Clear Sky Science · fr
Modélisation du contexte à longue portée pour la détection de vulnérabilités logicielles à l’aide d’une approche basée sur XLNet
Pourquoi les défauts cachés dans les logiciels comptent
La vie moderne dépend du logiciel, des services bancaires en ligne et des systèmes hospitaliers aux lecteurs vidéo et applications de messagerie. Pourtant, même des erreurs minimes dans le code peuvent ouvrir la porte aux attaquants, mettant en péril la confidentialité des données ou la disponibilité des services. Les spécialistes de la sécurité recourent de plus en plus à l’intelligence artificielle pour analyser des millions de lignes de code à la recherche de ces faiblesses. Cet article explore une nouvelle méthode basée sur l’IA, appelée XLNetVD, conçue pour repérer des vulnérabilités logicielles subtiles en lisant des portions de code bien plus larges que ce que peuvent gérer de nombreux outils existants.
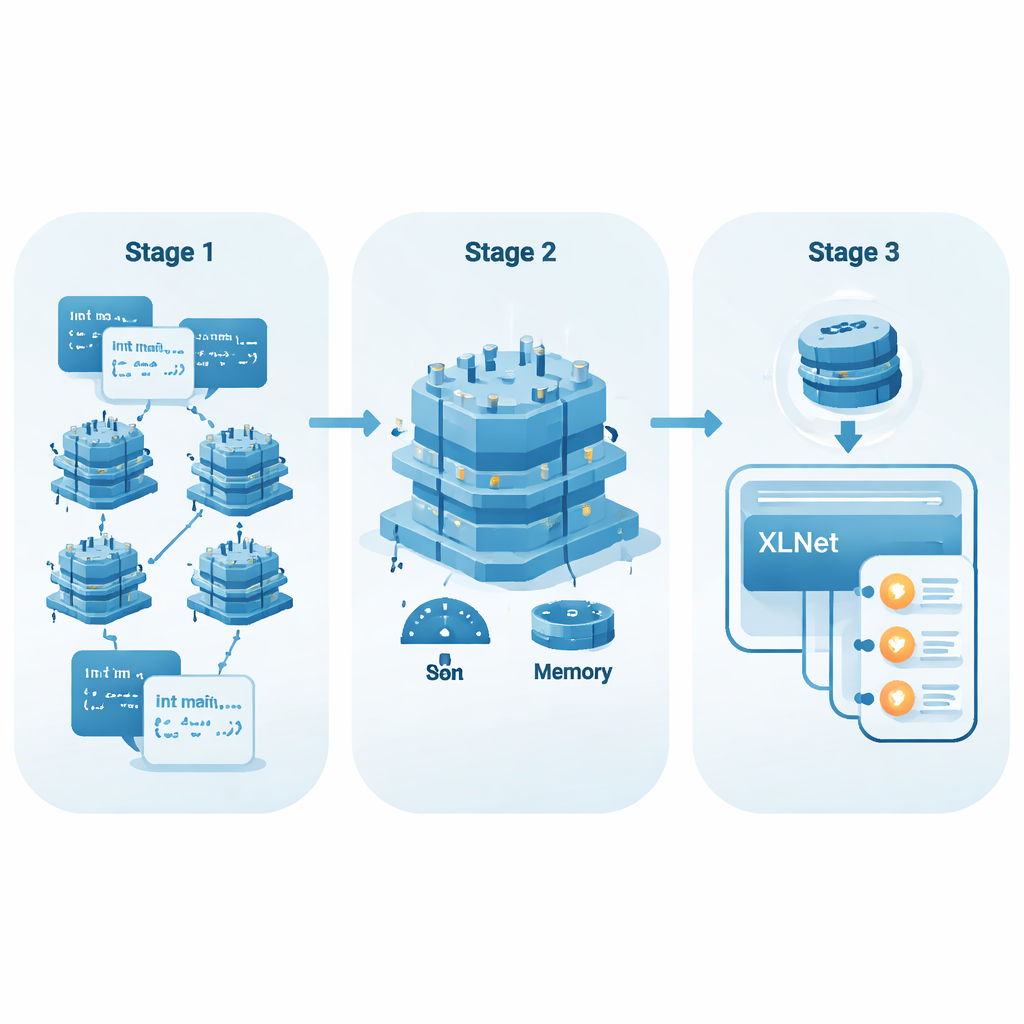
Des simples listes de mots à un code qui comprend le contexte
Les premières méthodes d’IA pour analyser le code considéraient chaque jeton — comme un nom de variable ou un symbole — presque comme un mot de dictionnaire avec un sens fixe. Des techniques comme Word2Vec ou GloVe apprenaient un vecteur par jeton, quel que soit son emplacement. Cela fonctionne raisonnablement bien pour le langage naturel, mais cela reste insuffisant pour les programmes, où un même nom de variable peut se comporter très différemment selon son usage et son contexte. Les modèles plus récents, appelés modèles d’encodage contextuel, analysent plutôt la fonction entière et adaptent la représentation de chaque jeton à son environnement. Ils peuvent ainsi détecter des motifs liés au flux de données, au contrôle d’exécution et aux dépendances entre variables — des motifs qui font souvent la différence entre un code sûr et un code vulnérable.
Permettre à l’IA de lire davantage du fichier
Des modèles de code populaires comme CodeBERT et GraphCodeBERT utilisent déjà cette approche contextuelle, mais limitent généralement leur « vue » à environ 512 jetons. Pour les fonctions longues, ou pour des vulnérabilités dont les indices sont distants dans le code, cette fenêtre peut être trop courte. Des vérifications importantes au début d’une fonction peuvent être coupées des opérations risquées plus loin. Les auteurs s’appuient plutôt sur XLNet, un modèle dérivé de Transformer-XL, qui peut conserver des informations d’un segment à l’autre et traiter confortablement des séquences plus longues (jusqu’à 768 jetons dans leurs expériences). Cela le rend mieux à même de relier des événements distants dans le code — par exemple, comprendre qu’une valeur a été validée plus tôt, ou réaliser qu’elle ne l’a jamais été.
Alléger et accélérer des modèles puissants
Les grands modèles d’IA exigent souvent du matériel puissant, ce qui limite leur emploi dans des environnements de développement quotidiens. Pour remédier à cela, les auteurs appliquent une méthode d’affinage appelée Low-Rank Adaptation (LoRA). Plutôt que de modifier la multitude de paramètres de XLNet, LoRA ajoute de petites couches d’adaptateurs, beaucoup moins coûteuses à entraîner et à stocker. L’équipe introduit un score simple, EffScore, qui met en balance les économies de mémoire et de temps avec toute perte éventuelle de qualité de détection. Sur plusieurs modèles de référence, XLNet avec LoRA apparaît comme la solution la plus efficace globalement, offrant une bonne précision tout en utilisant sensiblement moins de ressources.
Tests sur projets réels et synthétiques
Les chercheurs évaluent XLNetVD sur deux jeux de données très différents. L’un contient du code C réel provenant de 12 projets open source — comme des bibliothèques multimédia et des serveurs web — avec un ratio fortement déséquilibré d’environ 1 fonction vulnérable pour 65 non vulnérables, reflétant la réalité des grandes bases de code. L’autre est une collection synthétique équilibrée issue du projet SARD, où chaque fonction est conçue pour représenter un type de faiblesse connu. XLNetVD non seulement égale ou dépasse les systèmes d’apprentissage profond antérieurs et les outils classiques d’analyse statique sur ces tests, mais il performe aussi bien en contexte inter-projets, où il doit trouver des failles dans un projet qu’il n’a pas vu auparavant. Son avantage est particulièrement marqué pour les fonctions longues, où un contexte étendu est crucial, et pour une gamme de catégories de vulnérabilités, y compris les dépassements d’entiers, la mauvaise gestion des ressources et le traitement incorrect des entrées.
Ce que cela signifie pour la sécurité logicielle quotidienne
Pour un non-spécialiste, le message principal est que des IA plus intelligentes et sensibles au contexte peuvent lire et raisonner sur le code de manière proche d’un relecteur humain expérimenté, mais à l’échelle machine. En permettant au modèle de voir davantage de chaque fonction et en le réglant de manière efficace, XLNetVD offre un moyen pratique de prioriser les parties d’une immense base de code qui méritent une inspection humaine approfondie. Il ne remplace pas les audits de sécurité manuels ni les méthodes formelles, et ne garantit pas qu’un logiciel soit exempt de bugs. En revanche, il augmente sensiblement les chances de détecter tôt des erreurs dangereuses, même dans des projets inconnus, en faisant un composant prometteur pour une infrastructure numérique plus fiable et plus sûre.
Citation: Zhao, Y., Lin, G. & Liao, Z. Long-range context modeling for software vulnerability detection using an XLNet-based approach. Sci Rep 16, 5338 (2026). https://doi.org/10.1038/s41598-026-36196-9
Mots-clés: vulnérabilités logicielles, sécurité du code, apprentissage profond, XLNet, affinage LoRA