Clear Sky Science · fr
Comprendre le discours sur la santé mentale sur Reddit avec des transformers et l’explainabilité
Pourquoi les échanges en ligne sur les sentiments comptent
De nombreuses personnes qui souffrent d’anxiété, de dépression, de trouble bipolaire ou de trouble de la personnalité borderline se tournent vers Internet avant même de consulter un professionnel. Reddit, avec ses communautés anonymes, est devenu un vaste lieu de rencontre pour partager ses peurs, demander de l’aide et soutenir les autres. Cette étude explore à quoi ressemblent des milliers de ces conversations et comment l’intelligence artificielle peut les trier et mettre en évidence les mots que les gens utilisent le plus souvent lorsqu’ils parlent de différentes difficultés de santé mentale.
Un regard sur les communautés de soutien
Les chercheurs se sont concentrés sur quatre grandes communautés Reddit dédiées à l’anxiété, à la dépression, au trouble bipolaire et au trouble de la personnalité borderline (souvent abrégé BPD). Chaque message de leur jeu de données était simplement étiqueté selon la communauté d’origine, et non selon un diagnostic médical. L’équipe a traité ces communautés comme des « espaces de préoccupation », où des personnes aux difficultés similaires se rassemblent pour se défouler, demander conseil et offrir du réconfort. En étudiant comment le langage diffère entre ces espaces, ils ont cherché à comprendre comment les gens décrivent leurs expériences avec leurs propres mots, en dehors du cadre clinique.
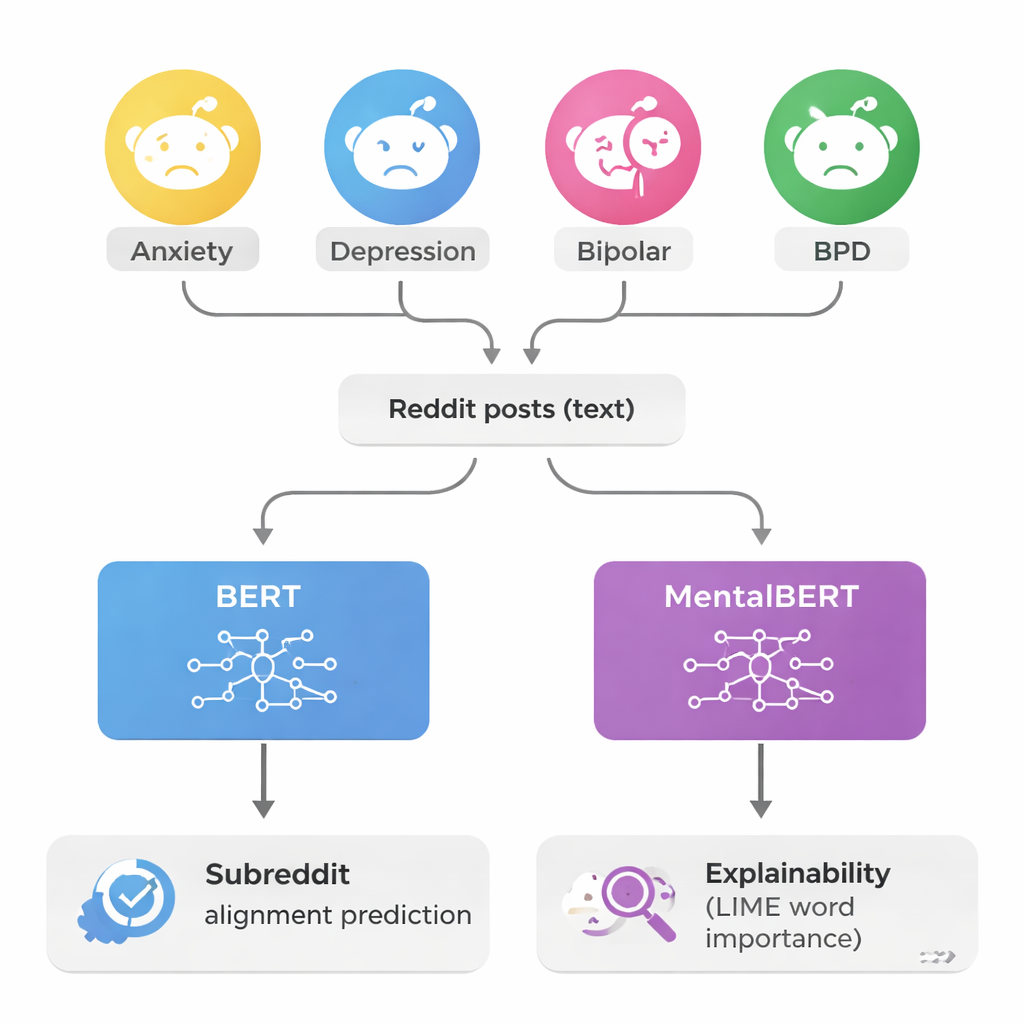
Apprendre aux ordinateurs à trier les conversations
Pour analyser plus de 150 000 messages, les auteurs ont utilisé de puissants modèles de langage appelés transformers, spécifiquement BERT et une version axée santé mentale appelée MentalBERT. Ces modèles lisent chaque message et tentent de deviner à laquelle des quatre communautés il appartient. Comme certaines communautés comptaient beaucoup plus de messages que d’autres, l’équipe a soigneusement équilibré le jeu de données pour que chaque groupe soit également représenté. Cela a rendu la tâche plus difficile mais plus équitable, obligeant les modèles à apprendre réellement les différences de formulation plutôt que de favoriser les communautés les plus fréquentes. Testés ainsi, les modèles ont correctement étiqueté les messages environ 82 % du temps — une nette amélioration par rapport au hasard, qui ne réussirait qu’une fois sur quatre.
Ouvrir la boîte noire de l’IA
Une préoccupation majeure dans les technologies liées à la santé mentale est que les systèmes informatiques peuvent sembler être de mystérieuses « boîtes noires », fournissant des prédictions sans raisons claires. Pour y remédier, les chercheurs ont utilisé une approche appelée LIME qui révèle quels mots ont poussé le modèle vers une décision particulière. Concrètement, LIME masque ou modifie des parties d’un message et observe comment la réponse du modèle change. Si la suppression d’un mot comme « panique » modifie soudainement la communauté prédite, ce mot est considéré comme important. En répétant ce procédé des milliers de fois sur de nombreux messages, l’équipe a constitué des listes des mots les plus influents pour chaque communauté et a vérifié que ces mots correspondaient à ce que les cliniciens savent de chaque condition.
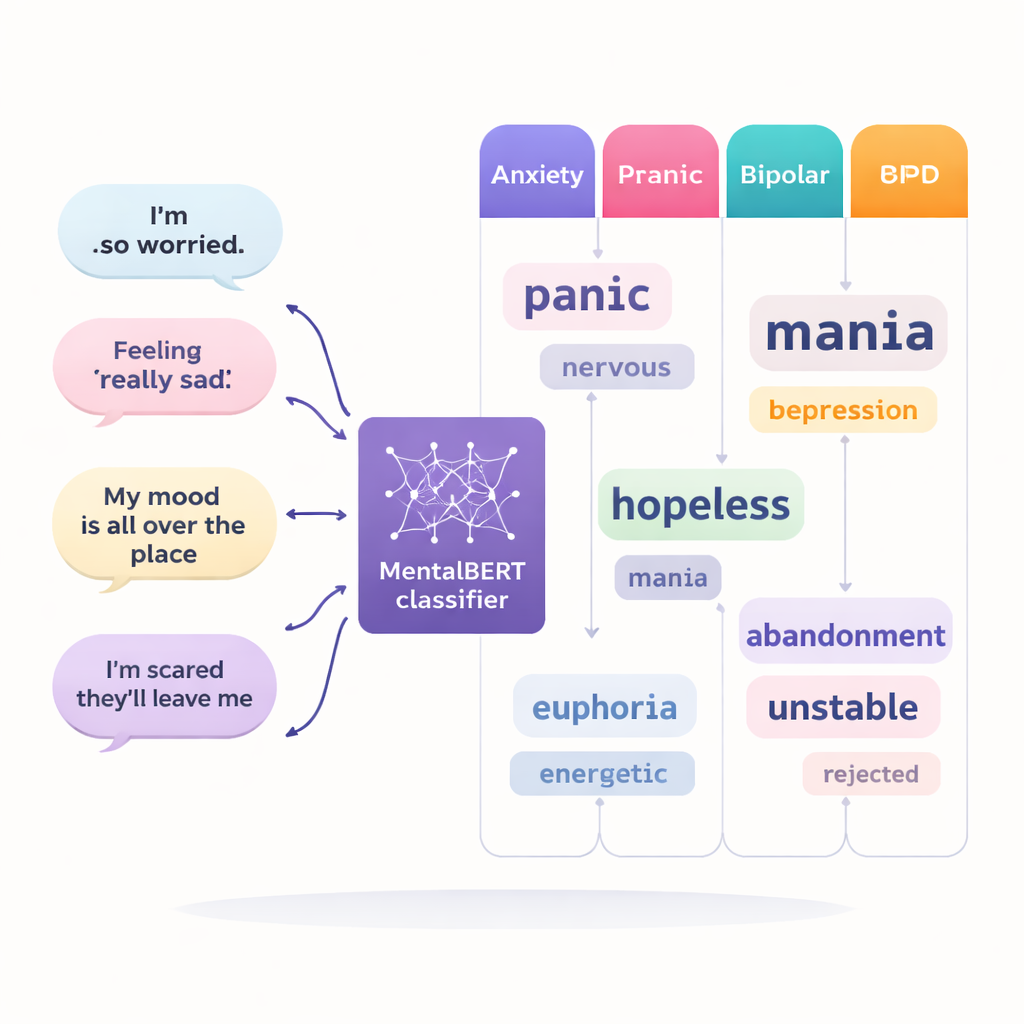
Des voix distinctes pour des difficultés différentes
Les explications ont mis au jour des schémas linguistiques distincts. Dans les communautés d’anxiété, des mots tels que « panique », « attaque » et « inquiétude » ressortent, souvent liés à des symptômes physiques et à des montées soudaines de peur. Les messages liés à la dépression incluaient fréquemment des termes comme « sans espoir », « sans valeur », « vie » et « plus » (« anymore »), reflétant une profonde tristesse et le sentiment que les choses ne s’amélioreront pas. Dans les discussions sur le BPD, les mots clés se tournent vers les relations et les émotions, notamment « abandon », « relation », « attachement » et « fp » (abréviation de « favorite person », terme courant dans ces groupes). Les messages sur le trouble bipolaire mettent en avant les changements d’humeur et le vocabulaire du traitement, avec des mots comme « manie », « maniaque », « hypomanie », « humeur » et des noms de médicaments tels que « lithium » et « lamictal ». Les modèles ont aussi révélé les zones où les conditions se chevauchent : par exemple, les messages d’anxiété et de dépression peuvent tous deux porter sur la détresse et des sentiments négatifs, ce qui les rend plus faciles à confondre, comme c’est le cas dans le diagnostic en vie réelle.
Des publications en ligne à l’impact réel
Pour un lecteur non spécialiste, le message principal est que les ordinateurs peuvent trier de manière fiable les conversations sur la santé mentale par thème et expliquer quels mots motivent leurs choix, mais qu’ils ne peuvent ni ne doivent diagnostiquer quiconque. Les modèles de cette étude fonctionnent davantage comme des bibliothécaires des espaces de soutien en ligne : ils aident à vérifier si les discussions d’une communauté donnée correspondent vraiment à son objectif déclaré. Cela pourrait aider les modérateurs à garder les échanges pertinents et aider les chercheurs ou cliniciens à mieux comprendre comment les gens décrivent leurs difficultés en dehors des rendez‑vous formels. Avec une supervision humaine attentive et une attention à la confidentialité et à la stigmatisation, de tels outils pourraient un jour soutenir des espaces en ligne plus accueillants et mieux organisés pour parler de santé mentale.
Citation: Sánchez Rodríguez, I., Bianchi, J., Pinelli, F. et al. Understanding mental health discourse on Reddit with transformers and explainability. Sci Rep 16, 6796 (2026). https://doi.org/10.1038/s41598-026-35918-3
Mots-clés: santé mentale, réseaux sociaux, Reddit, IA explicable, classification de texte