Clear Sky Science · fr
Intégration de l’optimisation et de l’apprentissage automatique pour estimer la résistivité de l’eau et la saturation dans des réservoirs de sables argileux
Pourquoi c’est important pour l’énergie et l’environnement
Les compagnies pétrolières et gazières s’appuient sur des mesures effectuées dans un puits pour décider où se trouvent les hydrocarbures et si un gisement mérite d’être développé. Dans de nombreux réservoirs, en particulier ceux riches en argile et en limon, ces mesures sont notoirement difficiles à interpréter, si bien que les ingénieurs peuvent sous-estimer la quantité réelle de pétrole ou de gaz présente. Cette étude présente une nouvelle méthode pour extraire des informations plus fiables de données existantes en combinant optimisation fondée sur la physique et apprentissage automatique moderne, ce qui pourrait améliorer la récupération tout en réduisant le besoin d’échantillons de carottes coûteux.
Le problème des roches chargées d’argile
Beaucoup des réservoirs d’hydrocarbures dans le monde sont des « sables argileux » – des mélanges de grains de sable, de fluides de porosité et de minéraux argileux conducteurs. Ces argiles déforment les mesures électriques utilisées pour estimer quelle part de l’espace poreux est remplie d’eau plutôt que d’hydrocarbures. Les outils et graphiques classiques, développés pour des sables plus propres, partent de l’hypothèse de structures rocheuses simples et d’une faible teneur en argile. Dans les sables argileux, ces hypothèses s’effondrent, donnant souvent l’impression que les roches sont plus humides qu’elles ne le sont réellement, et conduisant les ingénieurs à écarter des intervalles qui peuvent en fait contenir des quantités significatives de pétrole ou de gaz.
Transformer des mesures rares en une ancre solide
Les auteurs s’attaquent à une grandeur centrale appelée résistivité de l’eau de formation, qui décrit la conductivité électrique de l’eau dans les pores. Si cette valeur est erronée, toutes les estimations ultérieures de saturation en eau sont biaisées. Plutôt que de se fier à quelques mesures en laboratoire ou à des méthodes graphiques subjectives, ils formulent le problème comme une tâche d’optimisation : trouver la valeur unique de résistivité de l’eau qui permet à un modèle physique de sable argileux de mieux reproduire la résistivité mesurée le long du puits. Ils testent plusieurs algorithmes de recherche et montrent que des méthodes simples sans dérivées, telles que Powell et Nelder–Mead, peuvent retrouver la résistivité d’eau réelle avec une erreur extrêmement faible, lorsqu’on les compare aux données de carottes et d’échantillons d’eau provenant de 11 puits en mer du Nord norvégienne et dans le désert occidental égyptien.
Créer un « pseudo-carottage » continu pour l’apprentissage automatique
Une fois cette résistivité d’eau optimisée obtenue, le même modèle physique est utilisé pour calculer un profil continu de saturation en eau le long de chaque puits. Ce profil est traité comme une étiquette de haute qualité, informée par la physique – une sorte de « pseudo-carottage » – qui existe à chaque profondeur, et pas seulement à quelques intervalles échantillonnés. Les chercheurs alimentent ensuite des diagraphies standards, telles que le gamma, la porosité neutronique, la densité et la résistivité profonde, dans une large gamme de modèles d’apprentissage automatique. Ceux-ci comprennent des ensembles d’arbres (Random Forest, XGBoost, CatBoost), des machines à vecteurs de support et plusieurs architectures de réseaux neuronaux, y compris un réseau récurrent spécial appelé LSTM capable de reconnaître des motifs évoluant avec la profondeur. Un prétraitement soigneux, un filtrage des valeurs aberrantes et une normalisation contribuent à garantir que les modèles apprennent des relations géologiques réelles plutôt que du bruit.
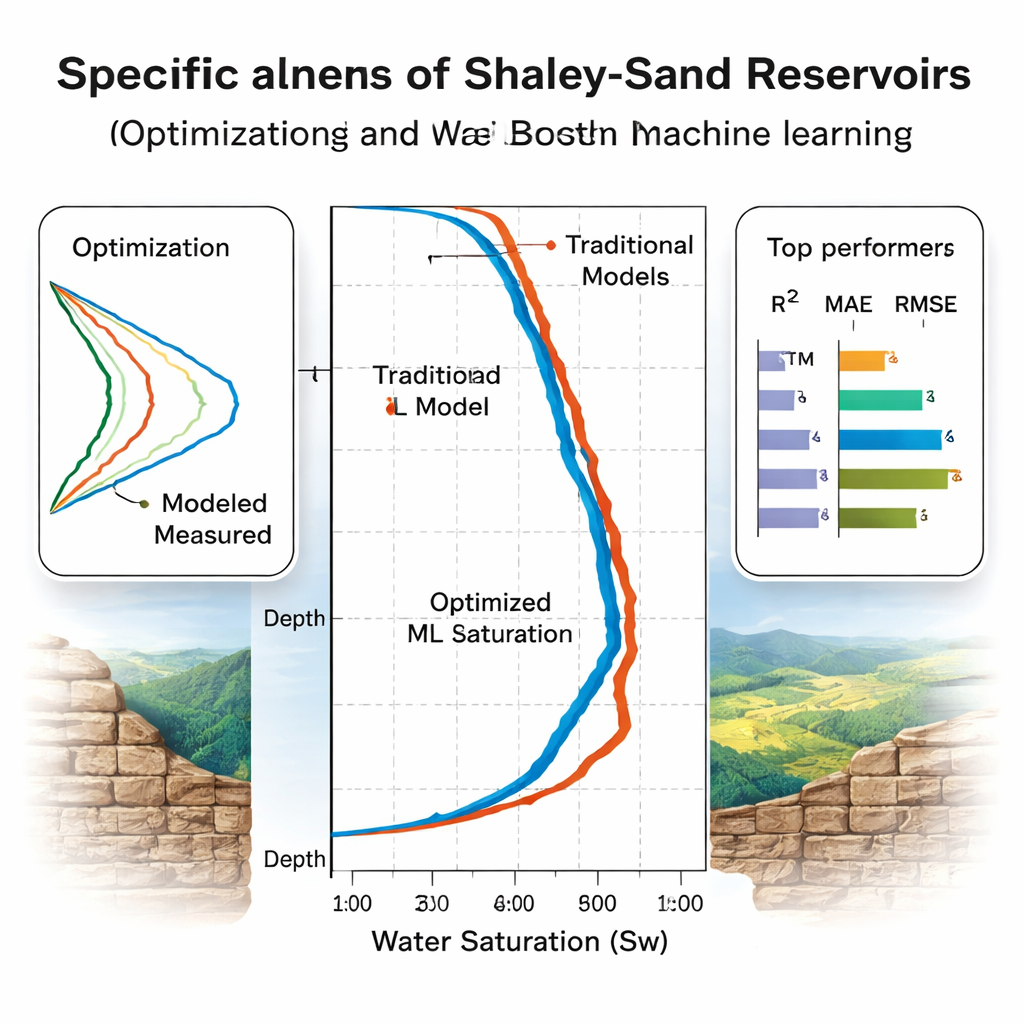
Quels modèles se généralisent vraiment ?
L’équipe évalue les modèles en deux étapes. D’abord, elle utilise une validation croisée à cinq plis sur huit puits de la mer du Nord pour les ajuster et les classer, constatant que Random Forest semble l’emporter selon les mesures d’exactitude standard. Vient ensuite le test le plus révélateur : trois puits « aveugles », dont deux provenant d’un bassin égyptien géologiquement différent qui n’ont jamais servi à l’entraînement. Là, certains modèles flanchent. La performance de Random Forest chute, signalant un surapprentissage vis-à-vis du bassin d’origine. En revanche, les arbres à gradient (CatBoost et XGBoost) ainsi que les réseaux LSTM et les réseaux neuronaux régularisés bayésiennement conservent une précision élevée, expliquant plus de 93–94 % de la variation de la saturation en eau avec des erreurs modestes. Une analyse de l’importance des caractéristiques via SHAP, un outil moderne d’interprétabilité, confirme que les modèles s’appuient principalement sur des entrées physiquement sensées comme la résistivité, la porosité et le volume d’argile.
Ce que cela signifie en termes simples
Pour les non-spécialistes, l’idée clé est que les auteurs utilisent d’abord la physique pour clarifier et ancrer le problème, puis seulement après appliquent l’apprentissage automatique. En laissant une routine d’optimisation trouver la résistivité d’eau la mieux ajustée puis en transformant cela en un jeu d’entraînement dense et respectueux des lois physiques, ils évitent le goulot d’étranglement habituel des données de carottes rares et coûteuses. Leurs résultats montrent que cette approche « optimisation d’abord, ML ensuite » peut fournir des estimations fiables de la fraction d’un réservoir argileux remplie d’eau par rapport aux hydrocarbures, même dans de nouveaux bassins non utilisés pour l’entraînement. En termes pratiques, cela peut aider les opérateurs à cartographier les zones productives plus fiablement, réduire les carottages inutiles et améliorer les estimations d’hydrocarbures en place — le tout en tirant plus intelligemment parti des données qu’ils collectent déjà.
Citation: Hameedy, M.A.E., Mabrouk, W.M. & Metwally, A.M. Integrating optimization and machine learning for estimating water resistivity and saturation in shaley sand reservoirs. Sci Rep 16, 6342 (2026). https://doi.org/10.1038/s41598-026-36133-w
Mots-clés: réservoirs de sables argileux, saturation en eau, résistivité de l’eau de formation, apprentissage automatique en pétrophysique, caractérisation des réservoirs