Clear Sky Science · fr
Intégration de la régression-krigeage basée sur la forêt aléatoire pour analyser la variabilité spatiale des précipitations dans les régions arides et semi-arides
Pourquoi cartographier la pluie dans les terres sèches est important
Dans les pays où l'eau est rare, savoir précisément où et quand il pleut peut faire la différence entre sécurité alimentaire et crise. Le Pakistan couvre des montagnes, des déserts et des plaines fertiles, et ses précipitations sont devenues plus erratiques avec le changement climatique. Pourtant, les stations météorologiques au sol sont peu nombreuses et éloignées. Cette étude pose une question pratique : avec des données limitées, les méthodes modernes d'apprentissage automatique combinées aux techniques classiques de cartographie peuvent-elles produire des cartes de précipitations plus nettes et fiables pour guider l'agriculture, la gestion des crues et des eaux ?
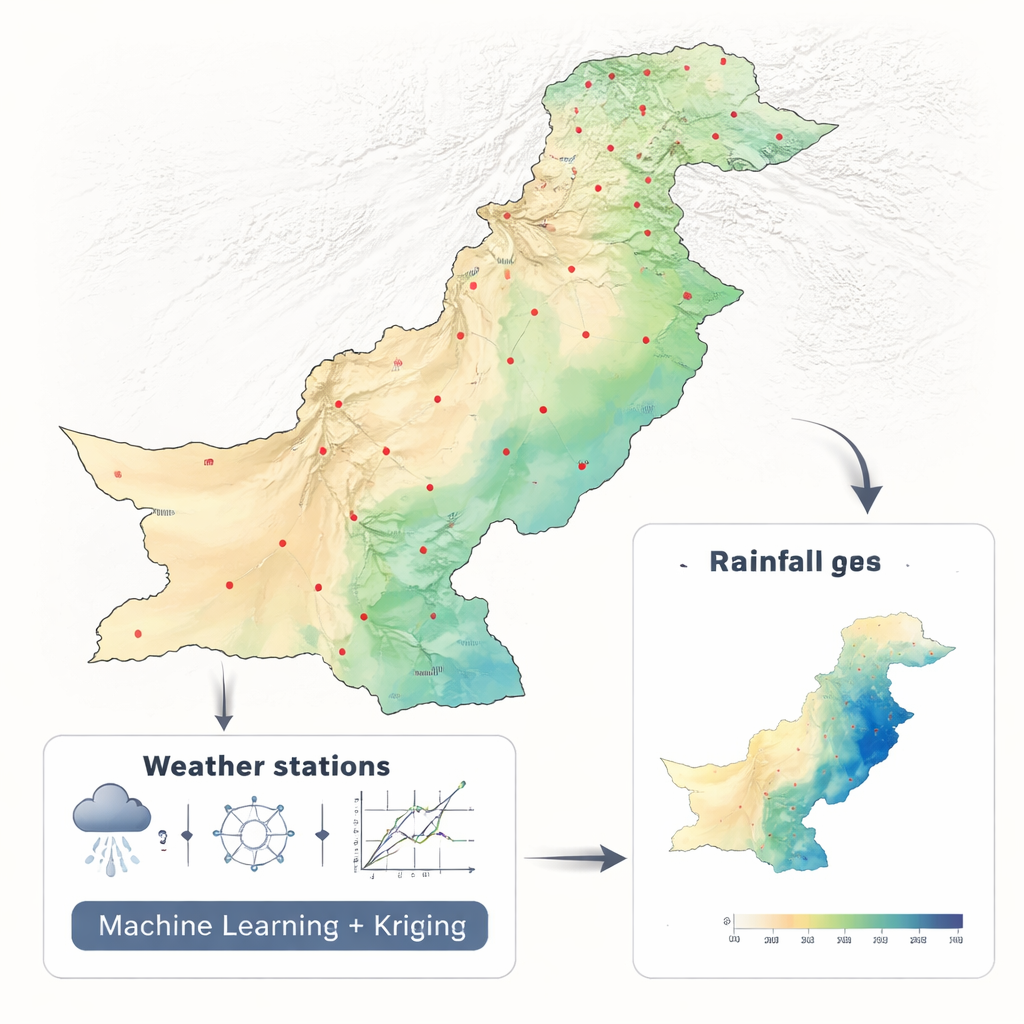
Transformer des pluviomètres dispersés en cartes complètes
Les chercheurs ont travaillé avec deux décennies de données mensuelles de précipitations (2001–2010 et 2011–2021) provenant de 42 stations à travers le Pakistan, en utilisant un jeu de données climatiques cohérent de la NASA. Plutôt que d’alimenter des dizaines de variables environnementales dans un modèle complexe, ils n’ont délibérément utilisé que la latitude et la longitude. Cette conception épurée leur a permis de se concentrer sur une question centrale : quelle approche mathématique transforme le mieux des mesures ponctuelles dispersées en une carte continue. Ils ont comparé six méthodes d’apprentissage automatique — Forêt aléatoire, Machine à vecteurs de support, K-plus proches voisins, Réseau de neurones, Elastic Net et Régression polynomiale — chacune intégrée dans un cadre appelé régression-krigeage, largement employé en géosciences.
Mélanger l’apprentissage de type big data avec l’intuition spatiale
La régression-krigeage fonctionne en deux étapes. D’abord, un modèle de régression prédit la pluie en tout point à partir de ses coordonnées, capturant les grands motifs tels que des montagnes plus humides et des déserts plus secs. Ensuite, une méthode spatiale appelée krigeage comble les différences locales restantes entre observations et prédictions. Pour rendre cette seconde étape fiable, l’équipe a d’abord étudié à quel point les précipitations étaient similaires ou différentes entre paires de stations à diverses distances — un outil appelé variogramme. Ils ont constaté que des formes mathématiques simples, « circulaire » et « linéaire », décrivaient le mieux comment la similarité des précipitations décroît avec la distance selon les saisons et entre les deux décennies, signe de systèmes pluvieux régionaux plutôt lisses plutôt que d’à-coups brusques.
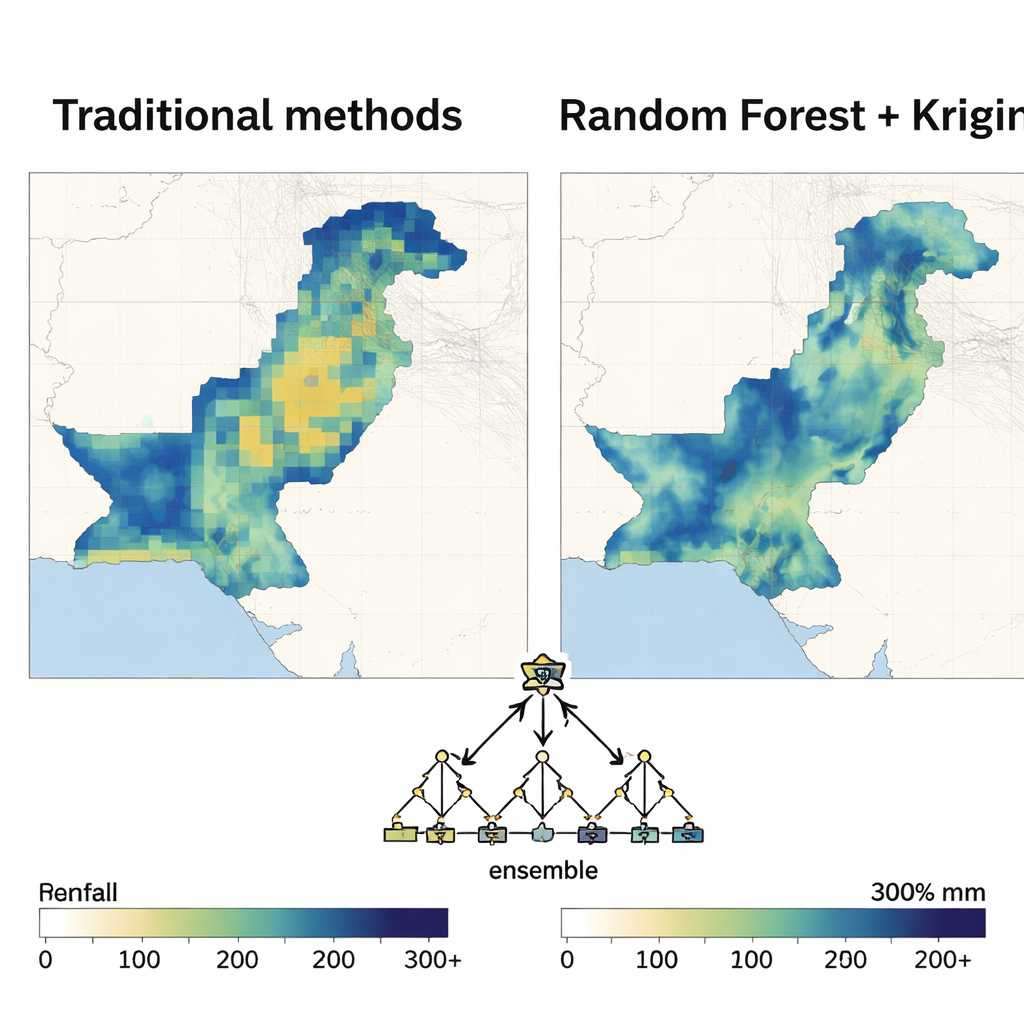
La Forêt aléatoire se révèle en tête
Une fois la structure spatiale déterminée, chaque méthode d’apprentissage automatique a servi tour à tour de moteur de régression à l’intérieur du modèle hybride. Les auteurs ont évalué les performances avec des métriques standards d’erreur et la part de variabilité des précipitations expliquée par le modèle. Sur presque tous les mois et pour les deux décennies, l’approche basée sur la Forêt aléatoire a fourni les cartes les plus précises et les plus stables. Elle a réduit les erreurs de prédiction bien davantage que la régression polynomiale et a constamment surpassé les machines à vecteurs de support, les réseaux de neurones et autres méthodes, en particulier pendant la mousson lorsque les précipitations sont les plus intenses et variables. Les cartes obtenues étaient lisses là où il le fallait, tout en capturant des contrastes marqués entre zones sèches et zones humides, avec une incertitude relativement faible.
Ce que révèlent les changements de schémas de pluie
En comparant les deux décennies, l’étude a également mis en évidence des signes d’évolution du comportement des précipitations. En moyenne, la décennie la plus récente (2011–2021) était plus humide, avec une variabilité plus forte d’un mois à l’autre et d’un lieu à l’autre, notamment au printemps et pendant la mousson. La structure spatiale des précipitations est devenue plus dispersée, suggérant des fluctuations plus larges dans la distribution de l’eau. Fait important, la combinaison Forêt aléatoire–krigeage a géré à la fois le climat antérieur, relativement plus doux, et la période récente plus variable sans perte de précision, laissant entendre que de tels outils flexibles conviennent bien à un monde qui se réchauffe et devient moins prévisible.
Des cartes aux décisions sur le terrain
En termes concrets, l’article montre que des algorithmes intelligents peuvent extraire plus de valeur de séries limitées de précipitations, produisant des cartes haute résolution utiles même dans des régions pauvres en données. Pour le Pakistan, ces cartes peuvent améliorer la planification de l’irrigation, la gestion des réservoirs et des défenses contre les crues, et aider à identifier les communautés les plus exposées à la sécheresse ou aux pluies intenses. Les auteurs insistent sur le fait que leur travail est une preuve de concept centrée sur les techniques de cartographie elles-mêmes, et non encore un système complet d’alerte aux inondations ou aux sécheresses. Leur conclusion reste cependant claire : combiner l’apprentissage ensembliste, mené par la Forêt aléatoire, avec la cartographie géostatistique offre une voie puissante et pratico-pratique pour suivre l’évolution des précipitations dans les terres arides et semi-arides du monde.
Citation: Manaf, M., Ali, Z. & Scholz, M. Integrating random forest-based regression kriging for analyzing spatial variability of rainfall in arid and semi-arid regions. Sci Rep 16, 5298 (2026). https://doi.org/10.1038/s41598-026-36074-4
Mots-clés: cartographie des précipitations, forêt aléatoire, régression-krigeage, climat du Pakistan, ressources en eau