Clear Sky Science · fr
Prédiction d’un indice de qualité de l’eau via un modèle d’apprentissage automatique robuste utilisant des indices liés à l’oxygène pour la surveillance de la qualité des eaux fluviales
Pourquoi l’oxygène des rivières concerne tout le monde
Les rivières propres ne sont pas de simples décors pittoresques ; elles constituent des sources d’eau potable, des axes d’irrigation et des habitats pour les poissons et la faune. Pourtant, de nombreuses rivières dans le monde suffoquent progressivement à mesure que la pollution réduit l’oxygène dissous. Cette étude présente une nouvelle manière, plus intelligente, de surveiller la santé des cours d’eau en utilisant quelques mesures liées à l’oxygène et l’apprentissage automatique pour prédire un score de qualité de l’eau facile à comprendre. L’objectif est d’offrir aux collectivités et aux décideurs un outil rapide et fiable pour détecter les problèmes avant que les rivières n’atteignent un point de crise.
Un score simple pour une rivière complexe
Les scientifiques de l’eau condensent souvent des dizaines de mesures chimiques et biologiques en un seul indice de qualité de l’eau, ou IQE. Ce score permet aux non-spécialistes de savoir en un coup d’œil si l’eau est excellente, bonne, moyenne ou mauvaise. Cependant, de nombreuses versions de l’IQE prennent en compte l’oxygène de façon indirecte ou n’exploitent pas pleinement son rôle central pour la vie aquatique. L’oxygène indique si les poissons peuvent respirer, si les micro-organismes dégradent les déchets, et si une rivière peut se rétablir après un épisode de pollution. Les auteurs soutiennent qu’un indice plus intelligent devrait s’appuyer principalement sur les informations liées à l’oxygène, qui sont largement mesurées et directement liées à la survie des écosystèmes fluviaux.
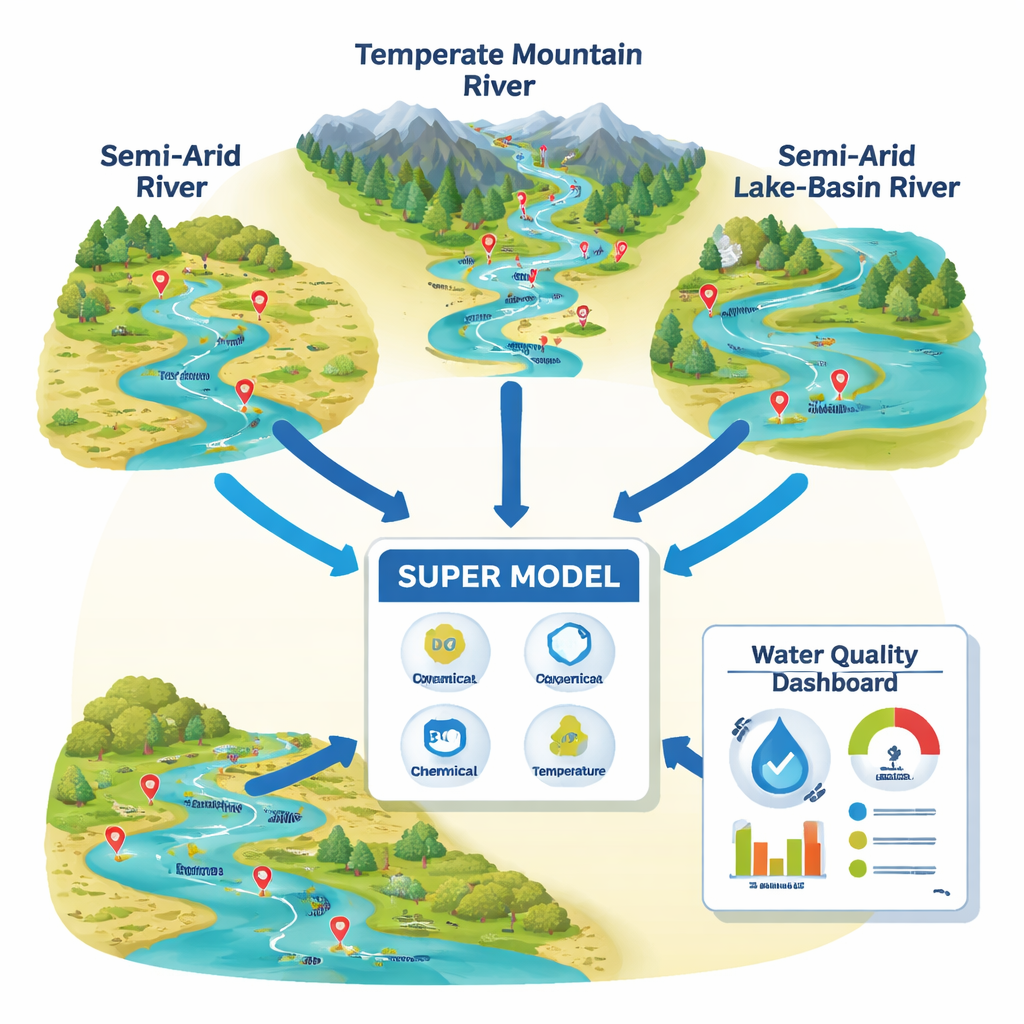
Observation de trois rivières très différentes
Pour tester cette idée, les chercheurs se sont concentrés sur trois rivières contrastées en Iran. L’une traverse un bassin chaud semi-aride avec de grandes variations de température ; une autre descend froide et rapide d’une région montagneuse près de la mer Caspienne ; la troisième se jette dans le lac Ourmia, soumis à des pressions environnementales. Ensemble, elles couvrent des tronçons clairs et bien oxygénés ainsi que des zones plus troubles et stressées par l’agriculture, les villes et l’industrie. À des dizaines de stations le long de ces rivières, des équipes ont mesuré des paramètres de terrain de base tels que la température, l’oxygène dissous, l’acidité et la conductivité électrique, et ont prélevé des échantillons pour analyser en laboratoire la pollution organique, les sédiments en suspension, les nutriments et les bactéries.
Apprendre à un « super-modèle » à lire l’eau
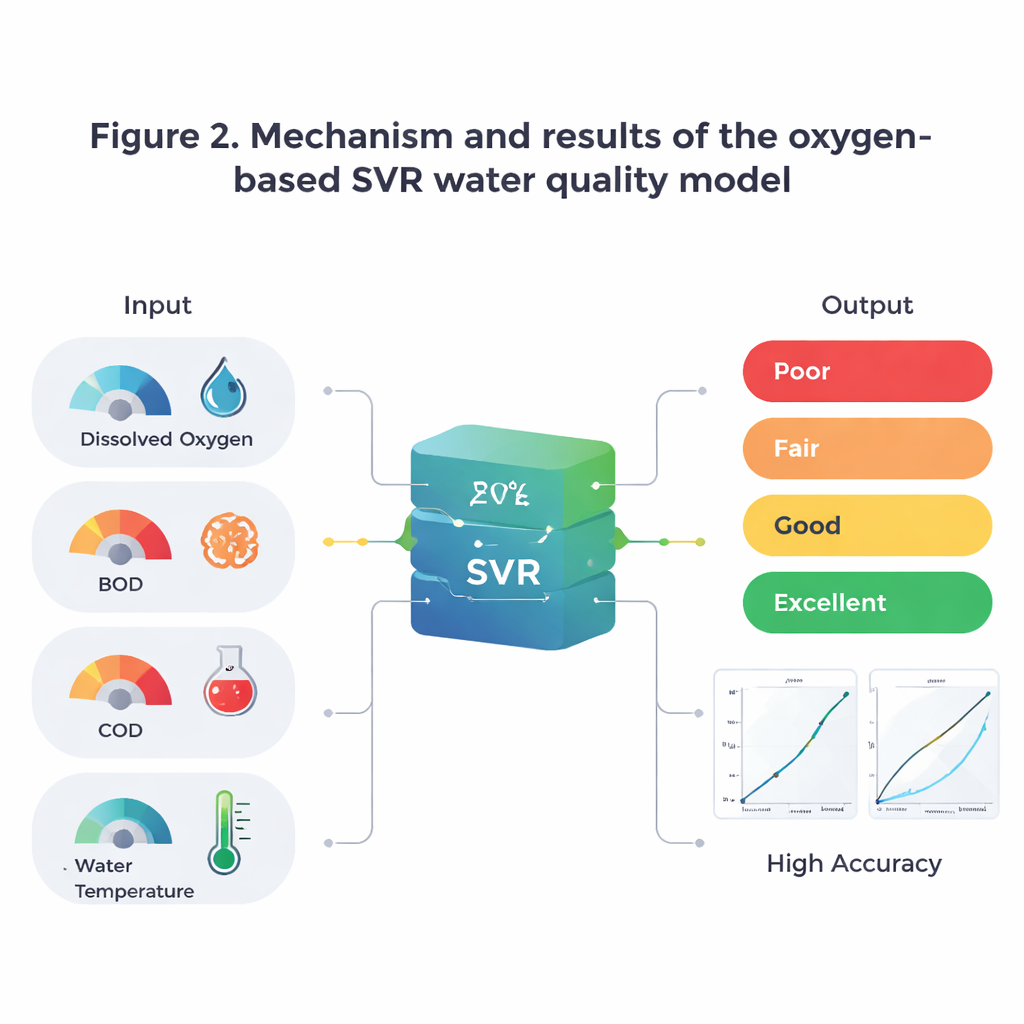
À partir de cet ensemble de données riche, les auteurs ont construit ce qu’ils appellent un « super-modèle » en utilisant une technique d’apprentissage automatique connue sous le nom de Support Vector Regression. Plutôt que d’alimenter l’algorithme avec toutes les données chimiques disponibles, ils se sont concentrés sur un petit ensemble d’indicateurs liés à l’oxygène : oxygène dissous, demande biologique en oxygène, demande chimique en oxygène et température de l’eau. Ces mesures captent la quantité d’oxygène présente, la vitesse à laquelle il est consommé par la pollution organique et chimique, et la manière dont la température accélère ou ralentit ces processus. Le modèle a été entraîné pour prédire un nouvel indice de qualité de l’eau basé sur l’oxygène, WQIOIs, qui reflète les scores traditionnels de l’IQE mais est principalement piloté par ces signaux oxygène centraux.
Vérifier la précision, la généricité et la transparence
L’équipe a ensuite posé trois questions clés : quelle est la précision du modèle, quelle est sa généricité, et peut-on comprendre ses décisions ? D’abord, ils ont montré que le modèle prédit très bien les WQIOIs, avec plus de 95 % de la variation expliquée et des erreurs moyennes très faibles. Ensuite, testé sur des rivières qu’il n’avait jamais « vues » durant l’entraînement, le modèle correspondait toujours étroitement à un indice conventionnel plus complexe qui utilise de nombreuses mesures supplémentaires. Cela suggère qu’un petit nombre d’indicateurs oxygène soigneusement choisis peut remplacer un bilan de laboratoire complet. Troisièmement, les auteurs ont utilisé une méthode d’interprétabilité appelée SHAP pour jeter un coup d’œil à l’intérieur de la logique du modèle. L’analyse a confirmé qu’un oxygène dissous élevé augmente fortement le score de qualité, tandis qu’une température élevée et une pollution organique importante l’abaisse, ce qui reflète une compréhension écologique bien établie plutôt que des bizarreries cachées dans les données.
Des chiffres aux alertes en temps réel
Au-delà des tests techniques, l’étude explore comment cet outil pourrait fonctionner en pratique. En regroupant les conditions fluviales en catégories telles que « Froid et sain » ou « Chaud et appauvri en oxygène », les gestionnaires peuvent voir quand une rivière entre dans un état à risque, par exemple durant les faibles débits estivaux lorsque l’eau chaude contient moins d’oxygène. Le modèle classe également les échantillons de sorte qu’un petit nombre de mesures peut signaler la plupart des sites réellement impactés, ce qui est vital lorsque les budgets et les équipes sont limités. Parce que les mesures requises sont peu coûteuses et largement disponibles, le même cadre pourrait être intégré à des tableaux de bord simples ou à des systèmes d’alerte précoce dans de nombreuses régions, y compris celles disposant de capacités de laboratoire limitées.
Ce que cela signifie pour les rivières et les populations
En termes concrets, l’étude montre que nous pouvons évaluer très précisément la santé d’une rivière en observant sa « respiration ». Un ensemble compact de tests liés à l’oxygène, interprété par un modèle d’apprentissage automatique soigneusement entraîné, peut égaler les performances de dispositifs de surveillance bien plus compliqués et coûteux. Cela signifie un suivi de la pollution plus rapide et moins onéreux, une meilleure planification des inspections et des opérations de nettoyage, et une communication plus claire au public sur la sécurité d’une rivière pour les poissons, l’agriculture ou les loisirs. À mesure que des modèles similaires se diffusent et sont adaptés à d’autres régions, ils pourraient devenir l’épine dorsale d’une protection fluviale en temps réel et fondée sur les données à l’échelle mondiale.
Citation: Arzhangi, A., Partani, S. Water quality index prediction via a robust machine learning model using oxygen-related indices for river water quality monitoring. Sci Rep 16, 6102 (2026). https://doi.org/10.1038/s41598-026-36156-3
Mots-clés: qualité des eaux fluviales, oxygène dissous, indice de qualité de l’eau, apprentissage automatique, surveillance environnementale