Clear Sky Science · fr
Un cadre de réseau neuronal pour sélectionner des algorithmes d’amélioration vidéo en temps réel sur appareils mobiles
Des vidéos plus nettes dans votre poche
Des appels vidéo en famille au streaming de films en passant par les applications de réalité augmentée, nous attendons désormais de nos téléphones qu’ils offrent une image nette et claire partout et à tout moment. Pourtant, chaque appareil mobile doit jongler : il faut améliorer la qualité d’image sans vider la batterie ni ralentir l’ensemble. Cet article examine un système de décision intelligent qui aide les téléphones à choisir automatiquement la méthode d’amélioration vidéo « la meilleure » en temps réel, en trouvant un équilibre entre qualité visuelle, rapidité et consommation d’énergie.
Pourquoi améliorer la vidéo est difficile sur mobile
Les techniques modernes d’amélioration vidéo peuvent supprimer le bruit, augmenter la résolution et rendre les scènes sombres ou à faible contraste plus visibles. Mais nombre des méthodes les plus puissantes sont très gourmandes en calcul, ce qui est problématique pour les petits processeurs et les batteries limitées. Les appareils mobiles doivent évaluer plusieurs besoins concurrents à la fois : la rapidité d’exécution, la qualité visuelle, la consommation d’énergie et la complexité d’implémentation sur du matériel modeste. Choisir manuellement parmi plusieurs algorithmes candidats pour chaque situation est complexe et propice aux erreurs, surtout lorsque les conditions varient d’une image à l’autre.
Mêler jugement humain et mathématiques intelligentes
Les auteurs proposent un nouveau cadre décisionnel qui fusionne deux idées : la logique floue et les réseaux neuronaux. La logique floue permet de gérer des jugements imprécis, de type humain, comme « cette méthode est assez rapide mais plutôt gourmande en énergie », plutôt que des évaluations strictes oui/non. Les réseaux neuronaux, inspirés des connexions entre cellules cérébrales, sont de puissants reconnaisseurs de motifs. Dans ce cadre, des experts évaluent d’abord chaque méthode d’amélioration vidéo selon quatre critères simples : vitesse de traitement, amélioration de la qualité visuelle, consommation d’énergie et complexité d’implémentation. Ces évaluations ne sont pas traitées comme des scores fixes mais comme des valeurs « floues » capables d’exprimer des nuances de préférence et d’incertitude.
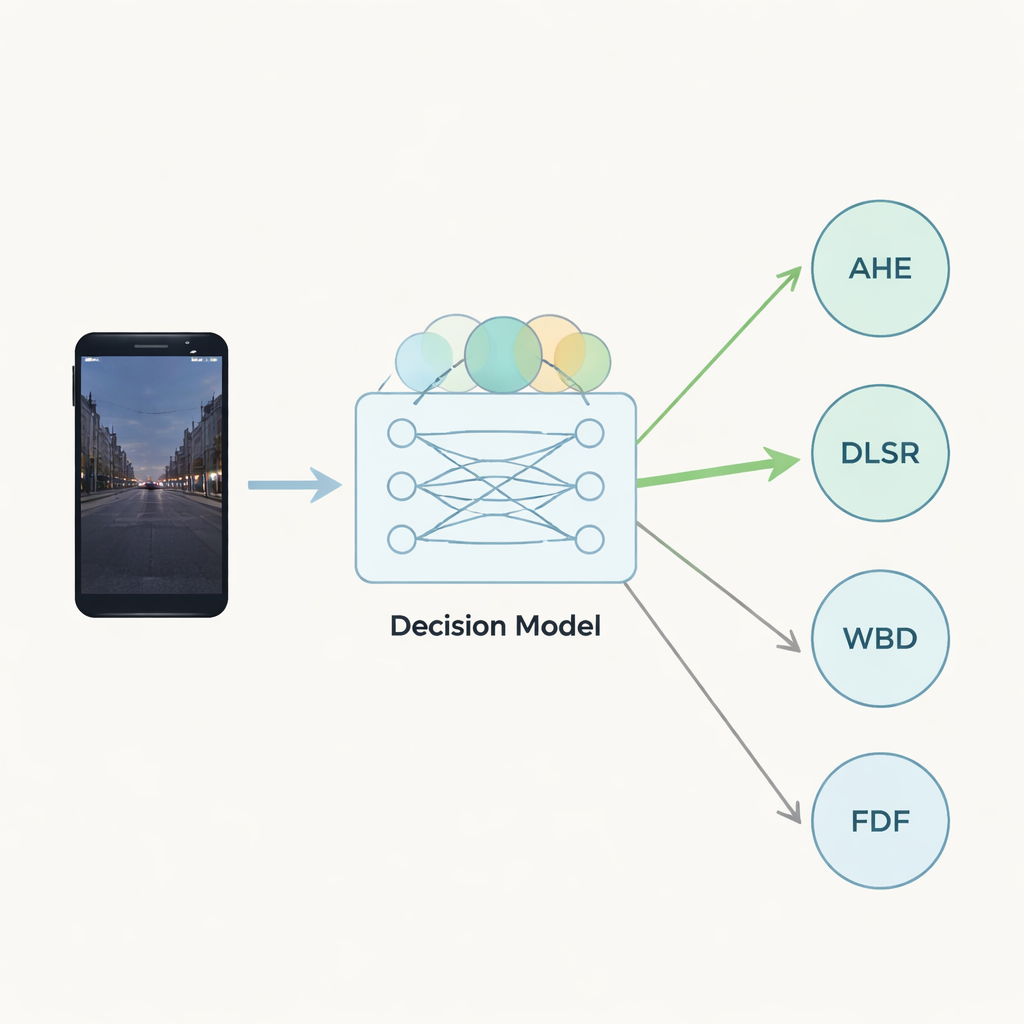
Un moteur de décision léger et en couches
Pour combiner ces évaluations floues, les auteurs utilisent une famille d’outils mathématiques appelés normes de Sugeno–Weber. Ces normes agissent comme des mixeurs ajustables qui agrègent différentes informations tout en capturant leurs interactions. Les entrées floues fournies par plusieurs experts sont d’abord mélangées dans une couche cachée à l’aide d’une étape moyenne spécialisée. Une seconde étape d’agrégation produit un score global pour chaque algorithme candidat. De simples fonctions d’activation — filtres mathématiques souvent utilisés en apprentissage profond — transforment ensuite ces valeurs combinées en sorties finales. Les auteurs comparent deux de ces fonctions (sigmoïde et swish) et montrent qu’elles produisent des classements très similaires, ce qui suggère que le moteur de décision est stable et fiable.
Mettre quatre méthodes vidéo à l’épreuve
Le cadre est appliqué à quatre techniques courantes d’amélioration vidéo sur mobile. L’égalisation d’histogramme adaptative augmente le contraste local, en particulier dans un éclairage inégal ; la suréchantillonnage par apprentissage profond tente de reconstruire des détails fins à partir d’une entrée basse résolution en utilisant des réseaux neuronaux ; le débruitage par ondelettes réduit le bruit en analysant l’image à plusieurs échelles ; et le filtrage dans le domaine fréquentiel manipule les composantes fréquentielles pour mettre en valeur ou atténuer certaines caractéristiques. Chaque méthode est évaluée, combinée entre experts et passée dans le réseau neuronal flou. Le système classe de manière constante la suréchantillonnage par apprentissage profond comme le meilleur choix, trouvant le meilleur compromis global entre vitesse, qualité, consommation et complexité selon les évaluations des experts.
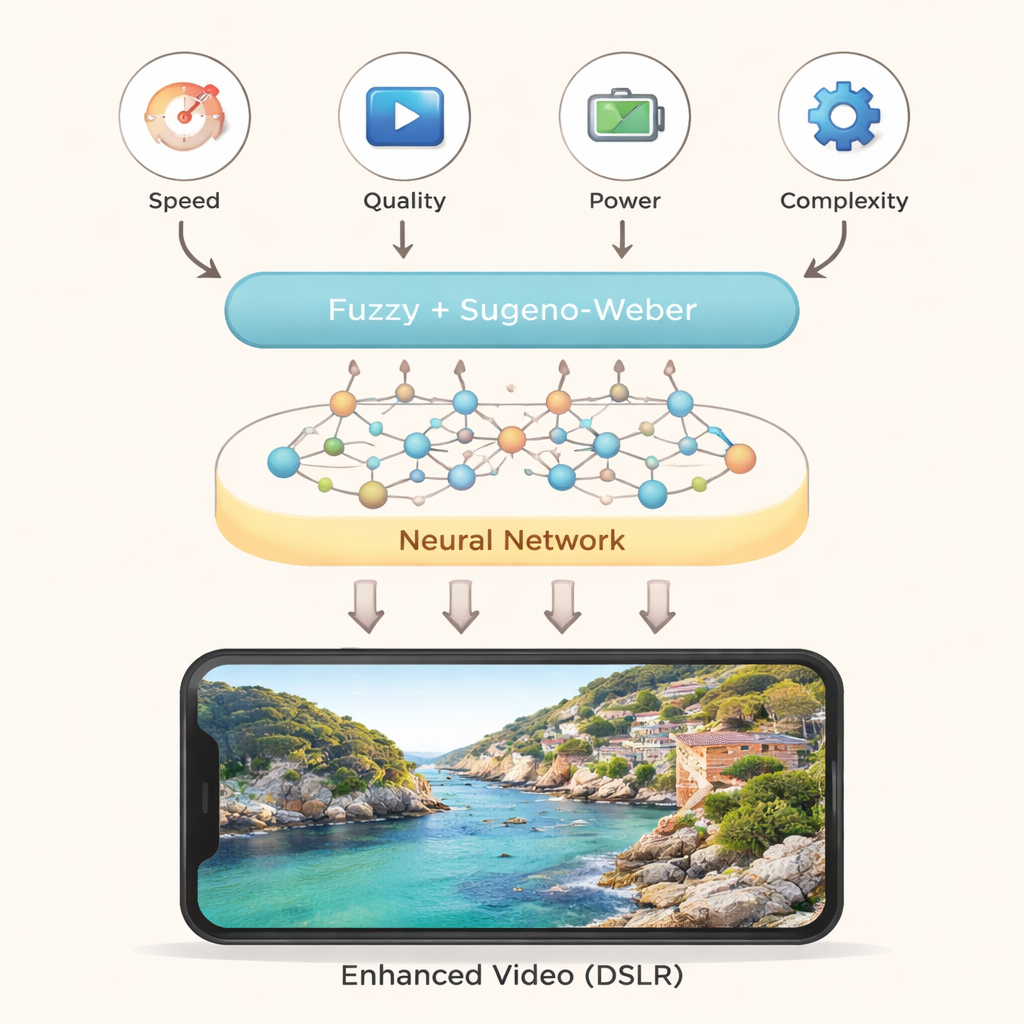
Des choix robustes pour les appareils du monde réel
Les auteurs varient également des paramètres internes clés pour tester la sensibilité des classements à l’ajustement. Si les scores numériques exacts bougent légèrement, l’ordre général des quatre méthodes ne change pas, indiquant que les conclusions du modèle sont robustes. Ils comparent ensuite leur approche de réseau neuronal flou à plusieurs autres techniques décisionnelles établies et constatent que celles-ci convergent aussi vers la suréchantillonnage par apprentissage profond comme meilleure option. Pour le lecteur non spécialiste, la conclusion est simple : en combinant soigneusement l’opinion d’experts avec un réseau neuronal compact et efficace à calculer, ce cadre peut aider les téléphones et autres petits appareils à choisir automatiquement la stratégie d’amélioration vidéo la mieux adaptée en temps réel — offrant une vidéo plus claire et plus nette sans sacrifier la réactivité ni l’autonomie de la batterie.
Citation: Khan, M., Rahman, M.I. & Ziar, R.A. A neural network framework for selecting real-time video enhancement algorithms on mobile devices. Sci Rep 16, 5257 (2026). https://doi.org/10.1038/s41598-026-36099-9
Mots-clés: amélioration vidéo mobile, réseaux neuronaux flous, suramplification par apprentissage profond, traitement d’image en temps réel, modèles de prise de décision