Clear Sky Science · fr
Prédiction inter-puits par apprentissage automatique des diagraphies soniques à Terre-Neuve-et-Labrador
Écouter les roches sans microphone
Les compagnies pétrolières et gazières s'appuient sur des outils acoustiques « soniques » pour écouter la manière dont les ondes sonores se propagent dans les roches souterraines. Ces mesures détaillées aident les ingénieurs à apprécier la résistance des roches, à planifier des puits en toute sécurité et à corréler les données de forage avec les relevés sismiques. Mais les outils soniques sont coûteux, peuvent ralentir les opérations et parfois sont impossibles à utiliser. Cette étude montre comment l'apprentissage automatique peut reconstruire l'information sonique à partir de mesures moins chères et collectées de manière routinière, offrant un moyen « d'entendre » le sous-sol même quand le microphone manque.
Pourquoi prédire les données soniques est important
Dans le forage offshore, les opérateurs enregistrent de nombreux types de diagraphies : radioactivité naturelle, vitesse de forage, débit de pompe, charge sur la mèche, et plus encore. Les diagraphies soniques sont particulières car elles révèlent la vitesse de propagation du son dans la roche, un paramètre clé pour estimer la rigidité des roches, la pression et les contraintes. Lorsque les outils soniques ne sont pas disponibles, les ingénieurs doivent soit composer avec des lacunes, soit se rabattre sur des règles empiriques approximatives. En utilisant l'apprentissage automatique pour transformer des diagraphies non-soniques courantes en courbes « pseudo-soniques » précises, les entreprises peuvent réduire les coûts d'acquisition, combler les sections manquantes et continuer à prendre des décisions éclairées sur la stabilité du puits et le comportement du réservoir.
Une recette rigoureuse pour éviter la triche
Les auteurs ont travaillé avec des données de deux puits offshore à Terre-Neuve-et-Labrador. Pour chaque profondeur, ils ont tenté de prédire la lenteur en compression (une façon d'exprimer le temps de trajet d'une onde sonore dans la roche) en n'utilisant que des mesures non-soniques. Crucialement, ils ont interdit toute entrée qui utiliserait directement ou indirectement des données soniques, comme des propriétés élastiques dérivées. Ils ont aussi construit des caractéristiques en n'employant que des informations de la même profondeur ou de profondeurs plus faibles, reproduisant le cas du forage en temps réel où l'avenir est inconnu. Les valeurs aberrantes des capteurs ont été identifiées à l'aide de statistiques provenant d'un seul puits « d'entraînement » puis traitées de la même façon dans les deux puits, garantissant que les modèles ne puissent pas apprendre discrètement à partir des données de test. Toutes les normalisations et choix de caractéristiques ont également été fixés sur le puits d'entraînement avant d'être appliqués, sans modification, à l'autre puits.
Transformer les diagraphies brutes en signaux exploitables
Simplement fournir les diagraphies brutes à un algorithme ne suffit généralement pas. L'équipe a conçu un ensemble riche de caractéristiques dépendantes de la profondeur : ils ont suivi la variation de chaque diagraphie avec la profondeur, lissé les signaux bruités à plusieurs échelles, et calculé des pentes et des courbures qui mettent en évidence les tendances locales. Ils ont aussi exprimé la profondeur par rapport à des segments du trou, capturant des motifs qui se répètent lors des changements de diamètre de mèche. Pour éviter que les modèles soient submergés, ils ont classé les caractéristiques à l'aide de trois méthodes différentes et combiné ces classements en une liste ordonnée unique. Un groupe compact des caractéristiques les plus informatives a ensuite été sélectionné en utilisant une séparation temporelle au sein du puits d'entraînement, de sorte que le processus respecte lui-même l'ordre naturel avec la profondeur.
Les modèles à base d'arbres battent le deep learning
L'étude a comparé trois types de modèles : Random Forests, XGBoost (une méthode de gradient boosting populaire) et des réseaux LSTM bidirectionnels, souvent utilisés pour les données séquentielles. Chaque modèle a été entraîné sur un puits et testé à l'aveugle sur l'autre, une configuration exigeante qui révèle les différences entre puits en termes d'étendue de profondeur, de conditions d'exploitation et de types de roche. Dans ce test, XGBoost a donné les meilleurs résultats, obtenant une forte concordance entre les diagraphies soniques prédites et mesurées lorsque le modèle était entraîné sur le premier puits puis appliqué au second. Les Random Forests suivaient de près et étaient parfois plus stables dans les zones bruitées. Les réseaux LSTM, malgré leur complexité, ont été moins performants tant en précision qu'en robustesse, probablement parce qu'il n'y avait que deux puits et que les données variaient fortement avec la profondeur, des conditions peu favorables aux grands réseaux neuronaux.
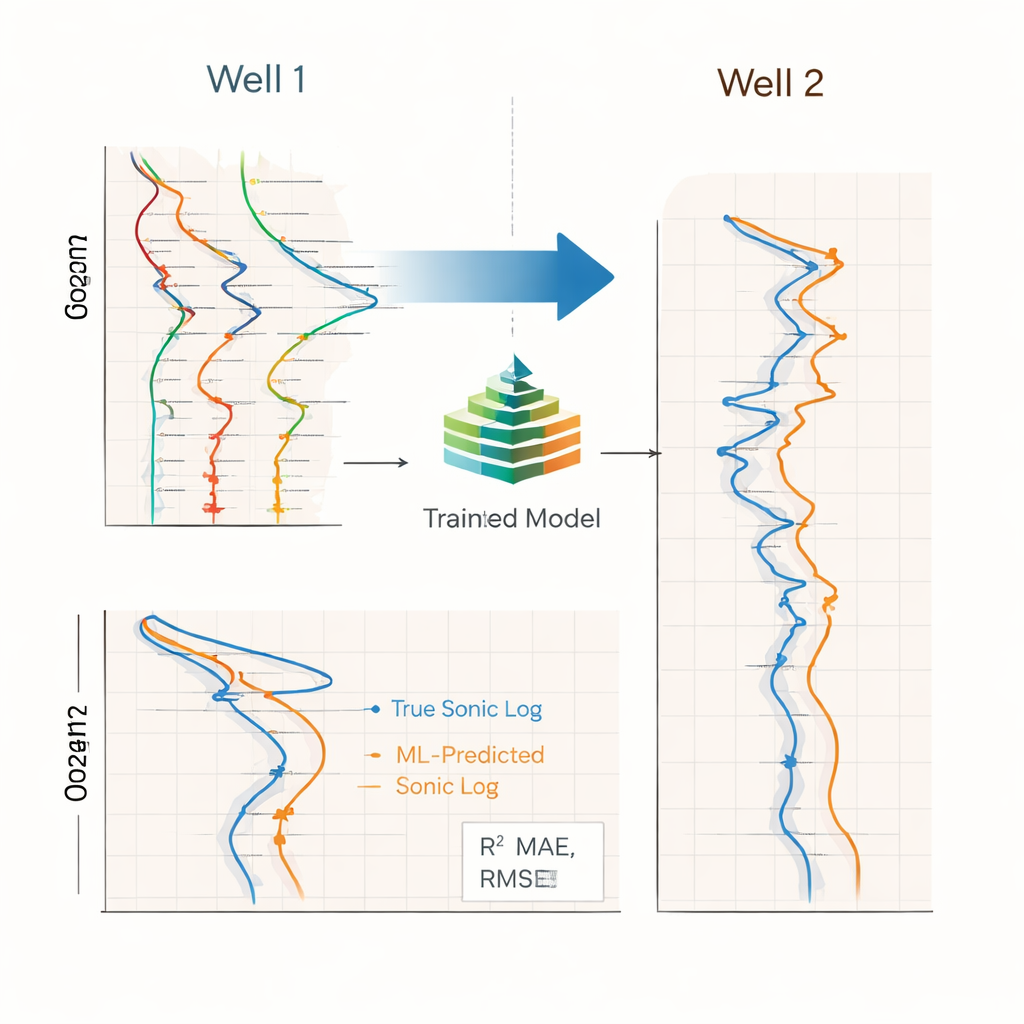
Ce qui détermine la précision et où cela aide
En activant ou désactivant différentes parties de leur prétraitement, les auteurs ont montré que la génération et la sélection astucieuses de caractéristiques faisaient la plus grande différence en performance, davantage que l'ajout de fenêtres d'historique plus longues ou qu'un simple filtrage des valeurs aberrantes. Lorsque ces étapes étaient incluses, les modèles basés sur les arbres généralisaient beaucoup mieux d'un puits à l'autre. Les diagraphies pseudo-soniques résultantes étaient suffisamment précises pour soutenir des tâches en aval telles que l'estimation de la rigidité des roches, la modélisation de la pression interstitielle et des contraintes, l'étalonnage des données sismiques, et la planification de puits dans des zones où les mesures soniques directes sont manquantes, retardées ou peu fiables. Parce que toutes les transformations sont fixées sur un puits de référence puis réutilisées, le flux de travail pourrait fonctionner presque en temps réel pendant le forage.
Conclusion pour les non-spécialistes
Ce travail montre qu'avec une gestion rigoureuse des données et des modèles d'apprentissage automatique bien choisis, il est possible de reconstituer une information sonique de grande valeur à partir de canaux de forage et d'enregistrement moins coûteux dans un nouveau puits que le modèle n'a jamais vu. Cette approche ne remplace pas les outils soniques dédiés, en particulier lorsque les marges de sécurité sont réduites, mais elle offre une solution de secours pratique et rentable, ainsi qu'un contrôle qualité lorsque les données mesurées semblent suspectes. À mesure que davantage de puits et de régions seront ajoutés et que de nouveaux modèles seront testés sous les mêmes règles strictes, ce type de prédiction inter-puits pourrait devenir un élément standard de la boîte à outils numérique pour un forage offshore plus sûr et plus efficace.
Citation: Zare, B., Huque, M.M., James, L.A. et al. Cross-well machine learning prediction of sonic logs in Newfoundland and Labrador. Sci Rep 16, 5292 (2026). https://doi.org/10.1038/s41598-026-36053-9
Mots-clés: apprentissage automatique, diagraphies soniques, enregistrement de puits, forage offshore, caractérisation du réservoir