Clear Sky Science · fr
Optimiseur amélioré basé sur la distribution normale généralisée avec méthode de réparation gaussienne et apprentissage inverse de Cauchy pour la sélection de caractéristiques
Pourquoi choisir les bonnes données importe
La vie moderne repose sur les données, des scans médicaux et dossiers bancaires aux flux des réseaux sociaux. Mais plus de données n’est pas toujours préférable. Lorsque les ordinateurs doivent apprendre à partir de milliers de mesures brutes simultanément, ils peuvent devenir plus lents, plus coûteux à exploiter et, de façon contre-intuitive, moins précis. Cet article propose une manière plus intelligente de trier ces mesures et de ne garder que celles qui comptent réellement, en utilisant un nouvel algorithme appelé Binary Adaptive Generalized Normal Distribution Optimizer, ou BAGNDO.
Le problème d’un trop grand nombre d’indices
Imaginez diagnostiquer une maladie avec des centaines de tests de laboratoire, d’imageries et de réponses à des questionnaires. Beaucoup de ces « caractéristiques » peuvent être bruitées, redondantes ou simplement sans rapport, et les fournir toutes à un classifieur peut davantage perturber que d’aider. La sélection de caractéristiques vise à choisir un sous-ensemble plus petit et plus informatif d’entrées afin que les modèles d’apprentissage automatique deviennent plus rapides, moins coûteux et plus fiables. Des filtres statistiques simples peuvent éliminer des caractéristiques manifestement inutiles, mais ils n’adaptent pas leurs choix au modèle spécifique utilisé et manquent souvent des combinaisons subtiles de variables. Des méthodes « wrapper » plus avancées évaluent des ensembles de caractéristiques en testant directement les performances d’un classifieur, mais cela crée un problème de recherche énorme : le nombre de sous-ensembles possibles explose à mesure que le nombre de caractéristiques augmente.
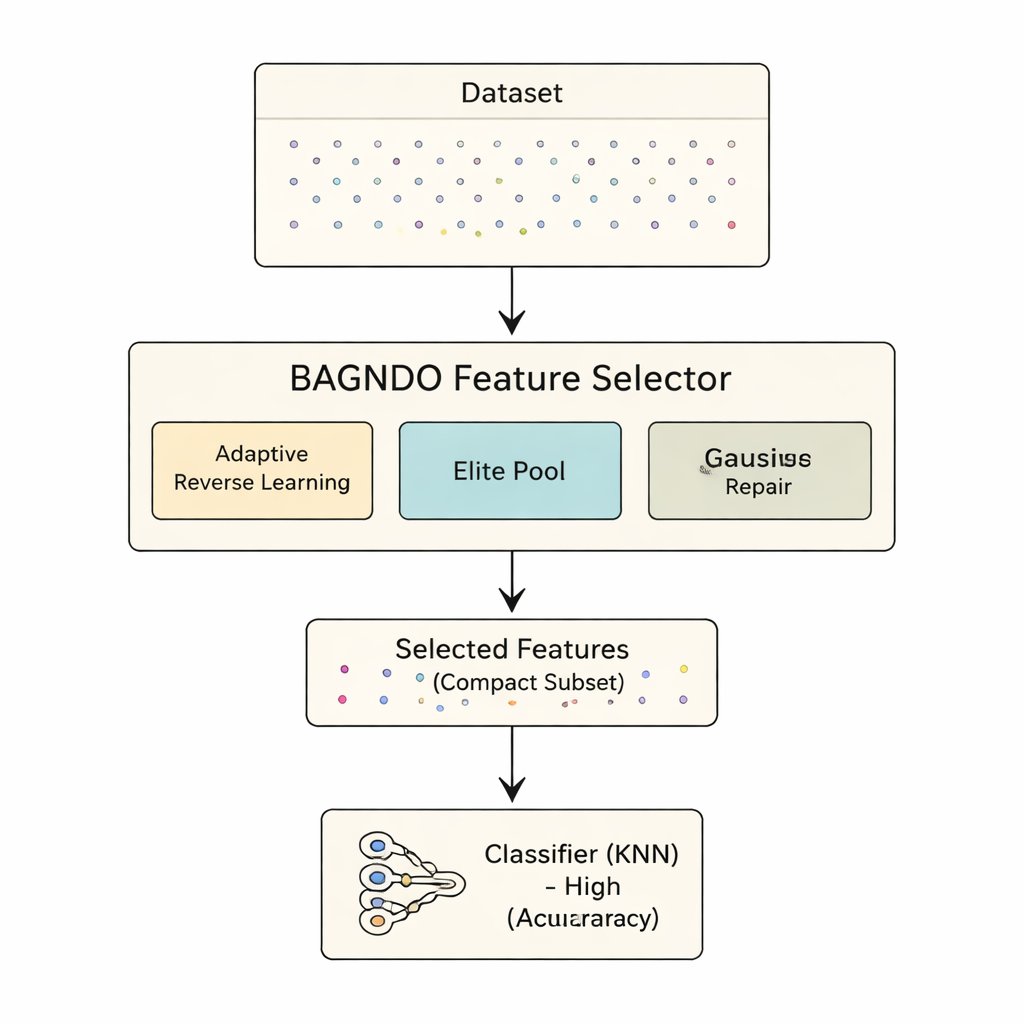
Chercher intelligemment plutôt qu’à l’aveugle
Pour gérer cette explosion, les chercheurs s’appuient sur des algorithmes métaheuristiques — des stratégies de recherche inspirées par des processus naturels ou physiques qui équilibrent exploration large et raffinement local. Une de ces méthodes, le Generalized Normal Distribution Optimizer (GNDO), considère les solutions candidates comme si elles étaient tirées d’une courbe en cloche flexible et déplace progressivement cette courbe vers de meilleures réponses. GNDO a bien fonctionné en ingénierie et dans les applications énergétiques, mais il a tendance à se fixer trop tôt sur des solutions seulement correctes et à peiner à équilibrer son exploration globale avec l’affinage local lorsqu’il est appliqué à la sélection de caractéristiques. Les auteurs identifient cela comme une lacune critique : l’élégance mathématique de GNDO ne se traduit pas automatiquement par de bonnes performances sur des décisions binaires et de haute dimension concernant les caractéristiques à conserver.
Une mise à niveau en trois volets d’un moteur classique
Le cadre proposé BAGNDO améliore GNDO avec trois idées coordonnées. D’abord, une stratégie Adaptive Cauchy Reverse Learning génère régulièrement des versions « en miroir » des solutions actuelles en utilisant une distribution de probabilité à longue traîne. Cela encourage des sauts audacieux vers des régions inexplorées de l’espace de recherche, empêchant l’algorithme de rester coincé dans des minima locaux. Ensuite, une stratégie de pool d’élite conserve non seulement la meilleure solution unique, mais un petit groupe de meilleurs éléments ainsi qu’un candidat « guide » combiné. Ce groupe de direction plus riche aide à maintenir la diversité tout en orientant la recherche vers des régions prometteuses. Enfin, une méthode de réparation des pires solutions basée sur la distribution gaussienne examine les candidats les plus faibles et les pousse vers des motifs appris auprès du groupe d’élite, recyclant ainsi efficacement de mauvaises solutions en solutions meilleures au lieu de les jeter purement et simplement.
Mettre la méthode à l’épreuve
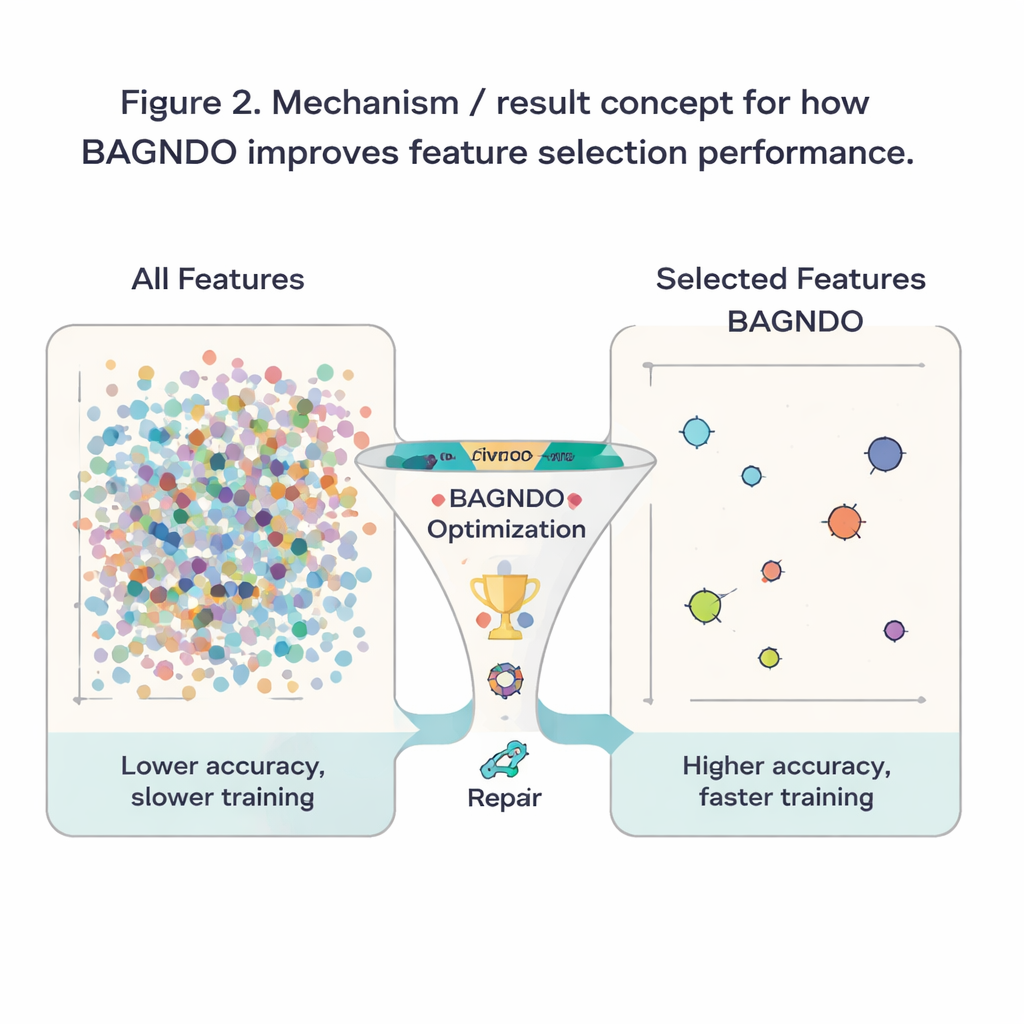
Pour vérifier l’efficacité de ces idées en pratique, les auteurs ont appliqué BAGNDO à 18 jeux de données de référence bien connus du dépôt UCI, couvrant le diagnostic médical, les jeux, les signaux et plus encore. Dans chaque cas, l’algorithme a recherché un sous-ensemble de caractéristiques permettant à un classifieur k-plus-proches-voisins standard de faire des prédictions précises. BAGNDO a été opposé à neuf concurrents solides, y compris l’optimisation par essaim de particules, des méthodes de type génétique et plusieurs algorithmes modernes inspirés des essaims. Sur ces tests, BAGNDO a systématiquement trouvé des ensembles de caractéristiques plus compacts tout en conservant, et souvent en améliorant, la précision des prédictions. Il a obtenu la meilleure précision avec les sous-ensembles les plus compacts dans 14 des 18 jeux de données, et des tests statistiques ont confirmé que ces gains n’étaient pas dus au hasard.
Ce que cela signifie pour l’apprentissage automatique courant
Pour un non-spécialiste, le résultat peut se résumer simplement : les auteurs ont construit un « filtre de caractéristiques » plus discipliné qui aide les algorithmes d’apprentissage à se concentrer sur ce qui compte vraiment dans un jeu de données. En mieux conciliant exploration large, orientation par l’élite et réparation des mauvais candidats, BAGNDO élagage les entrées superflues tout en conservant ou en augmentant la précision. Cela se traduit par des modèles plus rapides, des coûts de stockage et de calcul réduits, et souvent des éclairages plus clairs sur quelles mesures ou quelles questions sont les plus informatives. Bien que la méthode soit plus exigeante en calcul que certaines alternatives plus simples, elle offre un outil puissant pour les problèmes où précision et interprétabilité sont primordiales, du support de décision médical à la surveillance industrielle et au-delà.
Citation: Ghetas, M., Elaziz, M.A. & Issa, M. Enhanced generalized normal distribution optimizer with Gaussian distribution repair method and cauchy reverse learning for features selection. Sci Rep 16, 4794 (2026). https://doi.org/10.1038/s41598-026-35804-y
Mots-clés: sélection de caractéristiques, optimisation métaheuristique, apprentissage automatique, réduction de dimension, précision de classification