Clear Sky Science · fr
Stratégie d'optimisation dynamique pilotée par apprentissage par renforcement pour la conception paramétrique de modèles 3D
Des conceptions 3D plus intelligentes avec moins d'essais‑erreurs
Des bâtiments qui attirent le regard aux minuscules pièces mécaniques à l'intérieur de votre téléphone, beaucoup d'objets modernes commencent par des modèles 3D informatiques. Les concepteurs utilisent souvent des modèles « paramétriques », où des curseurs et des formules contrôlent formes, dimensions et motifs. Cela facilite l'exploration de nombreuses options — mais crée aussi un labyrinthe de possibilités impossible à parcourir manuellement. Cet article présente une nouvelle approche d'intelligence artificielle appelée HRL‑DOS qui aide les ordinateurs à naviguer dans ce labyrinthe, améliorant automatiquement les conceptions 3D en termes de résistance, d'utilisation de matériau et de facilité de fabrication.
Le défi d'un trop grand nombre de choix
En conception paramétrique, un objet unique peut dépendre de dizaines ou de centaines de paramètres liés : épaisseurs de paroi, tailles de trous, courbes et règles d'alignement. À mesure que les modèles deviennent plus complexes, ces paramètres interagissent de manière non évidente. Les outils d'optimisation traditionnels s'appuient soit sur des fonctions mathématiques lisses, qui échouent lorsque les conceptions sont irrégulières ou bruitées, soit sur des méthodes de recherche par essais‑erreurs, qui peuvent être terriblement lentes pour des problèmes de grande envergure. Même l'apprentissage par renforcement standard — où un agent IA apprend par essais répétés et rétroaction — peine lorsque l'on doit considérer simultanément toutes les combinaisons possibles de décisions de conception.
Une IA à deux niveaux qui pense comme un concepteur
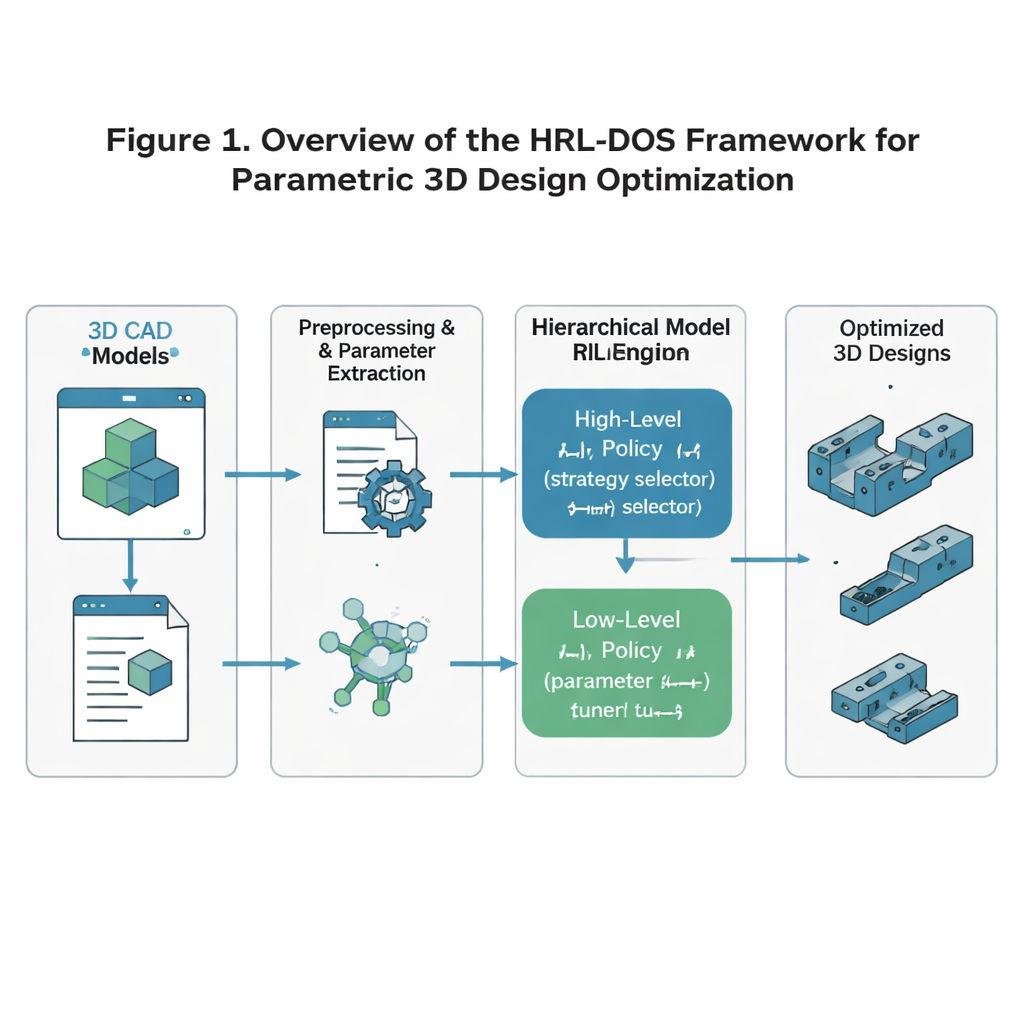
Les auteurs proposent la stratégie d'optimisation dynamique basée sur l'apprentissage par renforcement hiérarchique, ou HRL‑DOS, pour faire face à cette complexité. Plutôt que de traiter la conception comme une unique décision gigantesque, HRL‑DOS divise la tâche en deux niveaux. Une politique de haut niveau choisit une direction générale pour la conception — par exemple privilégier un faible poids, plus de symétrie ou une marge de sécurité accrue. Une politique de bas niveau ajuste ensuite des paramètres individuels, comme des dimensions spécifiques ou le positionnement des éléments, dans le cadre de ce plan général. Les deux niveaux reçoivent des retours basés sur la performance du modèle actuel sur trois objectifs principaux : stabilité structurelle, efficacité géométrique et fabricabilité. Cette structure en couches reflète la façon de travailler des concepteurs humains : décider d'abord d'un concept, puis affiner les détails.
Transformer des modèles 3D bruts en données exploitables
Pour entraîner ce système, les chercheurs partent du jeu de données ABC, une large collection publique de modèles 3D industriels détaillés tels que brides, engrenages, leviers et plaques de montage. Ils prétraitent chaque modèle pour que l'IA voie une représentation propre et cohérente : la géométrie est normalisée à une échelle et une orientation standard ; les dimensions et caractéristiques clés sont extraites sous forme de paramètres ; et les règles de fabrication — comme l'épaisseur minimale des parois ou les angles d'overhang admissibles — sont codées en contraintes. Ces paramètres sont ensuite transformés en une description « latente » compacte qui décourage naturellement les formes impossibles ou instables. Le résultat est un état numérique que l'IA peut modifier en toute sécurité tout en respectant les règles d'ingénierie de base.
Apprendre à améliorer des pièces réalistes
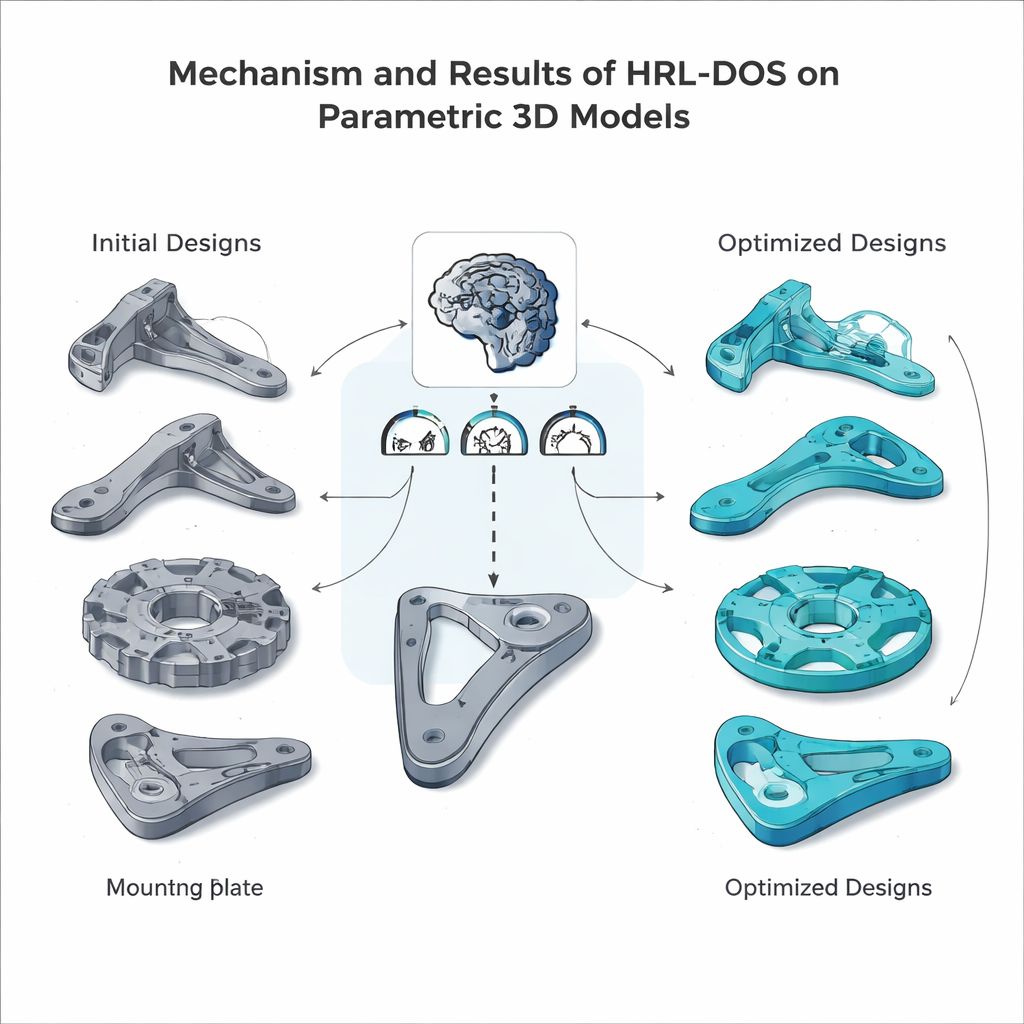
Dans cet environnement préparé, les agents hiérarchiques proposent à répétition de nouvelles conceptions, lancent des simulations pour estimer le poids et les contraintes, vérifient la fabricabilité et reçoivent un score de récompense combiné. Au fil de nombreux épisodes d'entraînement, l'agent de haut niveau apprend quelles orientations stratégiques sont payantes, tandis que l'agent de bas niveau découvre quels ajustements de paramètres délivrent réellement ces objectifs. L'équipe a testé HRL‑DOS sur plusieurs pièces représentatives du jeu de données — une bride nervurée, un disque d'engrenage, une poignée de levier et une plaque de montage — et a comparé ses performances à plusieurs alternatives avancées, incluant un apprentissage par renforcement classique, des hybrides avec algorithmes génétiques et d'autres outils d'aide à la conception assistée par IA. HRL‑DOS a atteint de bonnes solutions environ 27 % plus rapidement et produit des modèles avec des scores de qualité globaux supérieurs d'environ 18 %.
Des conceptions solides, réalisables et flexibles
Au‑delà des performances brutes, HRL‑DOS s'est montré meilleur pour respecter des limites d'ingénierie strictes. Il a généré beaucoup moins de conceptions violant les contraintes de sécurité ou de fabrication et a obtenu des scores de fabricabilité plus élevés sur des contrôles tels que les angles d'overhang, les cavités internes et les tolérances. La méthode a aussi bien généralisé à de nouveaux types de pièces inédits et est restée robuste lorsque les données d'entrée étaient bruitées ou partiellement manquantes — un trait important pour les flux de travail de conception réels. Ensemble, ces résultats suggèrent que l'apprentissage par renforcement hiérarchique peut servir de moteur pratique pour la conception assistée par ordinateur intelligente, aidant architectes et ingénieurs à explorer plus d'options en moins de temps tout en gardant leurs modèles sûrs, efficaces et prêts pour la fabrication.
Citation: Zhong, G., Vijay, V.C. Reinforcement learning-driven dynamic optimization strategy for parametric design of 3D models. Sci Rep 16, 5041 (2026). https://doi.org/10.1038/s41598-026-35863-1
Mots-clés: conception 3D paramétrique, apprentissage par renforcement, optimisation de conception, conception assistée par ordinateur, ingénierie générative