Clear Sky Science · fr
La base de règles de croyance optimisée multi-paramètres pour prédire la performance des élèves avec interprétabilité
Pourquoi prédire les notes concerne tout le monde
Les bulletins peuvent sembler simples, mais les forces qui façonnent les notes d’un élève sont loin de l’être. Les établissements font de plus en plus appel à des modèles informatiques pour repérer tôt les élèves en difficulté et orienter les aides. Cependant, beaucoup de ces modèles sont des « boîtes noires » : ils peuvent être précis, mais même les enseignants et les parents ne savent pas pourquoi une prédiction a été formulée. Cet article présente une approche nouvelle qui vise à la fois une grande précision et une compréhension aisée, afin que les professionnels de l’éducation puissent faire confiance aux résultats et agir en conséquence.
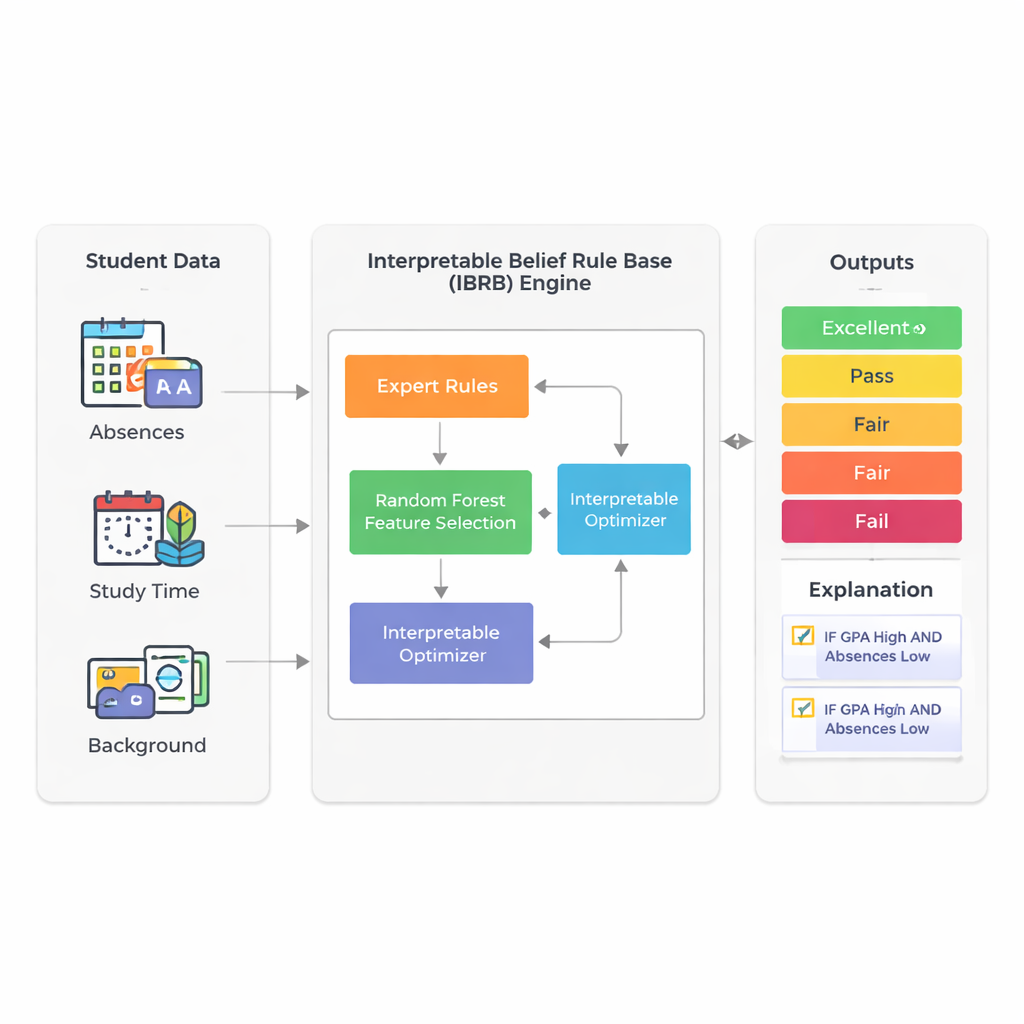
Une façon plus intelligente d’interpréter les signaux
L’étude se concentre sur la prédiction des performances finales des élèves en s’appuyant sur les informations déjà collectées par les établissements : moyenne générale (GPA), absences, temps d’étude, origine sociale, ainsi que facteurs familiaux et d’activités. Plutôt que de recourir à des systèmes profonds opaques, les auteurs s’appuient sur une technique appelée base de règles de croyance. Dans ce cadre, des experts rédigent des règles qui ressemblent à ce qu’un enseignant pourrait dire : « Si la GPA est élevée et les absences faibles, alors l’élève a probablement de bonnes chances de réussir. » Chaque règle porte un degré de croyance sur des issues possibles comme Excellent, Bon, Passable, Moyen ou Échec. Cela rend le processus de raisonnement visible et, en principe, explicable aux non-spécialistes.
Maîtriser la complexité sans perdre le sens
Un défi majeur des systèmes basés sur des règles est qu’ils peuvent devenir ingérables lorsque de nombreux attributs d’élèves sont inclus : chaque facteur supplémentaire multiplie le nombre de règles possibles. Pour éviter cette « explosion de règles », les chercheurs utilisent d’abord une forêt aléatoire — un ensemble d’arbres de décision largement employé — pour mesurer quelles caractéristiques importent le plus pour la prédiction. Dans leur jeu de données réel de 2 392 élèves provenant d’une source publique, la GPA et le nombre d’absences représentent environ 73 % du pouvoir prédictif du modèle. En conservant délibérément seulement ces deux entrées, le modèle final reste compact et plus facile à interpréter, tout en reflétant la majeure partie de la variation des résultats scolaires.
Construire des règles que l’on peut suivre
Le cœur du nouveau modèle, appelé IBRB-m, est un ensemble structuré de 25 règles combinant niveaux de GPA et d’absences avec des degrés de croyance pour les cinq catégories de performance. Les auteurs formalisent ce que signifie qu’un tel modèle soit « interprétable ». Parmi leurs exigences : chaque niveau de référence (tel que « GPA faible ») doit couvrir un intervalle clair et distinct ; la base de règles doit couvrir toutes les combinaisons réalistes d’entrées ; des paramètres comme les poids de règles et les poids d’attributs doivent avoir des significations compréhensibles ; et les calculs internes du système doivent transformer l’information de façon transparente et mathématiquement cohérente. En plus de ces conditions classiques, ils ajoutent des directives spécifiques à l’éducation qui obligent les prédictions du modèle à suivre des formes de bon sens — par exemple, éviter des cas aberrants où un élève serait jugé à la fois très susceptible d’exceller et d’échouer.
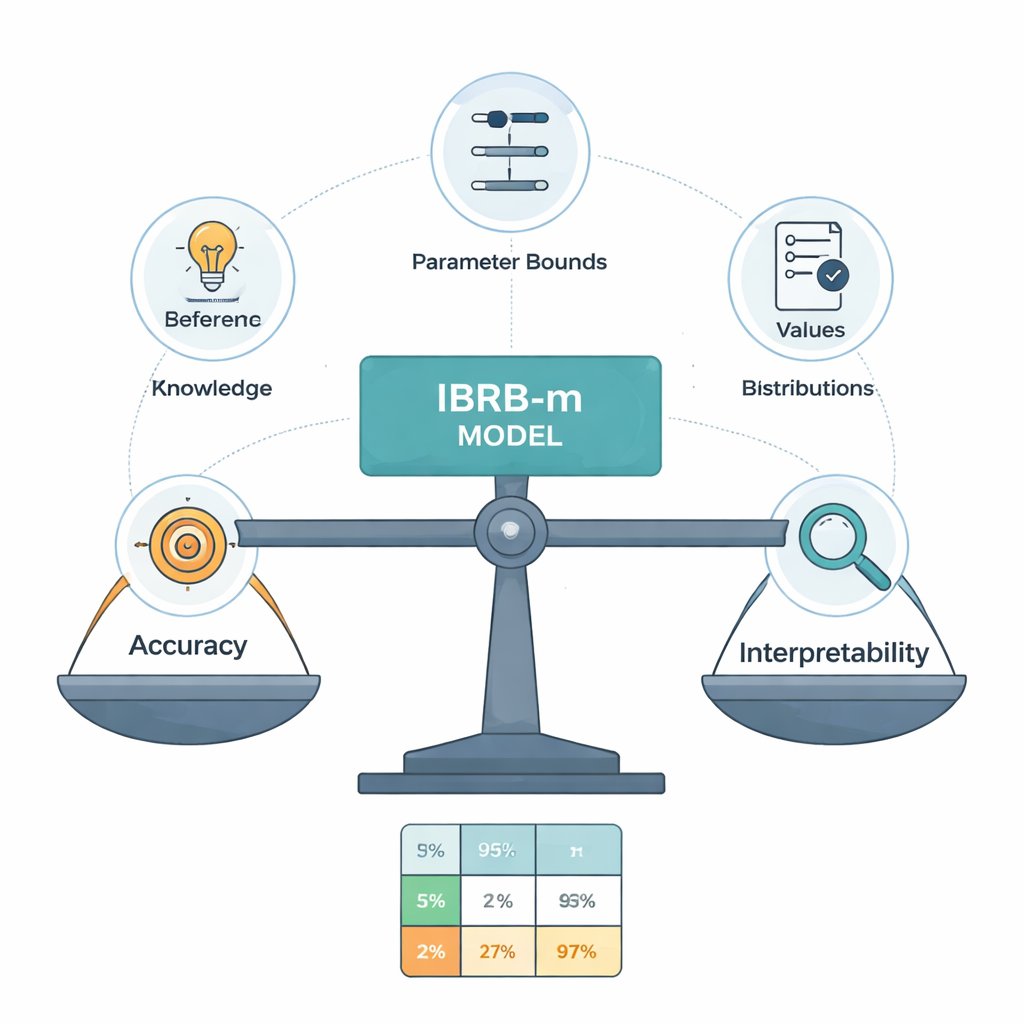
Laisser les données affiner ce que disent les experts
Les experts humains ne sont pas toujours d’accord, et leurs règles initiales peuvent être imprécises. Pour affiner ces règles sans transformer le modèle en boîte noire, les auteurs conçoivent un algorithme d’optimisation amélioré qui recherche de meilleures valeurs de paramètres tout en respectant des contraintes strictes d’interprétabilité. Cet algorithme ajuste non seulement les poids de règles et les degrés de croyance, mais aussi les points de coupure qui définissent des catégories comme Excellent ou Passable. Il limite toutes les modifications aux bornes approuvées par les experts et impose des motifs de croyance raisonnables et lisses à travers les notes. En pratique, l’ordinateur « incite » le système d’experts vers une meilleure précision, sans être autorisé à inventer des règles qui dérouteraient un enseignant averti.
Quelle efficacité en pratique ?
Testé sur l’ensemble de données de performance des élèves de Kaggle, le modèle IBRB-m prédit correctement les niveaux de performance finale dans plus de 99 % des cas, surpassant à la fois les systèmes à base de règles de croyance antérieurs et des outils d’apprentissage automatique courants tels que les réseaux neuronaux, les forêts aléatoires et les k-plus proches voisins. Tout aussi important, les règles optimisées restent proches des évaluations initiales des experts lorsqu’on les mesure par une métrique de distance simple, ce qui signifie que le raisonnement derrière chaque prédiction peut encore être retracé et justifié. La validation croisée sur plusieurs découpages des données montre que les performances du modèle sont stables, et non le fruit d’une partition chanceuse.
Ce que cela signifie pour les classes
Pour le grand public, l’essentiel est qu’il est possible d’avoir des outils de prédiction des élèves à la fois puissants et compréhensibles. Plutôt que d’émettre des scores de risque mystérieux, le modèle peut mettre en évidence des schémas concrets comme « GPA modérée mais absences fréquentes » et montrer comment ceux-ci conduisent à une prédiction de Moyen ou d’Échec. Les enseignants et les conseillers peuvent alors répondre par des actions ciblées — telles que le soutien à l’assiduité ou le coaching des méthodes de travail — tout en expliquant de manière fiable aux élèves et aux parents pourquoi le modèle a abouti à cette conclusion. Les auteurs soutiennent que ce mélange de précision et de transparence est essentiel si les systèmes fondés sur les données doivent jouer un rôle de confiance dans la promotion d’une éducation juste et efficace.
Citation: Li, J., Zhou, W., Jiang, S. et al. The multi-parameter optimized belief rule base for predicting student performance with interpretability. Sci Rep 16, 5772 (2026). https://doi.org/10.1038/s41598-026-35950-3
Mots-clés: prédiction des performances des élèves, IA interprétable, base de règles de croyance, extraction de connaissances éducatives, apprentissage automatique explicable