Clear Sky Science · fr
L’apprentissage auto-supervisé sur graphes prédit les associations entre ARN non codants et maladies
Pourquoi les ARN cachés comptent pour notre santé
La plupart d’entre nous avons appris que la fonction principale de l’ARN est d’aider à construire des protéines. Mais au cours de la dernière décennie, les scientifiques ont découvert un grand nombre d’ARN « non codants » qui ne deviennent jamais des protéines et contribuent néanmoins à réguler le fonctionnement des cellules. Beaucoup de ces molécules sont désormais reconnues pour favoriser ou inhiber des cancers et d’autres maladies complexes. Identifier quels ARN non codants sont liés à quelles maladies pourrait révéler de nouvelles façons de diagnostiquer précocement ou de concevoir des traitements plus précis — mais tester chaque possibilité en laboratoire serait terriblement lent. Cette étude présente une méthode informatique puissante capable de trier d’immenses réseaux biologiques et de proposer de manière fiable les connexions ARN–maladie les plus prometteuses à vérifier expérimentalement.
Du « déchet » aux acteurs cellulaires clés
Pendant des années, les ARN non codants ont été rejetés comme de simples résidus de l’activité génétique. Nous savons maintenant que des familles telles que les microARN, les longs ARN non codants et les ARN circulaires participent à l’orchestration de processus essentiels, depuis le conditionnement de l’ADN jusqu’à l’activation ou la répression de gènes et la transmission de signaux intracellulaires. Parce qu’ils interviennent à de nombreux points de contrôle, de petites altérations de ces ARN peuvent faire basculer l’équilibre vers le cancer ou d’autres maladies. Les cliniciens commencent déjà à les envisager comme biomarqueurs et cibles médicamenteuses potentielles. Le défi est celui de l’échelle : il existe des milliers d’ARN différents et des centaines de maladies, et les expérimentations traditionnelles pour tester chaque lien possible sont coûteuses et longues. C’est là qu’interviennent les prédictions informatiques, qui permettent de réduire l’espace de recherche.
Comment lire un réseau biologique
Les méthodes informatiques antérieures tentaient de prédire les liens ARN–maladie en décomposant de grandes tables de données en éléments plus simples ou en entraînant des modèles d’apprentissage automatique sur des exemples connus. Ces approches ont aidé, mais elles ignoraient souvent la manière dont les ARN et les maladies sont tissés en réseaux. Les « réseaux de neurones sur graphes » modernes traitent ARN et maladies comme des nœuds reliés par des arêtes, à la manière d’un réseau social. Ils peuvent apprendre des motifs dans les connexions. Cependant, la plupart de ces méthodes graphiques nécessitent de nombreux exemples d’entraînement fiables et de nombreuses caractéristiques d’entrée soigneusement conçues. Elles deviennent ainsi sensibles aux données manquantes, aux mesures bruitées et au surapprentissage — bien performantes sur des données connues mais défaillantes lorsqu’il s’agit de prévoir de nouvelles associations.
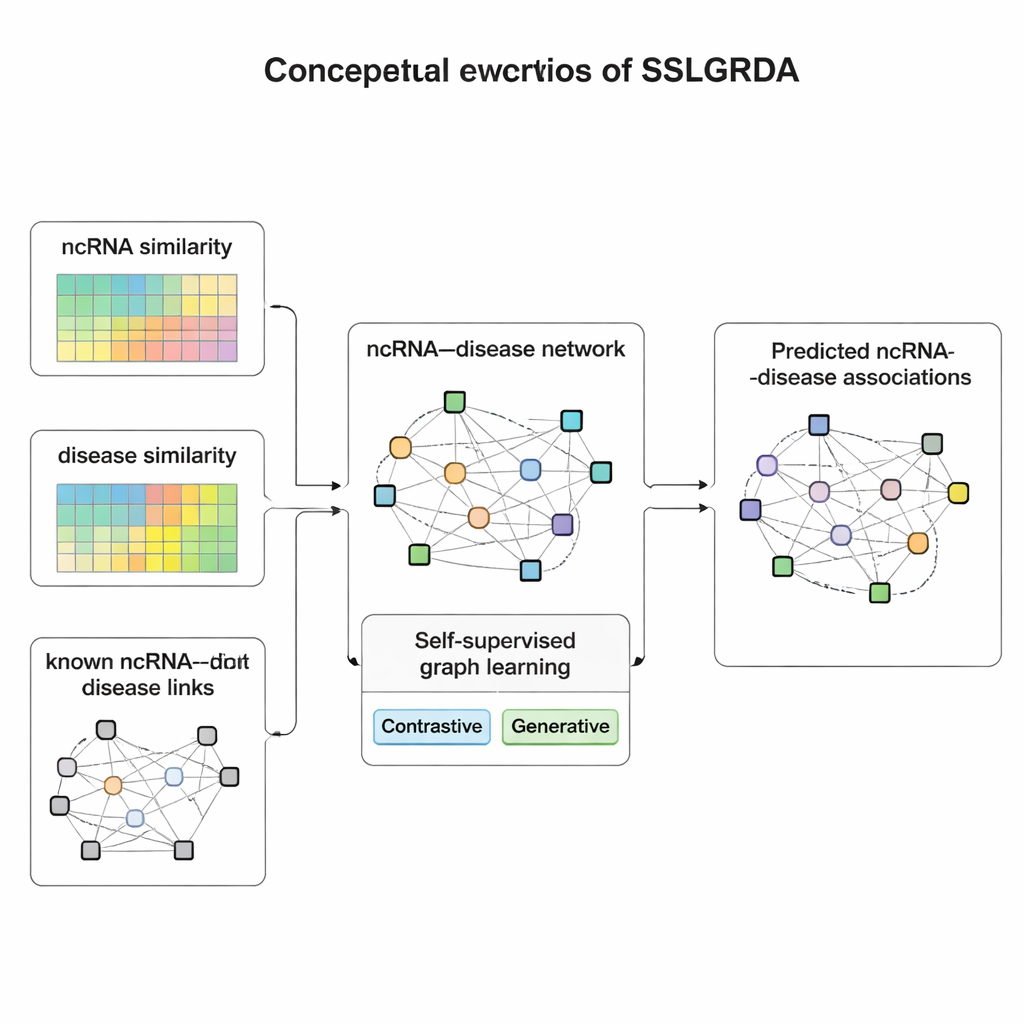
Apprendre à partir des données elles-mêmes
Les auteurs présentent SSLGRDA, un nouveau cadre qui enseigne à un modèle de graphe à apprendre des motifs utiles sans dépendre fortement de données annotées. L’idée clé est « l’apprentissage auto-supervisé » : au lieu d’indiquer quels ARN s’associent à quelles maladies, le modèle invente ses propres tâches d’entraînement à partir de la seule structure et des attributs du réseau. Les chercheurs construisent deux types de graphes. Le premier maintient ARN et maladies comme des types de nœuds distincts reliés par des liens connus. L’autre fusionne ces nœuds en un grand réseau homogène qui inclut aussi des informations de similarité — à quel point deux ARN ou deux maladies se ressemblent — de sorte que même des éléments faiblement connectés gagnent des voisins informatifs. Au-dessus de ces graphes, SSLGRDA utilise deux styles d’auto-entraînement. Les stratégies contrastives demandent au modèle de reconnaître que différentes « vues » d’un même nœud (par exemple, ses connexions versus ses attributs) doivent mener à des représentations internes similaires, tout en séparant clairement les nœuds non liés. Les stratégies génératives masquent volontairement des parties des caractéristiques d’entrée et mettent le modèle au défi de les reconstruire, l’encourageant à capturer une structure profonde plutôt qu’à mémoriser le bruit.
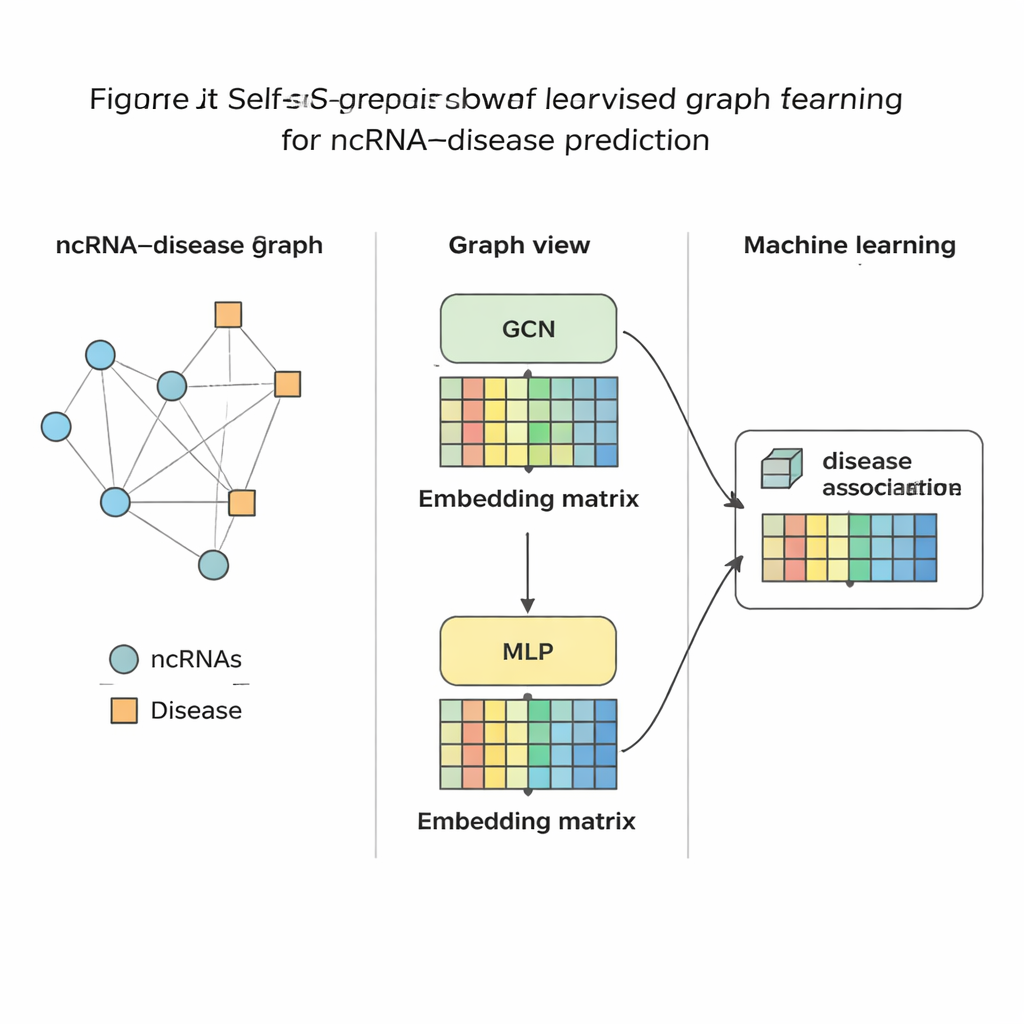
Mettre la méthode à l’épreuve
Une fois que SSLGRDA a distillé chaque ARN et chaque maladie en une empreinte numérique compacte, un classifieur standard d’apprentissage automatique est entraîné pour juger si un lien entre eux est probable ou non. Les auteurs ont évalué cette approche sur neuf jeux de données différents couvrant trois grands types d’ARN et des centaines de maladies. Globalement, leurs variantes auto-supervisées contrastives sur le graphe homogène mixte ont obtenu les meilleures performances, surpassant une série d’outils existants, y compris de solides méthodes basées sur les graphes. La méthode a non seulement atteint une plus grande précision dans les tests globaux, mais a aussi classé les partenaires corrects en haut de la liste lorsqu’on se concentre sur un ARN ou une maladie à la fois — crucial pour une utilisation réelle où un biologiste peut partir d’un seul cancer et demander quels ARN étudier. Ils ont en outre montré que les mêmes idées se transfèrent bien à d’autres réseaux biomédicaux, comme ceux reliant microbes et maladies ou médicaments.
Des prédictions aux thérapies potentielles
Pour démontrer la valeur pratique, l’équipe a appliqué SSLGRDA pour rechercher de nouveaux ARN non codants impliqués dans le cancer du sein, le cancer du côlon et plusieurs autres affections. Beaucoup des suggestions les mieux classées ont ensuite été confirmées dans des bases de données indépendantes ou des rapports scientifiques, soutenant la capacité du modèle à repérer des motifs biologiquement significatifs. Pour les non-spécialistes, la conclusion est que ce travail fournit un moyen plus intelligent d’explorer l’enchevêtrement sans cesse croissant des données biologiques à la recherche d’indices cachés sur les maladies. En apprenant automatiquement comment ARN et maladies se regroupent et interagissent, des méthodes de graphes auto-supervisées comme SSLGRDA peuvent orienter les chercheurs de laboratoire vers les cibles les plus prometteuses, accélérant potentiellement le passage des données brutes à de meilleurs diagnostics et traitements.
Citation: Wu, Q., Tang, S. Self-supervised learning on graphs predicts non-coding RNA and disease associations. Sci Rep 16, 5231 (2026). https://doi.org/10.1038/s41598-026-36030-2
Mots-clés: ARN non codant, association maladie, réseaux de neurones sur graphes, apprentissage auto-supervisé, biologie computationnelle