Clear Sky Science · fr
Algorithme DDPG priorisé modifié pour la synthèse conjointe du beamforming et l’optimisation de phase RIS dans les systèmes MISO en liaison descendante
Surfaces intelligentes pour la prochaine vague du sans fil
À mesure que nos téléphones, voitures et capteurs exigent des connexions toujours plus rapides et fiables, les réseaux sans fil actuels sont poussés à leurs limites. Cette étude explore une nouvelle façon de rendre les réseaux 6G futurs à la fois plus écologiques et plus fiables en combinant des surfaces réfléchissantes « intelligentes » sur les bâtiments avec une technique d’intelligence artificielle qui apprend, de manière autonome, à orienter les signaux radio en consommant moins d’énergie.
Transformer les murs en miroirs utiles pour le signal
Les systèmes 6G doivent à l’avenir desservir un grand nombre d’appareils avec des débits élevés, une fiabilité à toute épreuve et des latences très faibles. Répondre à toutes ces exigences avec uniquement des stations de base traditionnelles demanderait beaucoup de matériel supplémentaire et d’énergie. Les surfaces intelligentes reconfigurables (RIS) proposent une approche différente : des panneaux recouverts de nombreux éléments miniatures et basse consommation capables de réfléchir les ondes radio incidentes dans des directions contrôlées, comme un miroir programmable. En choisissant soigneusement les phases de ces réflexions, une RIS peut contourner les obstacles, renforcer des liaisons faibles et réduire les interférences, sans émettre d’énergie active. Cela donne aux concepteurs de réseaux un puissant levier pour étendre la couverture et améliorer l’efficacité.
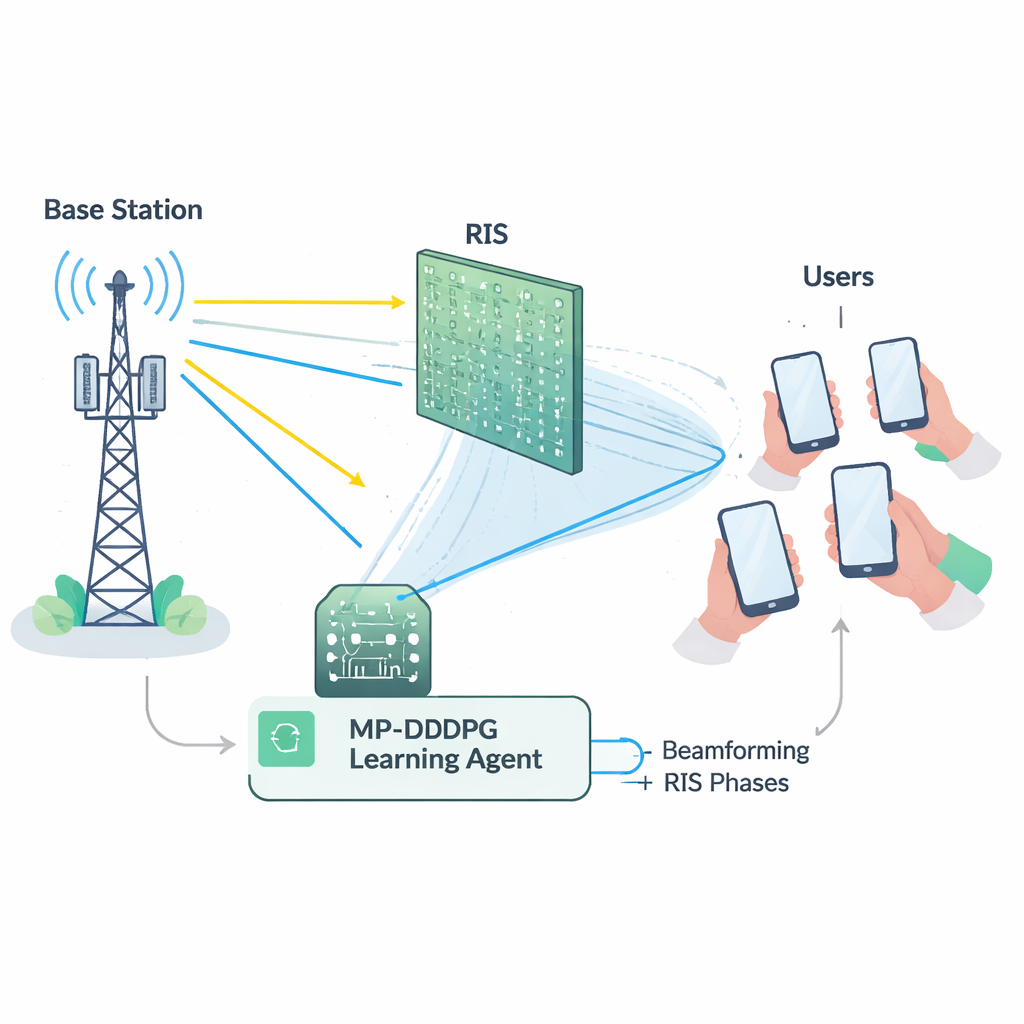
Un exercice d’équilibre difficile pour le réseau
Exploiter efficacement une RIS n’est pas simple. La station de base doit décider comment orienter ses antennes (beamforming), tandis que la RIS doit régler la phase de chacun de ses nombreux éléments réfléchissants. Ces choix sont étroitement liés et doivent respecter plusieurs contraintes à la fois : maintenir la puissance totale émise en dessous d’un maximum, garantir à chaque utilisateur une qualité de signal minimale et respecter les limites physiques du matériel RIS. Mathématiquement, ce problème d’ajustement conjoint est hautement non linéaire et « non convexe », ce qui fait que les outils d’optimisation classiques ont tendance à être lents, fragiles ou à se bloquer dans des solutions sous‑optimales, surtout à grande échelle. De plus, mesurer précisément l’état détaillé de chaque liaison radio (la fameuse information d’état de canal) est en soi coûteux et sujet à erreurs en conditions réelles.
Laisser un agent IA apprendre à former les faisceaux
Pour surmonter ces obstacles, les auteurs conçoivent un agent d’apprentissage basé sur le deep reinforcement learning, une branche de l’IA où un agent découvre de bonnes stratégies par essais et erreurs avec un environnement. Leur méthode, appelée Modified Prioritized Deep Deterministic Policy Gradient (MP‑DDPG), observe l’état actuel du réseau — orientations d’antenne précédentes, réglages RIS, puissance reçue et qualité du signal — puis choisit de nouvelles valeurs de beamforming et de phases RIS. Après chaque décision, il reçoit une récompense qui encourage simultanément trois objectifs : réduire la puissance d’émission, satisfaire les objectifs de qualité de service des utilisateurs et respecter la limite de puissance de la station de base. Au fil de nombreuses interactions simulées, l’agent apprend progressivement une politique de contrôle qui équilibre ces objectifs sans se voir fournir explicitement de formule pour le canal radio.
Apprendre plus vite en se concentrant sur l’essentiel
L’innovation clé réside dans la façon dont l’algorithme apprend de son expérience passée. Les approches classiques stockent de nombreux épisodes passés et les échantillonnent au hasard pendant l’entraînement, ce qui peut être inefficace et lent. MP‑DDPG attribue à la place à chaque expérience stockée une priorité qui dépend à la fois de sa récompense et de la différence de son état par rapport à ses voisins les plus proches. Les expériences à la fois informatives et diversifiées sont échantillonnées plus souvent, tandis que les redondantes sont ignorées. Cette « relecture priorisée modifiée » rend chaque étape d’apprentissage plus utile, accélère la convergence et aide l’agent à éviter des minima locaux de mauvaise qualité. Les auteurs analysent aussi le surcoût computationnel induit et montrent que, bien que la gestion soit plus complexe que dans la méthode de base, l’apprentissage plus rapide compense largement ce coût en pratique.
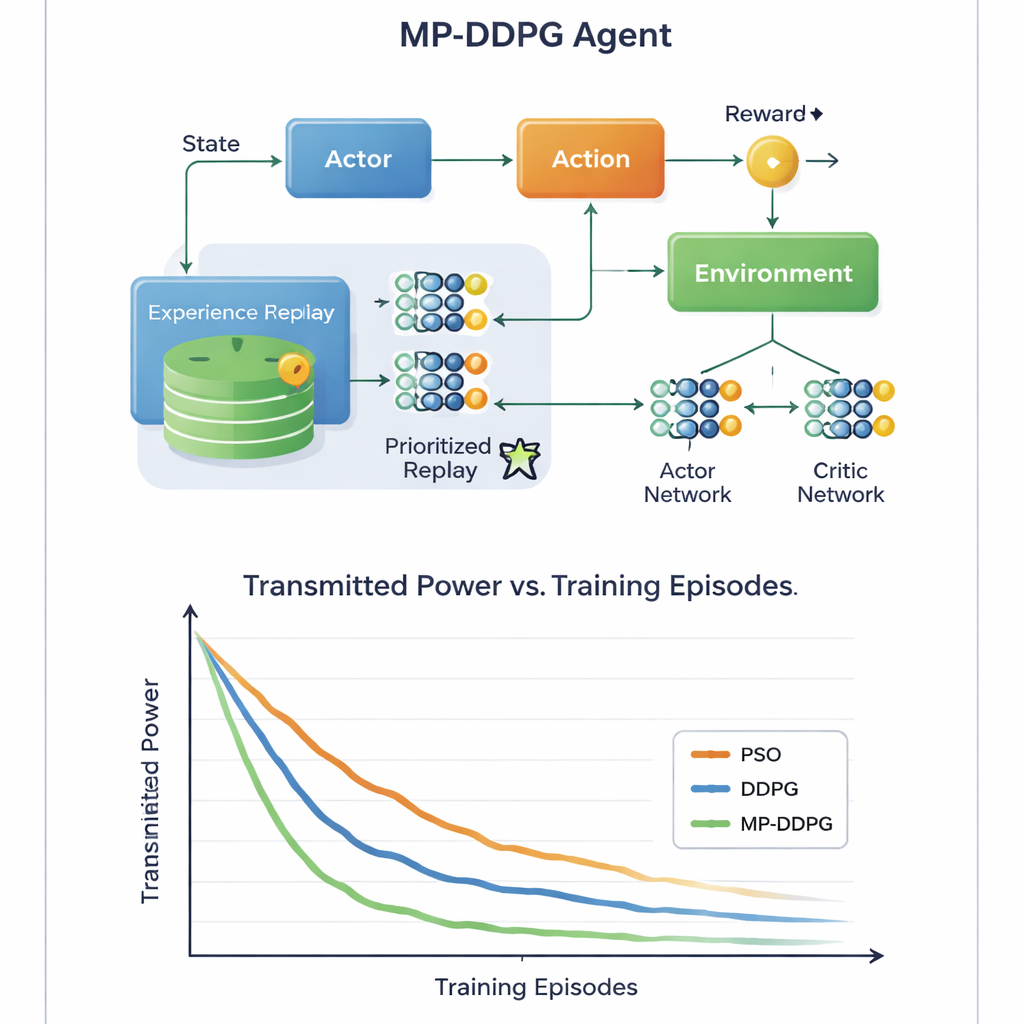
Des signaux plus écologiques avec moins de matériel
À travers des simulations informatiques détaillées d’un scénario cellulaire en liaison descendante, l’étude compare MP‑DDPG à deux alternatives : une méthode d’optimisation par essaim de particules traditionnelle et l’algorithme DDPG original. La nouvelle méthode atteint systématiquement une puissance d’émission plus faible en moins d’épisodes d’entraînement, et ce en utilisant moins d’éléments RIS et moins d’antennes de station de base pour le même niveau de performance. En termes simples, le réseau apprend à extraire davantage d’avantage de chaque carreau réfléchissant et de chaque antenne. Pour le lecteur non spécialiste, le message est que, en laissant un contrôleur IA régler intelligemment à la fois les faisceaux de la station de base et les surfaces intelligentes sur les façades, les réseaux 6G futurs pourraient fournir des signaux puissants et fiables en consommant moins d’énergie et de matériel, contribuant ainsi à rendre notre monde de plus en plus connecté plus durable.
Citation: Shukry, S., Fahmy, Y. Modified prioritized DDPG algorithm for joint beamforming and RIS phase optimization in MISO downlink systems. Sci Rep 16, 5942 (2026). https://doi.org/10.1038/s41598-026-36179-w
Mots-clés: surface intelligente reconfigurable, réseaux sans fil 6G, apprentissage profond par renforcement, optimisation du beamforming, réseaux économes en énergie