dropout non seulement pour prévenir le surapprentissage, mais aussi pour estimer l’incertitude, en exécutant le modèle plusieurs fois et en examinant la variabilité des prédictions. Cela fournit des bandes de confiance autour de chaque prévision, donnant aux gestionnaires une idée de la fiabilité d’une prédiction donnée.
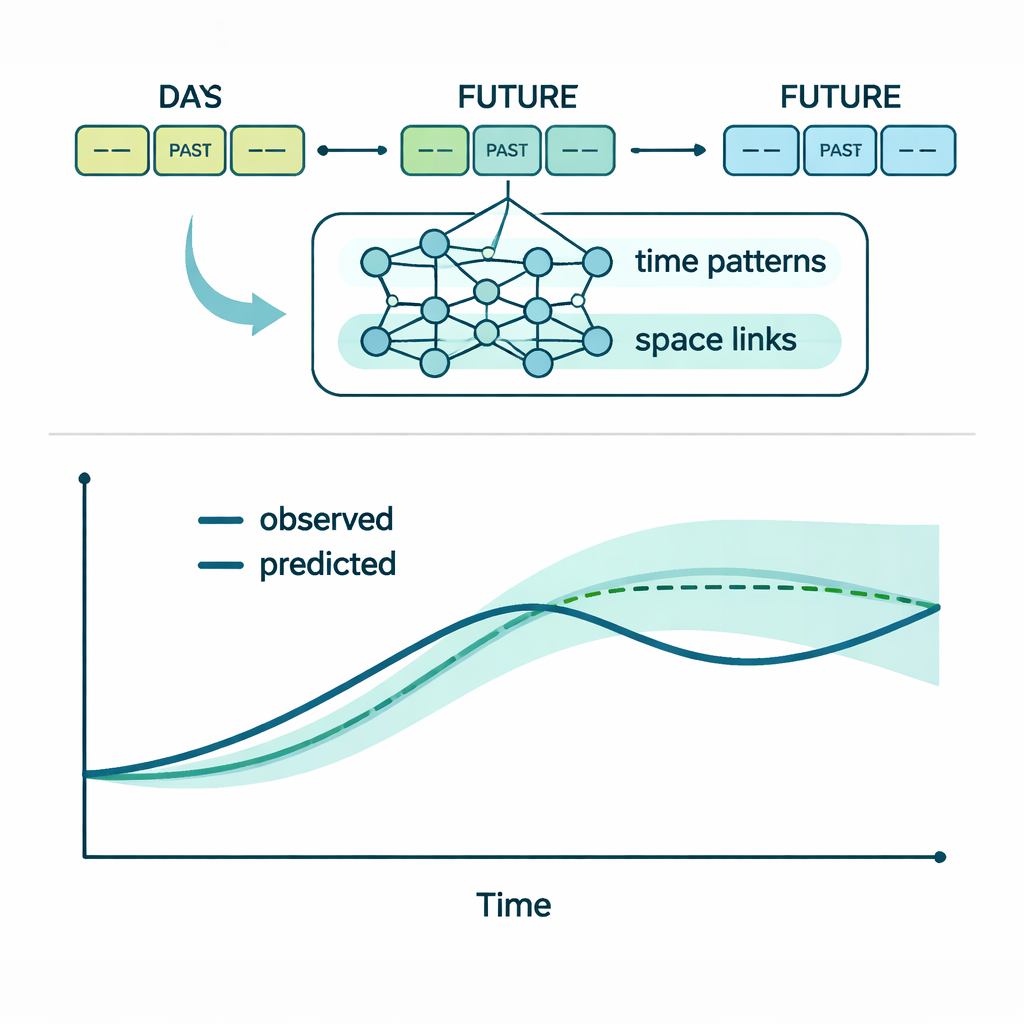
Mettre le modèle à l’épreuve
Les auteurs évaluent MLA-Mamba sur plusieurs années de données horaires issues de deux stations fluviales en Chine, l’une en amont de l’autre. Le modèle prend les sept jours précédents de données et prédit les trois jours suivants. Il est comparé à huit alternatives, allant des méthodes statistiques classiques aux architectures d’apprentissage profond modernes comme les réseaux à mémoire à long terme (LSTM), des hybrides convolution–récurrent, et des modèles Transformer. Sur les quatre indicateurs et les deux emplacements, MLA-Mamba affiche systématiquement les erreurs de prédiction les plus faibles. Dans de nombreux cas, il réduit les erreurs typiques de 10 à 20 % par rapport à des références solides en apprentissage profond. Lorsqu’on désactive certaines parties du modèle dans des tests contrôlés — suppression de l’attention spatiale, substitution d’un LSTM standard au module Mamba, désactivation de l’optimiseur GRPO ou entraînement de chaque indicateur séparément — les performances se dégradent notablement. Cela montre que chaque ingrédient contribue aux gains observés.
Ce que cela signifie pour la protection des ressources en eau
En termes simples, l’étude démontre qu’un réseau neuronal hybride sur mesure peut fournir des prévisions à court terme de la pollution fluviale plus précises et plus fiables que les outils standards actuels. En suivant simultanément plusieurs polluants sur plusieurs stations et en quantifiant la confiance de ses propres prévisions, le cadre MLA-Mamba pourrait soutenir des systèmes d’alerte précoce déclenchant des inspections ou des mesures temporaires avant que les seuils ne soient dépassés. Si l’approche dépend encore de données de surveillance de bonne qualité et doit être testée sur davantage de rivières et d’événements extrêmes, elle offre une voie prometteuse vers une gestion des eaux de surface plus intelligente et fondée sur les données.
Citation: Wei, R., Chen, H. & Wang, H. Surface water quality prediction via an MLA-Mamba hybrid neural network with GRPO optimization. Sci Rep 16, 5845 (2026). https://doi.org/10.1038/s41598-026-36229-3
Mots-clés: prévision de la qualité de l'eau, pollution des rivières, apprentissage profond, modélisation spatio-temporelle, surveillance environnementale