Clear Sky Science · fr
Démêler effets directs et pléiotropes des SNP chez la luzerne (Medicago sativa L.) par apprentissage de graphes causaux
Pourquoi c’est important pour les exploitations et l’alimentation
La luzerne est un pilier de l’agriculture moderne : elle nourrit les vaches laitières et contribue à la santé des sols. Pourtant, l’amélioration variétale — obtenir des plantes résistantes à l’hiver, peu vulnérables aux dommages et fournissant une alimentation de haute qualité — est freinée par la grande complexité de son génome. Cette étude propose une nouvelle façon de passer de longues listes confuses de marqueurs ADN à des cartes de cause à effet claires, montrant quelles régions du génome pilotent vraiment des caractères de tige importants, et lesquelles ne font que suivre le mouvement.
Des liens lâches à la causalité
Les études d’association génome entier recherchent des variations d’ADN, appelées SNP, qui apparaissent en association avec un caractère comme la couleur de la tige ou la survie hivernale. Chez la luzerne, la situation est particulièrement embrouillée : l’espèce est tétraploïde, de larges segments d’ADN se déplacent ensemble et les populations sont très mélangées génétiquement. Cela crée un « brouillard de corrélations » où de nombreux marqueurs semblent importants alors que seuls quelques-uns influencent réellement le caractère. Les auteurs soutiennent que les sélectionneurs ont besoin de plus que de simples liens statistiques : ils doivent savoir quels marqueurs se trouvent sur les véritables chemins causaux du génotype vers les caractères observables.
Comment fonctionne le nouveau cadre
Les chercheurs ont construit un cadre en deux étapes qui combine l’apprentissage automatique moderne et des concepts de la théorie des graphes causaux. D’abord, ils ont utilisé une technique appelée Double Machine Learning pour filtrer environ 2 400 SNP sur 500 génotypes de luzerne. Cette étape élimine l’influence de facteurs cachés comme l’appartenance familiale ou la géographie, en utilisant des composantes principales du génome comme variables de substitution. Le résultat est une vision plus nette des marqueurs qui conservent un effet direct sur des traits tels que la couleur de la tige après prise en compte de ces confondeurs. Dans cette vue filtrée, des pics forts et stables du signal sont apparus principalement sur les chromosomes 2 et 4, et certains marqueurs présentaient des tailles d’effet dont les intervalles de confiance excluaient nettement zéro, ce qui suggère une influence causale réelle.
Transformer des marqueurs en cartes génétiques
Dans la seconde étape, l’équipe a utilisé un algorithme d’apprentissage de graphes causaux, connu sous le nom d’algorithme PC, pour relier les marqueurs les plus prometteurs en un réseau orienté. Dans ces diagrammes, les nœuds représentent les SNP et le caractère, et les flèches indiquent la direction la plus probable de l’influence. En supprimant les arêtes qui contredisent des principes biologiques de base (par exemple, un caractère ne peut pas modifier l’ADN sous-jacent) et en ne gardant que les SNP qui alimentent le caractère, les auteurs ont obtenu des cartes compactes et biologiquement cohérentes. Ces réseaux « tournesol » révèlent une structure en couches : un anneau intérieur de SNP Parents Directs qui se connectent directement au caractère, et un anneau extérieur d’Hubs En Amont qui influencent plusieurs parents sans toucher directement le caractère.
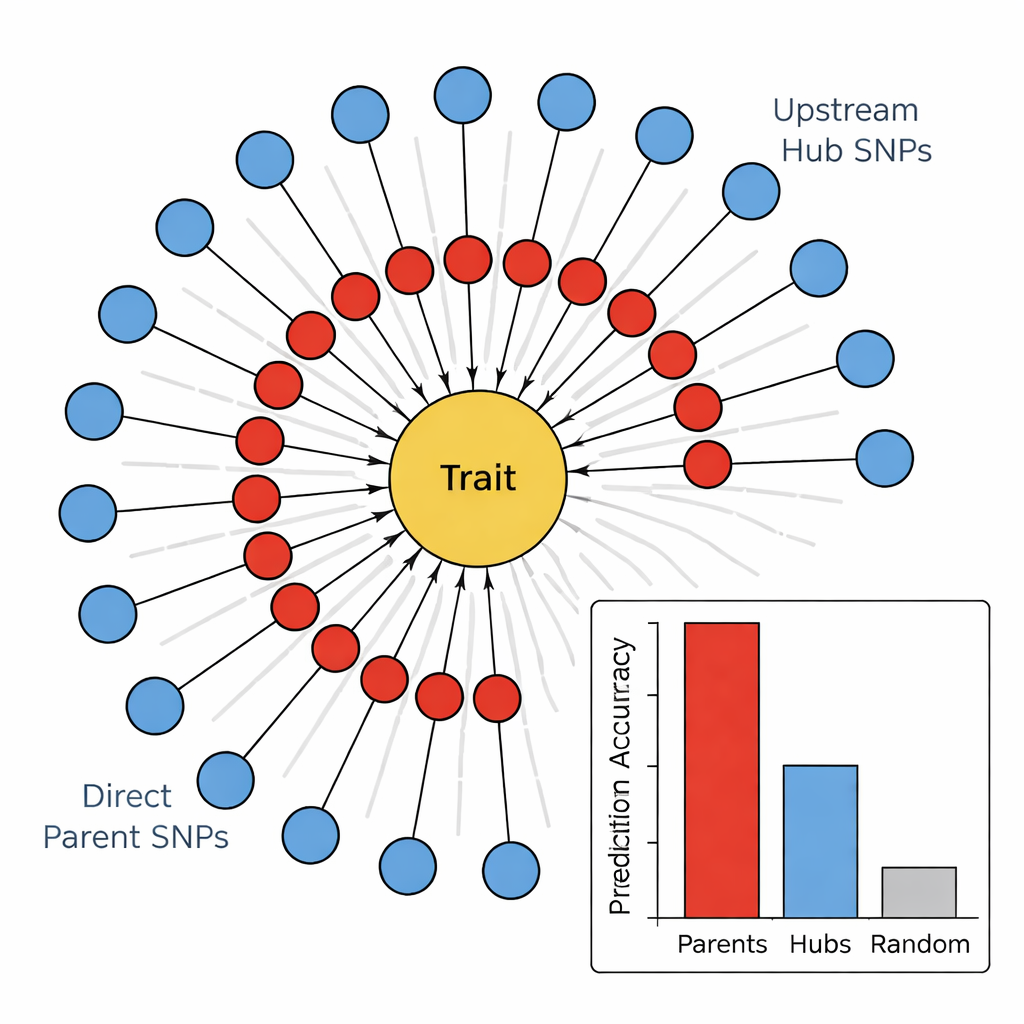
Exécuteurs versus directeurs dans le génome
Pour tester la pertinence de cette hiérarchie, les auteurs ont comparé la capacité prédictive de différents groupes de marqueurs pour quatre traits liés à la tige : couleur de la tige, remplissage de la tige, résistance mécanique et dégâts hivernaux. Pour tous les traits, les SNP Parents Directs étaient systématiquement les meilleurs prédicteurs, expliquant souvent plusieurs fois plus de variation que des marqueurs aléatoires ou que les Hubs En Amont. En revanche, les hubs montraient une puissance prédictive faible voire négative, malgré leur forte connectivité dans le réseau. Lorsque l’équipe a associé ces SNP à des gènes connus, un schéma est apparu : les Parents Directs correspondaient souvent à des enzymes ou des protéines structurales agissant directement sur la paroi cellulaire, les pigments ou les dommages liés au stress, tandis que les Hubs correspondaient plutôt à des facteurs de transcription et des protéines régulatrices ajustant de manière large de nombreuses voies.
Ce que cela implique pour l’amélioration future de la luzerne
Pour les sélectionneurs et les généticiens, l’étude propose une méthode pour percer le bruit des résultats d’association et se concentrer sur les variations d’ADN qui influent réellement sur des traits spécifiques. Les auteurs montrent que combiner un criblage désembrouillé avec des graphes causaux peut constituer un garde-fou contre le surapprentissage, transformant de longues listes de candidats en petits réseaux interprétables et cohérents avec la biologie connue. Concrètement, les SNP Parents Directs deviennent des marqueurs de haute précision pour sélectionner des plantes aux tiges renforcées ou mieux adaptées à l’hiver, tandis que les Hubs En Amont pointent vers des interrupteurs maîtres susceptibles de remodeler des réponses au stress plus larges, au prix de compromis possibles. Cette vision structurée du génome pose les bases d’une sélection génomique plus fiable dans les cultures complexes et pour l’intégration future de couches de données supplémentaires, comme l’expression génique et le métabolisme, dans des modèles cause-à-effet cohérents de la performance des plantes.
Citation: Lee, Y., Medina, C.A. & Xu, Z. Disentangling direct and pleiotropic SNP effects in alfalfa (Medicago sativa L.) using causal graph learning. Sci Rep 16, 5216 (2026). https://doi.org/10.1038/s41598-026-35876-w
Mots-clés: génétique de la luzerne, apprentissage de graphes causaux, sélection génomique, amélioration des plantes, cultures polypoïdes