Clear Sky Science · fr
Fusion spatio-temporelle des caractéristiques guidée par l'attention pour une détection d'anomalies robuste en vidéosurveillance
Pourquoi des caméras plus intelligentes comptent
Des gares très fréquentées aux centres commerciaux, la vie moderne est remplie de caméras de sécurité qui enregistrent silencieusement tout ce qui se passe. Pourtant, la plupart de ces vidéos sont encore examinées — si elles le sont — par des yeux humains fatigués qui peuvent facilement manquer un moment crucial. Cet article explore un nouveau type de système de surveillance « intelligent » capable de repérer automatiquement, en temps réel, des comportements inhabituels ou à risque, comme le vol ou le vandalisme, en comprenant à la fois ce qui apparaît dans une scène et comment cela évolue dans le temps.

Voir plus que des pixels
Un flux de caméra traditionnel n'est qu'une séquence d'images. Les systèmes informatiques plus anciens tentaient de détecter des problèmes en analysant chaque image séparément, à la recherche de formes et de contours ressemblant à des personnes ou des objets. Les auteurs testent d'abord une version moderne de cette idée qui utilise un réseau compact de reconnaissance d'images combiné à des détecteurs de contours classiques. Cette configuration fonctionne assez bien dans des scènes bien cadrées, notamment pour repérer des indices visuels nets comme quelqu'un qui saisit un objet. Mais parce qu'elle se concentre sur des instantanés isolés, elle peine lorsque des personnes se masquent mutuellement, lorsque la foule devient dense, ou quand une même posture peut signifier un comportement normal ou suspect selon son déroulé dans le temps.
Comprendre le mouvement et le comportement
Pour saisir l'histoire derrière une action, et pas seulement l'apparence d'une image unique, l'étude évalue ensuite un modèle centré sur la vidéo qui analyse de courts extraits plutôt que des images fixes. Ce modèle apprend comment le mouvement se propage sur plusieurs images et peut mieux identifier des changements soudains comme la course, les violences ou les attroupements rapides. Il s'avère performant pour détecter de nombreux événements anormaux, ce qui conduit à une grande sensibilité. Cependant, il souffre aussi d'un problème classique du monde réel : les événements véritablement inhabituels sont rares par rapport aux activités courantes. En conséquence, le modèle peut devenir instable, générer trop de fausses alertes et nécessiter des segments vidéo soigneusement découpés qui ne reflètent pas la nature continue et désordonnée des images de surveillance réelles.
Mêler le où et le quand
S'appuyant sur les forces et les faiblesses de ces deux références, les auteurs proposent un nouveau système hybride appelé HybridModel-1 qui vise à « penser » simultanément en espace et en temps. Il combine un réseau très performant pour comprendre quels objets sont présents dans chaque image avec un détecteur rapide qui localise ces objets dans la scène. Un module de fusion spécial apprend à mettre en avant les détails visuels les plus informatifs — comme les personnes et les objets clés — tout en atténuant le désordre de fond comme les murs, les arbres ou les voitures de passage. Parallèlement, une nouvelle stratégie d'entraînement punit modérément le système chaque fois que sa confiance varie trop d'une image à l'autre, l'incitant à produire des décisions plus douces et plus cohérentes sur l'ensemble d'une vidéo.
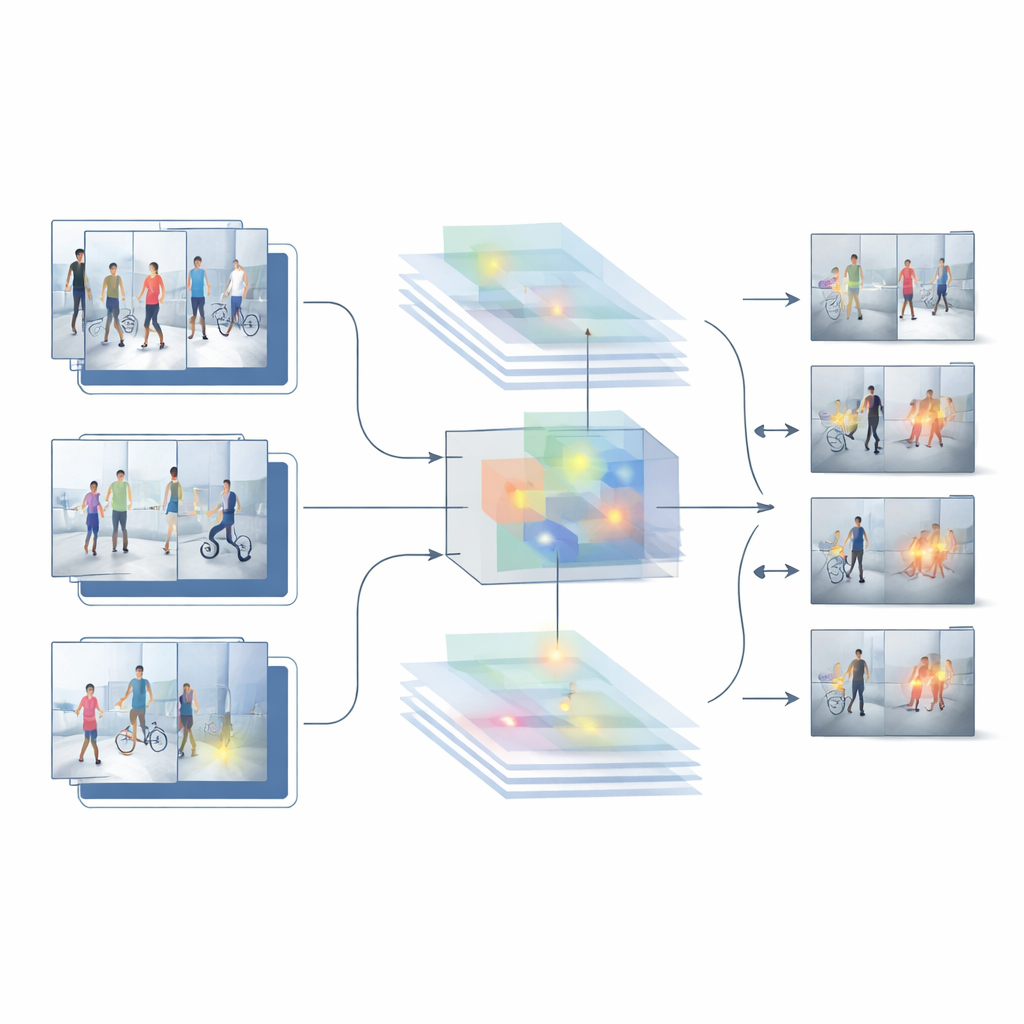
Mettre le système à l'épreuve
Pour vérifier si ce dispositif fonctionne en dehors du laboratoire, les chercheurs le testent sur plusieurs jeux de données publics difficiles composés de séquences de surveillance réelles. Ces collections comprennent tout, des scènes de vols en intérieur aux allées extérieures d'un campus, avec des positions de caméras, des éclairages, des densités de foule et des types d'incidents variés. Sur ces benchmarks, le modèle hybride surpasse à la fois les approches basées uniquement sur l'image et celles basées uniquement sur la vidéo. Il obtient une précision globale supérieure, génère beaucoup moins de fausses alertes et conserve de bonnes performances même lorsqu'il est évalué sur des séquences sur lesquelles il n'a pas été entraîné. Des comparaisons détaillées et des études d'ablation — où des éléments du système sont retirés ou modifiés — montrent que le module de fusion des caractéristiques et l'étape d'entraînement favorisant la régularité contribuent chacun de manière significative à ces gains.
Ce que cela signifie pour la sécurité au quotidien
En termes simples, ce travail montre que les systèmes de surveillance deviennent plus fiables lorsqu'ils apprennent à prêter attention aux bonnes parties d'une scène et à rester stables dans leurs jugements au fil du temps. Plutôt que de traiter chaque image comme un instantané isolé ou de se fier uniquement au mouvement brut, l'approche proposée mêle le « quoi » et le « quand » dans un même cadre finement réglé. Si des défis demeurent dans des vues extrêmement sombres ou fortement obstruées, les résultats suggèrent une voie pratique vers des réseaux de caméras capables d'analyser discrètement de vastes quantités de vidéo, de faire ressortir les événements réellement suspects et de réduire le fardeau des fausses alertes pour les opérateurs humains. Pour le public, cela pourrait signifier des espaces plus sûrs surveillés par des systèmes qui ne se contentent pas de regarder, mais comprennent réellement ce qu'ils voient.
Citation: Nivethika, S.D., Joshi, S., Verma, K. et al. Attention-guided saptio-temporal feature fusion for robus video surveillance anomaly detection. Sci Rep 16, 8027 (2026). https://doi.org/10.1038/s41598-026-36130-z
Mots-clés: vidéosurveillance, détection d'anomalies, caméras intelligentes, détection de crimes, apprentissage automatique