Clear Sky Science · fr
Un cadre général pour la réduction dimensionnelle non paramétrique adaptive
Pourquoi compresser les mégadonnées est important
La vie moderne fonctionne grâce aux données : scanners médicaux, historiques d’achats en ligne, photos, fils d’actualité, et plus encore. Chaque enregistrement peut comporter des centaines ou des milliers de mesures, ce qui complique le stockage, l’analyse ou même la visualisation. Les scientifiques utilisent la « réduction de dimensionnalité » pour condenser cette complexité en images et modèles plus simples tout en conservant les motifs importants. Mais les outils populaires d’aujourd’hui exigent souvent de nombreux choix manuels et des ajustements par essais‑erreurs. Cet article présente une méthode permettant aux données elles‑mêmes de décider comment mieux se compresser, visant des visualisations plus nettes, un apprentissage plus précis et moins d’essais pour l’utilisateur.
Des lignes simples aux réalités courbes
Un outil classique pour simplifier les données, l’analyse en composantes principales (PCA), fonctionne comme éclairer un objet et regarder son ombre : il trouve les directions planes qui expliquent le plus de variation. Cela est puissant quand la structure des données est à peu près droite ou plane. Mais les données réelles — comme des images, des textes ou des relevés de capteurs — reposent souvent sur des surfaces courbes cachées dans un espace de haute dimension. Au cours des vingt dernières années, de nouvelles méthodes « non linéaires » comme Isomap, Locally Linear Embedding (LLE), le plongement spectral et UMAP ont été conçues spécifiquement pour révéler ces formes sinueuses. Elles s’appuient sur des voisinages locaux : pour chaque point, elles regardent ses voisins les plus proches et tentent de préserver ces relations à petite échelle lorsqu’elles dessinent une représentation de plus faible dimension. Cependant, ces méthodes forcent l’utilisateur à choisir deux réglages clés : combien de voisins utiliser et sur combien de dimensions projeter. Un mauvais choix peut rendre le résultat trompeur ou coûteux en calcul.
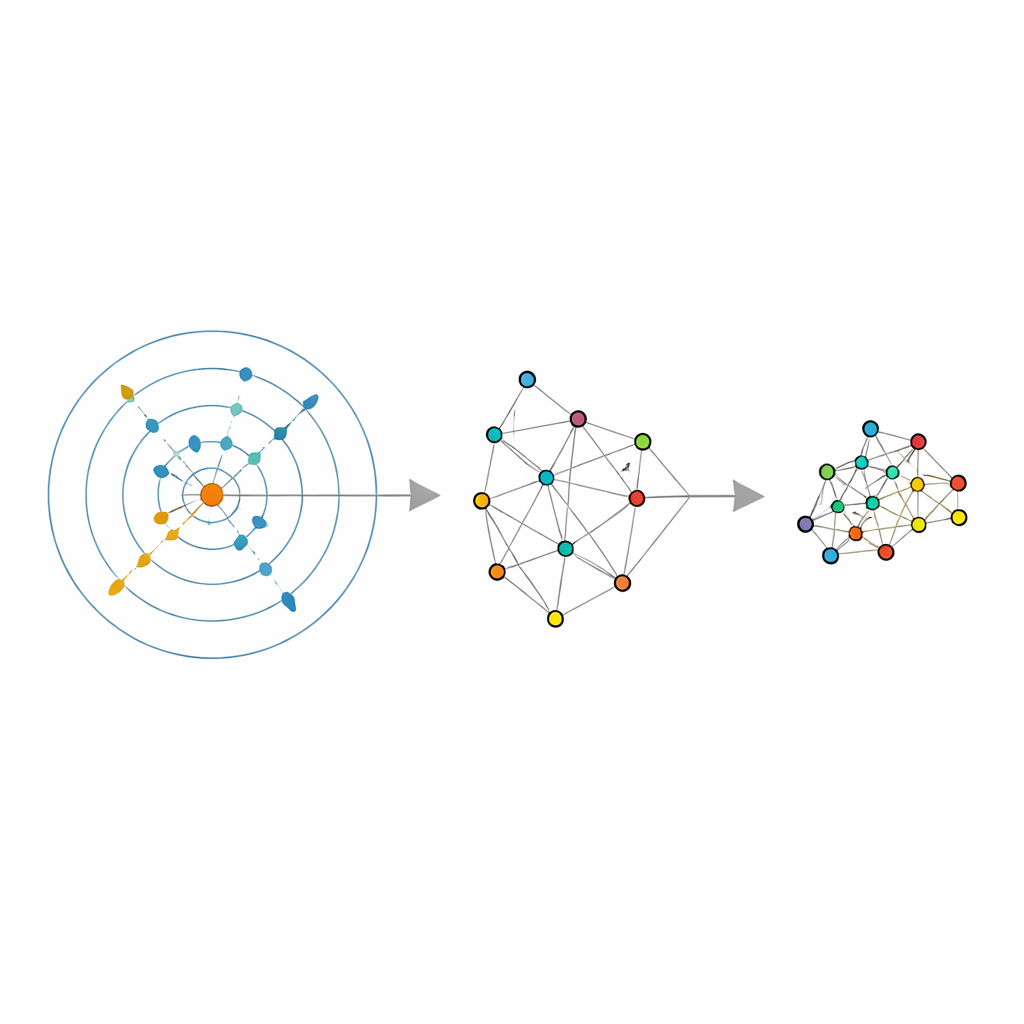
Laisser les données choisir leur voisinage
Les auteurs s’appuient sur un outil statistique récent appelé estimateur de dimension intrinsèque, qui cherche à répondre à une question simple : combien de directions indépendantes les données parcourent‑elles réellement, une fois le bruit éliminé ? Leur estimateur, nommé ABIDE, va plus loin. Autour de chaque point, il recherche automatiquement un voisinage qui paraît raisonnablement homogène — ni trop petit et bruyant, ni trop grand et déformé. Ce faisant, il renvoie deux informations : une estimation globale de la dimension vraie des données et une taille de voisinage adaptée pour chaque point. Cela transforme le « nombre de voisins » habituel et fixe en une quantité localement adaptive qui peut croître dans les régions clairsemées et se réduire dans les zones denses, correspondant à la densité effective des données.
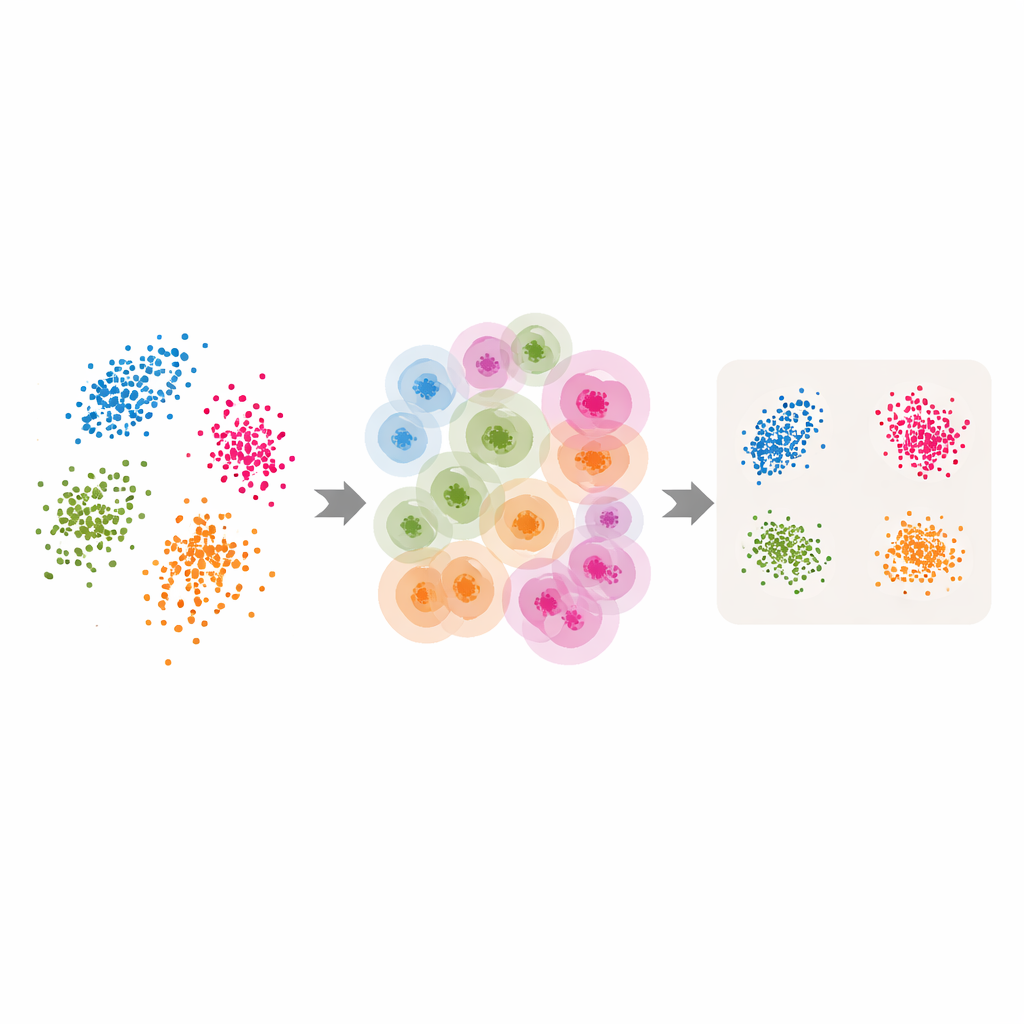
Transformer les outils classiques en outils adaptatifs
Armés de ces voisinages adaptatifs et de l’estimation de la dimension intrinsèque, les auteurs adaptent plusieurs méthodes populaires de réduction dimensionnelle et de clustering. Pour LLE, ils remplacent le nombre unique de voisins choisi par l’utilisateur par les valeurs par point renvoyées par ABIDE, et ils fixent la dimension cible égale à la dimension intrinsèque estimée. L’algorithme apprend alors à reconstruire chaque point à partir d’un groupe local soigneusement choisi avant de trouver une disposition globale de basse dimension qui préserve au mieux ces reconstructions locales. Des idées similaires sont appliquées au clustering spectral — où un graphe de similarités entre points sert au regroupement — et à UMAP, qui construit une carte floue des connexions entre points. Dans chaque cas, la taille rigide du voisinage est remplacée par une structure flexible et pilotée par les données qui suit la géométrie naturelle des données.
Tests sur fleurs, chiffres, textes et formes synthétiques
Pour évaluer si cette approche adaptive est payante, les auteurs réalisent des expériences sur plusieurs bancs d’essai : les mesures classiques de l’iris, des images de chiffres manuscrits (MNIST), des articles de presse représentés par des embeddings de modèles de langage, et des formes tridimensionnelles synthétiques avec ajout de bruit. Ils comparent les versions adaptatives aux réglages standards des logiciels et à des grilles d’hyperparamètres finement ajustées. Dans les tâches non supervisées telles que le clustering et la visualisation, les méthodes adaptatives produisent généralement des grappes plus claires, des groupements plus serrés et de meilleurs scores sur les mesures de qualité habituelles. Par exemple, sur des variétés complexes à densité inégale, les méthodes adaptatives retrouvent bien mieux la structure vraie que les versions à voisinage fixe. Dans les tests supervisés, où les données réduites sont utilisées par un classifieur, l’approche adaptive égalise ou dépasse de nouveau les meilleurs choix à réglage fixe, sans réglages exhaustifs.
Ce que cela signifie pour l’analyse de données au quotidien
Pour les non‑experts comme pour les praticiens, le message principal est que compresser les données n’a pas à reposer sur des conjectures. En utilisant la géométrie propre aux données pour décider « combien de voisins » et « combien de dimensions », ce cadre transforme des outils largement utilisés comme LLE, le clustering spectral et UMAP en versions plus intelligentes et robustes d’eux‑mêmes. Le résultat est des vues de basse dimension plus fiables — des graphiques et caractéristiques qui reflètent mieux la forme réelle des données — tout en réduisant souvent le temps consacré à la recherche manuelle d’hyperparamètres. Concrètement, cela signifie que des tâches telles que la visualisation de grandes collections d’images, le regroupement de documents ou la préparation d’entrées pour des modèles prédictifs peuvent devenir à la fois plus simples et plus fiables, simplement en laissant les données guider de façon adaptive la manière dont elles sont comprimées.
Citation: Di Noia, A., Ravenda, F. & Mira, A. A general framework for adaptive nonparametric dimensionality reduction. Sci Rep 16, 9028 (2026). https://doi.org/10.1038/s41598-026-35847-1
Mots-clés: réduction de dimensionnalité, apprentissage de variétés, plus proches voisins, dimension intrinsèque, visualisation de données