Clear Sky Science · fr
Un cadre hybride CNN et apprentissage par renforcement pour l’identification du locuteur utilisant des caractéristiques Mel‑Spectrogram et transformée en ondelettes continue
Pourquoi votre voix peut être une clé numérique
Imaginez déverrouiller votre compte bancaire, votre porte d’entrée ou votre téléphone en n’utilisant que votre voix. Pour que cela soit sûr, les ordinateurs doivent distinguer une personne d’une autre de manière fiable, même en présence de bruit de fond, d’émotion ou d’un mauvais microphone. Cet article explore une nouvelle manière d’apprendre aux machines à reconnaître qui parle, et non seulement ce qui est dit, en combinant des techniques modernes d’apprentissage profond avec une forme d’apprentissage par essai‑erreur empruntée à la robotique.
Des ondes sonores aux empreintes vocales
La voix de chaque personne porte des indices subtils façonnés par la taille et la forme des voies vocales, la manière dont vibrent les plis vocaux et le style de parole. Les chercheurs ont commencé par se demander : quelles propriétés mesurables du discours enregistré diffèrent réellement d’une personne à l’autre ? En utilisant 2 703 extraits audio provenant de 40 locuteurs anglophones dans le jeu de données LibriSpeech, ils ont analysé 22 caractéristiques acoustiques simples, telles que la variation de loudness, l’énergie dans différentes bandes de fréquence, le rythme et une mesure appelée entropie qui capture la complexité ou l’imprévisibilité du son. Des tests statistiques ont montré que 21 de ces 22 caractéristiques contenaient des informations fortement spécifiques au locuteur, l’entropie et l’énergie haute fréquence se distinguant comme particulièrement distinctives. Autrement dit, « l’empreinte vocale » d’une personne se répartit sur de nombreux aspects du son, et pas seulement sur la hauteur ou le volume.
Deux manières de transformer le son en images
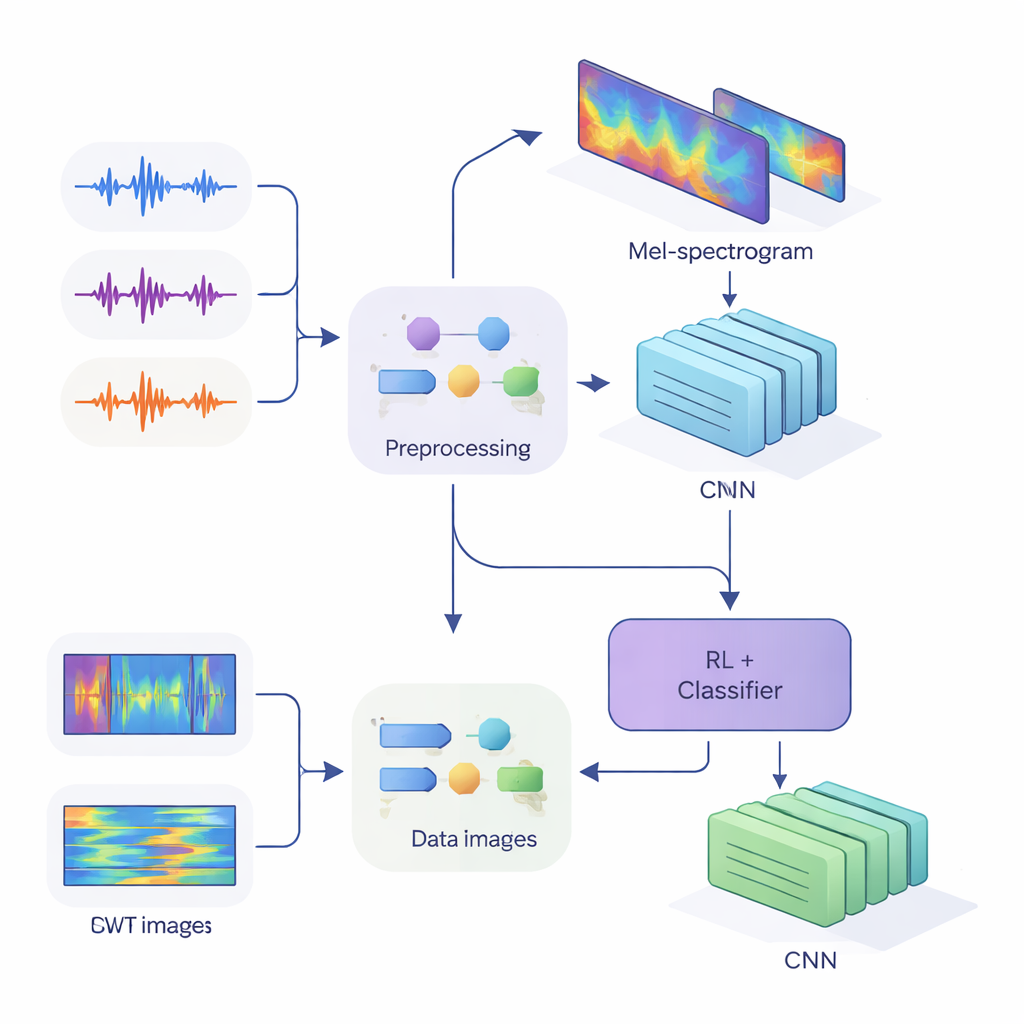
Pour fournir ces indices aux réseaux neuronaux modernes, l’équipe a converti l’audio unidimensionnel en images bidimensionnelles qui captent comment l’énergie évolue dans le temps et en fréquence. Dans la première méthode, ils ont utilisé des Mel‑spectrogrammes, qui imitent la manière dont l’oreille humaine regroupe les fréquences et sont standard en technologie vocale. Dans la seconde méthode, ils ont utilisé la transformée en ondelettes continue, une façon plus flexible d’examiner à la fois les sons courts et aigus et les voyelles plus longues. Après un nettoyage soigné de l’audio — suppression des silences, normalisation du volume et ajout de petites distorsions comme du bruit et des variations de hauteur pour rendre le système plus robuste — ils ont produit des « images » Mel de taille 80 par 313 et des « images » ondelettes de taille 128 par 128, prêtes à être traitées par des réseaux de neurones convolutionnels (CNN).
Apprendre au réseau à écouter et à douter
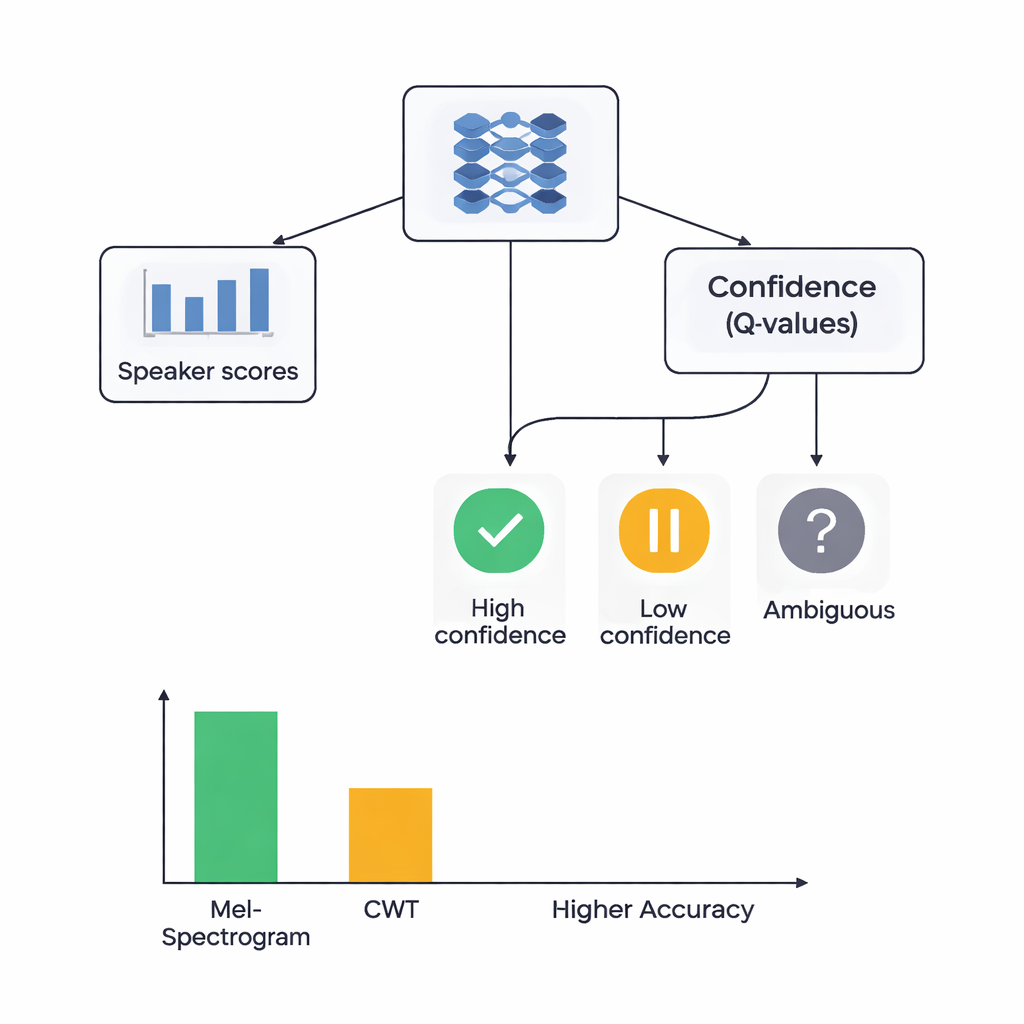
Le cœur de l’étude est une architecture hybride qui réunit deux styles d’apprentissage. D’abord, des CNN parcourent les images Mel ou ondelettes pour extraire des motifs qui tendent à appartenir à des locuteurs particuliers, à la manière dont les réseaux de reconnaissance d’images apprennent à détecter des yeux ou des contours. Pour le système basé sur Mel, les auteurs ajoutent un module d’auto‑attention qui permet au réseau de se concentrer sur les segments temporels les plus informatifs. Par‑dessus ces extracteurs de caractéristiques, ils placent un composant d’apprentissage par renforcement (RL) qui apprend à quel point le système doit être confiant dans chaque décision. Plutôt que de toujours faire un choix tranché, la partie RL attribue des valeurs à des actions telles que « accepter comme hypothèse haute confiance », « considérer comme faible confiance » ou « marquer comme ambigu ». Au fil de nombreuses séances d’entraînement, elle est récompensée lorsque les décisions confiantes sont correctes, orientant le réseau vers des jugements mieux calibrés.
Quelle est la performance du système hybride ?
Les chercheurs ont comparé quatre modèles : Mel avec RL, Mel sans RL, ondelettes avec RL et ondelettes sans RL. Tous ont été testés selon une validation croisée à cinq volets soignée, ce qui signifie que chaque extrait audio a servi à la fois pour l’entraînement et pour le test selon différents cycles. Le système Mel plus RL a obtenu les meilleurs résultats, identifiant correctement le locuteur dans environ 88 % des cas et montrant une séparation quasi parfaite entre locuteurs selon une mesure standard de pouvoir discriminant. Le système ondelettes plus RL a atteint environ 78 % de précision. De manière cruciale, l’ajout du composant RL a amélioré les performances pour les deux types de caractéristiques d’environ 3 points de pourcentage et a rendu les résultats plus cohérents entre les différentes découpes des données. Davantage de classes de locuteurs ont atteint une reconnaissance de haute qualité lorsque le RL était inclus, suggérant que les décisions tenant compte de la confiance ont aidé particulièrement pour les voix difficiles ou facilement confondues.
Ce que cela signifie pour la sécurité vocale au quotidien
Pour un public non spécialiste, la conclusion principale est que des vérifications d’identité fiables basées sur la voix nécessitent à la fois des représentations riches du son et une saine dose de doute de la part de la machine. Ce travail montre que les Mel‑spectrogrammes inspirés de l’oreille, combinés à l’attention et à un apprentissage par renforcement capable de dire « je ne suis pas sûr », surpassent des images ondelettes plus exotiques pour la tâche de différencier les locuteurs. Si l’étude utilise un jeu de données relativement petit et propre et n’est pas encore adaptée aux conditions réelles bruyantes, elle démontre que l’ajout d’une couche sensible à la confiance au‑dessus de réseaux profonds peut rendre l’authentification vocale à la fois plus précise et plus digne de confiance — une étape importante si nos voix doivent devenir des clés numériques sécurisées.
Citation: Heir, F.M., Najafzadeh, H. & Erfani, S. A hybrid CNN and reinforcement learning framework for speaker identification using Mel-Spectrogram and continuous wavelet transform features. Sci Rep 16, 5954 (2026). https://doi.org/10.1038/s41598-026-35858-y
Mots-clés: identification du locuteur, biométrie vocale, apprentissage profond, apprentissage par renforcement, Mel-spectrogrammes