Clear Sky Science · fr
Prédiction par apprentissage automatique de l’addiction alimentaire chez les étudiants universitaires à partir de données démographiques, anthropométriques et de traits de personnalité
Pourquoi notre relation à la nourriture peut sembler hors de contrôle
Beaucoup de personnes plaisantent en se disant « accros » au chocolat ou à la restauration rapide, mais pour certains, les envies et la perte de contrôle autour de l’alimentation sont graves et source de détresse. Les étudiants universitaires sont particulièrement vulnérables, confrontés au stress, à de nouvelles libertés et à des changements corporels. Cette étude pose une question d’actualité : des programmes informatiques peuvent‑ils apprendre à repérer quels étudiants présentent un risque plus élevé d’addiction alimentaire, en s’appuyant sur des informations simples sur leurs antécédents, leurs mesures corporelles et leur personnalité ? Si oui, on pourrait à terme détecter les problèmes plus tôt et adapter le soutien avant que les habitudes alimentaires ne se transforment en problèmes de santé durables.
Examiner les étudiants sous plusieurs angles
Les chercheurs ont travaillé avec 210 étudiants universitaires à Ahvaz, en Iran, âgés de 18 à 35 ans. Chaque étudiant a fourni des informations de base telles que l’âge et le niveau d’études, a indiqué sa taille et son poids afin que l’indice de masse corporelle (IMC) puisse être calculé, et a rempli un questionnaire standard de personnalité. Ils ont également été évalués avec une version brève de la Yale Food Addiction Scale, qui classe si une personne présente des schémas d’addiction vis‑à‑vis d’aliments très agréables, tels que des envies intenses, des tentatives ratées de réduire la consommation, ou la poursuite de la consommation malgré des conséquences négatives. Seuls 30 étudiants répondaient aux critères d’addiction alimentaire, tandis que 180 ne les remplissaient pas, reflétant que ces problèmes touchent une part limitée de la population.
Équilibrer des données inégales et entraîner des machines intelligentes
Parce qu’un bien plus petit nombre d’étudiants était classé comme dépendant de la nourriture, l’ensemble de données était déséquilibré. Ce déséquilibre peut tromper les modèles informatiques en les incitant principalement à prédire le groupe majoritaire et à ignorer la minorité à haut risque. Pour contrer cela, l’équipe a utilisé deux astuces de traitement des données. D’abord, elle a appliqué une méthode appelée Tomek Links pour supprimer soigneusement les cas du groupe majoritaire trop proches des cas minoritaires et susceptibles de créer de la confusion. Ensuite, elle a utilisé SMOTE, qui génère des exemples synthétiques réalistes du groupe minoritaire, pour rééquilibrer les effectifs. Seuls les jeux de données d’entraînement ont été modifiés de cette manière ; un groupe de test séparé et intact a été conservé pour vérifier la performance des modèles sur de nouveaux étudiants non vus.
Tester de nombreux algorithmes
Les chercheurs ne se sont pas appuyés sur une seule recette mathématique. Ils ont comparé dix modèles d’apprentissage automatique différents, allant de méthodes simples comme la régression logistique et les k plus proches voisins à des méthodes « d’ensemble » plus avancées telles que Random Forest, Gradient Boosting, LightGBM et CatBoost. Ils ont également testé douze stratégies de sélection de caractéristiques pour déterminer quelles questions et mesures étaient les plus informatives, et ont utilisé la validation croisée et des recherches automatisées pour ajuster les paramètres de chaque modèle. Les performances globales ont été jugées à l’aide de plusieurs mesures, y compris la précision (à quelle fréquence le modèle a raison), le score F1 (un équilibre entre identifier les vrais cas sans trop d’alarmes fausses) et l’aire sous la courbe ROC, qui capture la capacité d’un modèle à séparer les individus à risque plus élevé de ceux à risque plus faible.
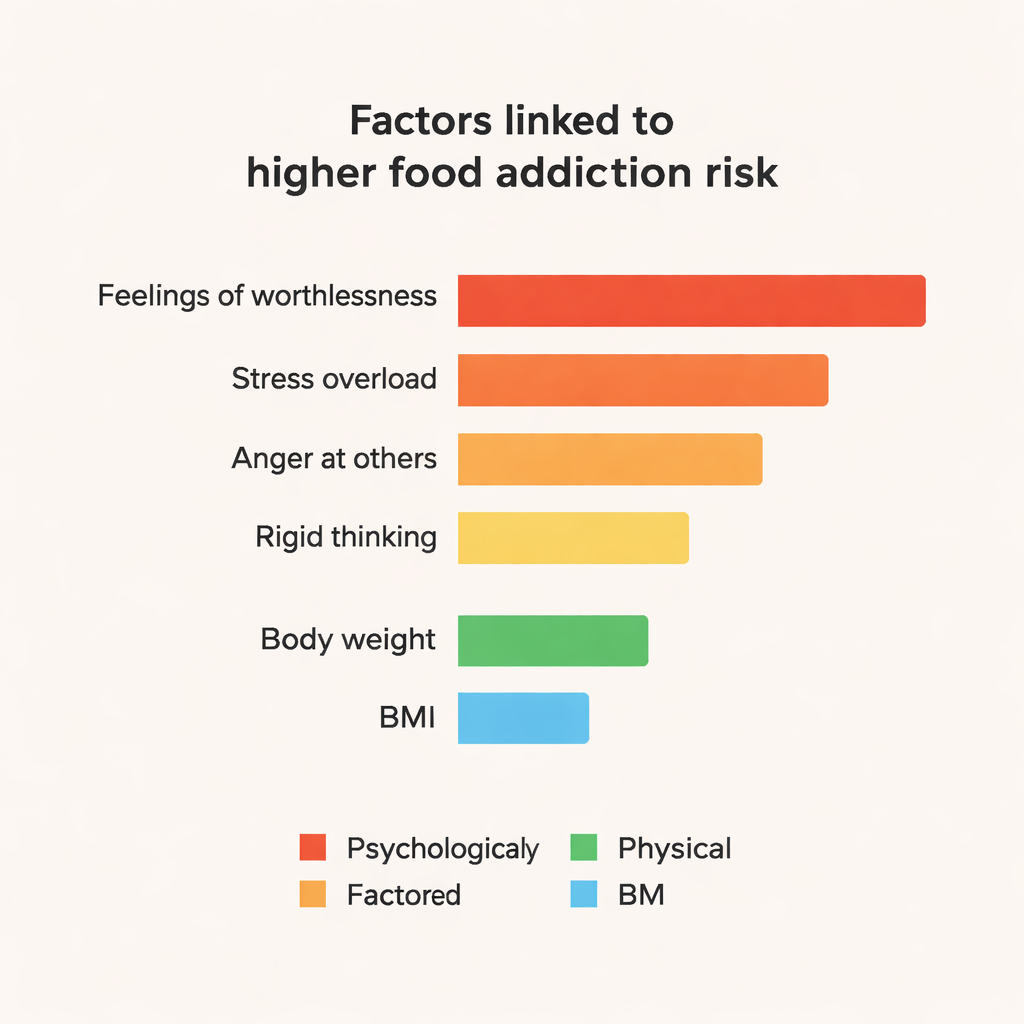
Ce qui pilote les prédictions en coulisses
Les modèles d’ensemble, en particulier CatBoost et Random Forest, ont systématiquement surpassé les approches plus simples, atteignant environ 84 % de précision et des scores F1 proches de 0,84 dans cet ensemble de petite taille. Pour dépasser les prédictions en « boîte noire », l’équipe a utilisé un outil appelé SHAP pour explorer quelles caractéristiques poussaient le modèle à qualifier quelqu’un d’addict à la nourriture. Les influences marquantes étaient psychologiques : des affirmations fortes telles que « Parfois je me sens complètement sans valeur », le sentiment de « m’effondrer » sous le stress, de fréquentes colères liées au comportement des autres, la tension émotionnelle et une pensée rigide et inflexible. Le poids corporel et l’IMC comptaient aussi, mais étaient moins centraux que ces signaux liés aux émotions et à la personnalité. Des traits associés à une humeur positive et à une bonne organisation exerçaient un effet légèrement protecteur.
Ce que cela signifie pour la vie quotidienne
Pour le lecteur moyen, le message clé est que l’addiction alimentaire ne se résume pas à un manque de volonté ou à l’appréciation de snacks savoureux. Dans ce groupe pilote d’étudiants, des difficultés émotionnelles profondes — faible estime de soi, difficultés à gérer le stress et relations tendues — étaient étroitement liées aux comportements alimentaires problématiques. Des versions initiales d’outils d’apprentissage automatique, alimentées par des questionnaires simples et des mesures corporelles, ont été capables de repérer ces schémas avec une précision encourageante. Cependant, les auteurs soulignent que leur échantillon était petit, basé sur des auto‑déclarations et issu d’une seule université, donc les résultats restent préliminaires. Avec des études plus larges et plus diversifiées, des modèles similaires pourraient finalement être utilisés en complément des évaluations cliniques standard pour signaler les jeunes susceptibles de bénéficier d’un accompagnement visant à mieux gérer à la fois leurs émotions et leurs habitudes alimentaires.
Citation: Rahimnezhad, A., Mortazavi, S.T., Behdarvand, Y. et al. Machine learning prediction of food addiction in university students using demographic, anthropometric and personality traits. Sci Rep 16, 6745 (2026). https://doi.org/10.1038/s41598-026-36162-5
Mots-clés: addiction alimentaire, étudiants universitaires, traits de personnalité, apprentissage automatique, alimentation émotionnelle