Clear Sky Science · fr
HEViTPose : vers une estimation 2D des poses humaines à la fois précise et efficace avec une attention en réduction spatiale en groupe en cascade
Apprendre aux ordinateurs à lire le langage du corps
Des applications de fitness aux systèmes d'aide à la conduite, de nombreuses technologies reposent désormais sur la capacité d'un ordinateur à comprendre comment les personnes se déplacent. Cette compétence, appelée estimation de la pose humaine, consiste à repérer les positions des articulations — comme les épaules, les genoux et les chevilles — dans une image ou une vidéo. Le défi est d'y parvenir avec suffisamment de précision et de rapidité pour une utilisation en temps réel sur du matériel courant. Cet article présente HEViTPose, une nouvelle méthode qui vise à conserver une haute précision tout en demandant moins de puissance de calcul que beaucoup de systèmes actuels.
Pourquoi repérer les articulations sur une image est si difficile
À première vue, localiser les articulations peut sembler simple : il suffit de chercher les bras et les jambes. En pratique, les personnes apparaissent à des tailles variées, dans des poses inhabituelles, dans des scènes encombrées, et souvent partiellement cachées par des objets comme des meubles ou des voitures. Les systèmes modernes d'estimation de pose gèrent généralement cela en créant une « carte de chaleur » détaillée pour chaque articulation, où des points lumineux indiquent les positions probables. Les heatmaps sont très précises mais coûteuses à calculer. Les systèmes traditionnels reposent principalement sur des réseaux de neurones convolutionnels, bons pour détecter des motifs locaux mais qui doivent devenir plus profonds et plus lourds pour capturer les relations à longue portée sur l'ensemble du corps. Les modèles récents basés sur des transformers excellent à capter ces liens à longue distance, mais ils nécessitent souvent de grands jeux de données et des calculs importants, ce qui complique leur usage en temps réel ou sur des appareils de petite taille.
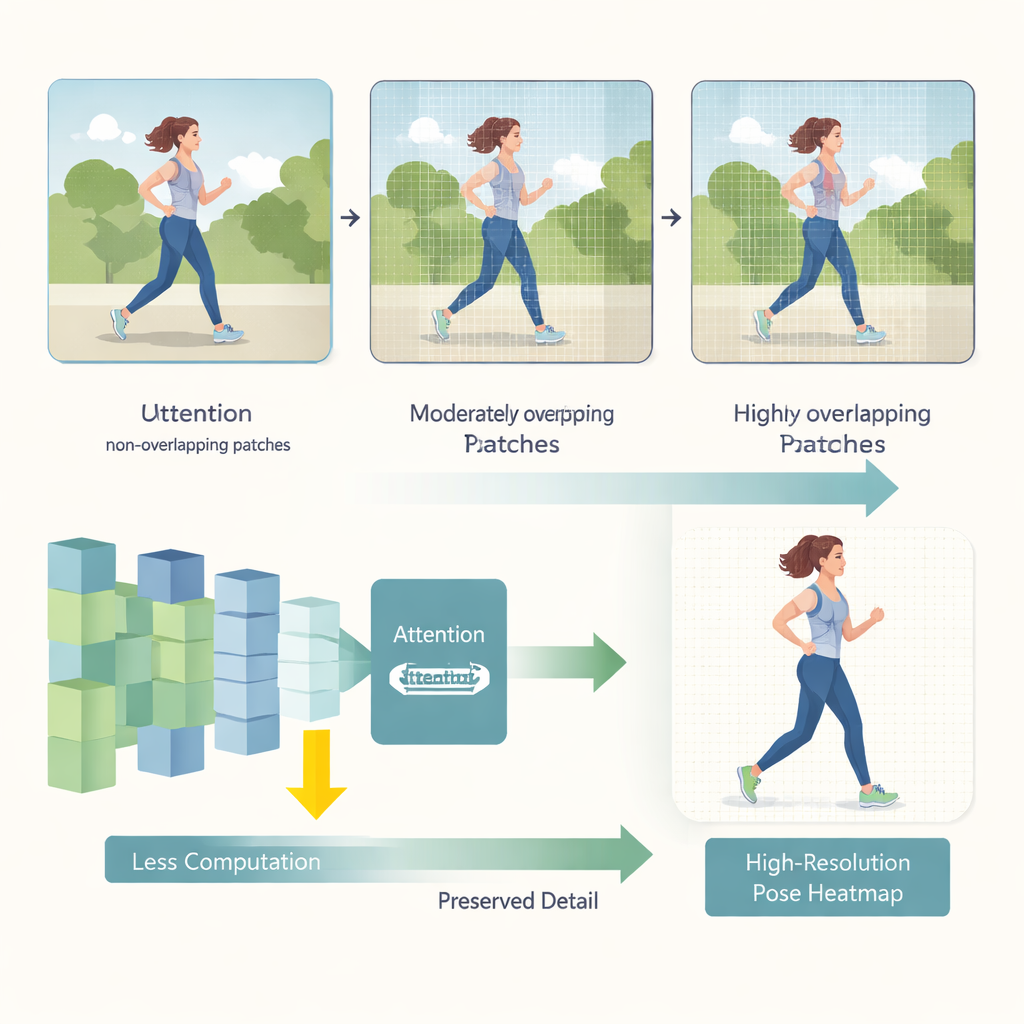
Aperçus chevauchants pour une vision plus lisse
HEViTPose commence par repenser la façon dont une image est découpée en morceaux pour l'analyse. Les premiers modèles transformer découpaient souvent l'image en tuiles non chevauchantes, ce qui peut rompre la continuité visuelle entre régions voisines — par exemple en coupant le bras d'une personne au bord d'une tuile. HEViTPose s'appuie sur une idée d'embedding de patchs chevauchants et introduit une mesure claire et réglable appelée Patch Embedding Overlap Width (PEOW). Le PEOW compte simplement le nombre de pixels partagés par les tuiles voisines le long de leurs frontières. En faisant varier systématiquement ce chevauchement, les auteurs montrent qu'un chevauchement modéré permet au réseau de mieux « ressentir » la transition douce des couleurs et des formes d'une tuile à l'autre. Cette meilleure continuité locale conduit à des positions d'articulations plus précises, sans faire exploser la taille du modèle ni le coût de calcul.
Une attention plus intelligente pour moins de calcul
La deuxième innovation clé est un nouveau module d'attention nommé Cascaded Group Spatial Reduction Multi-Head Attention (CGSR-MHA). Les mécanismes d'attention indiquent au réseau quelles parties de l'image doivent influencer chaque prédiction, mais ils évoluent généralement mal lorsque la taille des images augmente. CGSR-MHA s'attaque à ce problème de trois manières. D'abord, il divise les caractéristiques en groupes, de sorte que chaque groupe traite seulement une partie de l'information au lieu de tout gérer à la fois. Ensuite, il réduit la résolution spatiale à l'intérieur de chaque groupe avant de calculer l'attention, réduisant fortement le nombre d'opérations. Enfin, il utilise plusieurs petites têtes d'attention plutôt que quelques grandes, préservant la diversité de ce à quoi le modèle peut « prêter attention » tout en maintenant un coût faible. Des réglages soigneusement choisis du nombre de groupes, du facteur de réduction et du nombre de têtes permettent de trouver un équilibre entre vitesse et précision.
Des modèles légers qui restent compétitifs
Pour évaluer HEViTPose, les auteurs le testent sur deux benchmarks largement utilisés : le jeu de données MPII d'activités humaines quotidiennes et le plus grand jeu COCO contenant des personnes dans de nombreuses scènes. Sur plusieurs tailles de modèles, HEViTPose atteint ou s'approche de la précision des meilleurs systèmes d'estimation de pose tout en utilisant bien moins de paramètres et de calcul. Par exemple, une version atteint une précision comparable à un réseau haute résolution populaire (HRNet) tout en réduisant le nombre de paramètres appris de plus de 60 % et en diminuant la quantité de calcul de plus de 40 %. Comparé à un autre modèle hybride moderne qui mélange convolutions et transformers, HEViTPose offre des performances similaires mais s'exécute environ 2,6 fois plus vite sur un processeur graphique. Ces économies se traduisent directement par des performances en temps réel plus fluides et des exigences matérielles réduites.
Ce que cela signifie pour les applications courantes
En termes simples, HEViTPose montre qu'il n'est pas nécessaire de choisir entre précision et efficacité pour apprendre aux ordinateurs à lire le langage corporel humain. En chevauchant soigneusement les morceaux d'image qu'il examine et en repensant la façon dont l'attention est calculée à l'intérieur du réseau, le système peut localiser les articulations avec une grande précision tout en restant compact et rapide. Cela le rend attractif pour des usages réels tels que le suivi sportif, la vidéosurveillance, l'interaction homme–robot et la surveillance en véhicule, où la vitesse et la consommation d'énergie comptent. Les idées derrière HEViTPose — chevauchement intelligent et attention efficace — pourraient aussi être adaptées à des tâches apparentées comme le suivi de la pose animale ou la détection de points faciaux, apportant potentiellement des « yeux numériques » plus précis à de nombreux appareils sans nécessiter du matériel de niveau supercalculateur.
Citation: Wu, C., Chen, Z., Ying, B. et al. HEViTPose: towards high-accuracy and efficient 2D human pose estimation with cascaded group spatial reduction attention. Sci Rep 16, 5637 (2026). https://doi.org/10.1038/s41598-026-35859-x
Mots-clés: estimation de la pose humaine, vision par ordinateur, transformer en vision, apprentissage profond efficace, mécanisme d'attention