Clear Sky Science · fr
Génération sécurisée de données de cas de test multipartites via des réseaux antagonistes génératifs
Pourquoi des tests logiciels plus intelligents comptent
Les usines modernes, les réseaux électriques et les installations industrielles fonctionnent grâce à des logiciels complexes qui doivent communiquer parfaitement via des réseaux numériques. Une petite erreur dans l’échange de messages entre deux systèmes peut provoquer des pannes d’équipement, des incidents de sécurité ou des cyberattaques. Pourtant, les données de test nécessaires pour déceler ces bogues cachés sont souvent réparties entre de nombreuses organisations et verrouillées par des règles de confidentialité et le secret commercial. Cet article présente une nouvelle méthode permettant aux entreprises de coopérer pour générer des cas de test puissants sans jamais partager leurs données sensibles brutes.
Le défi des tests dans un monde connecté
Les outils de test logiciel traditionnels ont été conçus pour une époque plus simple, où une même équipe contrôlait la majeure partie du code et des données. Les réseaux industriels d’aujourd’hui sont très différents : des dispositifs de nombreux fournisseurs, respectant des protocoles de communication stricts, sont disséminés dans les usines, chez les fournisseurs d’énergie et chez les sous-traitants. Chaque organisation n’observe qu’une partie du trafic, et les lois ou contrats interdisent souvent de regrouper les journaux. Par conséquent, des suites de tests construites isolément peuvent manquer des combinaisons rares de messages qui n’apparaissent que lorsque des systèmes appartenant à différents acteurs interagissent. Les outils de protection de la vie privée existants, qui brouillent ou suppriment des champs sensibles, ne suffisent pas non plus : si vous « généralisez » trop les données de protocole, les messages cessent d’être valides et ne peuvent plus être utilisés pour des tests réalistes.
Un cadre collaboratif qui place la confidentialité au premier plan
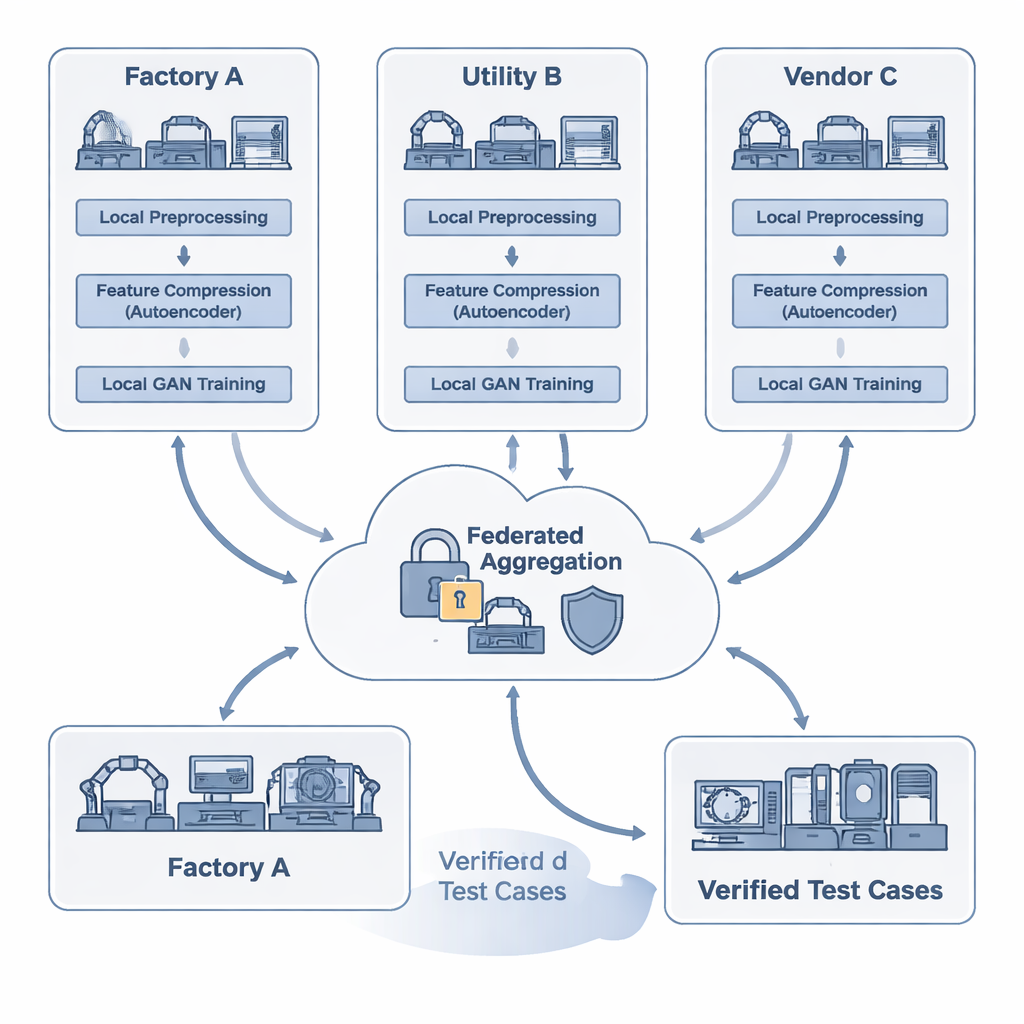
Les chercheurs proposent FAT-CG, un cadre qui permet à plusieurs parties d’entraîner conjointement un générateur de données de test tout en conservant la confidentialité de leurs traces de protocole détaillées. Au niveau local, chaque participant nettoie et anonymise ses données, puis les introduit dans un autoencodeur, un type de réseau neuronal qui compresse les messages en résumés numériques compacts. Ces résumés sont suffisamment riches pour préserver la grammaire et la structure des protocoles industriels, sans exposer les adresses brutes ou des valeurs propriétaires. Au lieu d’envoyer des journaux, les organisations ne partagent que des mises à jour de modèle chiffrées. Un coordinateur central utilise une cryptographie spéciale (chiffrement homomorphe) et du bruit soigneusement ajouté (confidentialité différentielle) pour combiner ces mises à jour en un modèle partagé plus robuste, sans pouvoir reconstruire le trafic originel de chaque participant.
Apprendre aux machines à générer des cas de test puissants
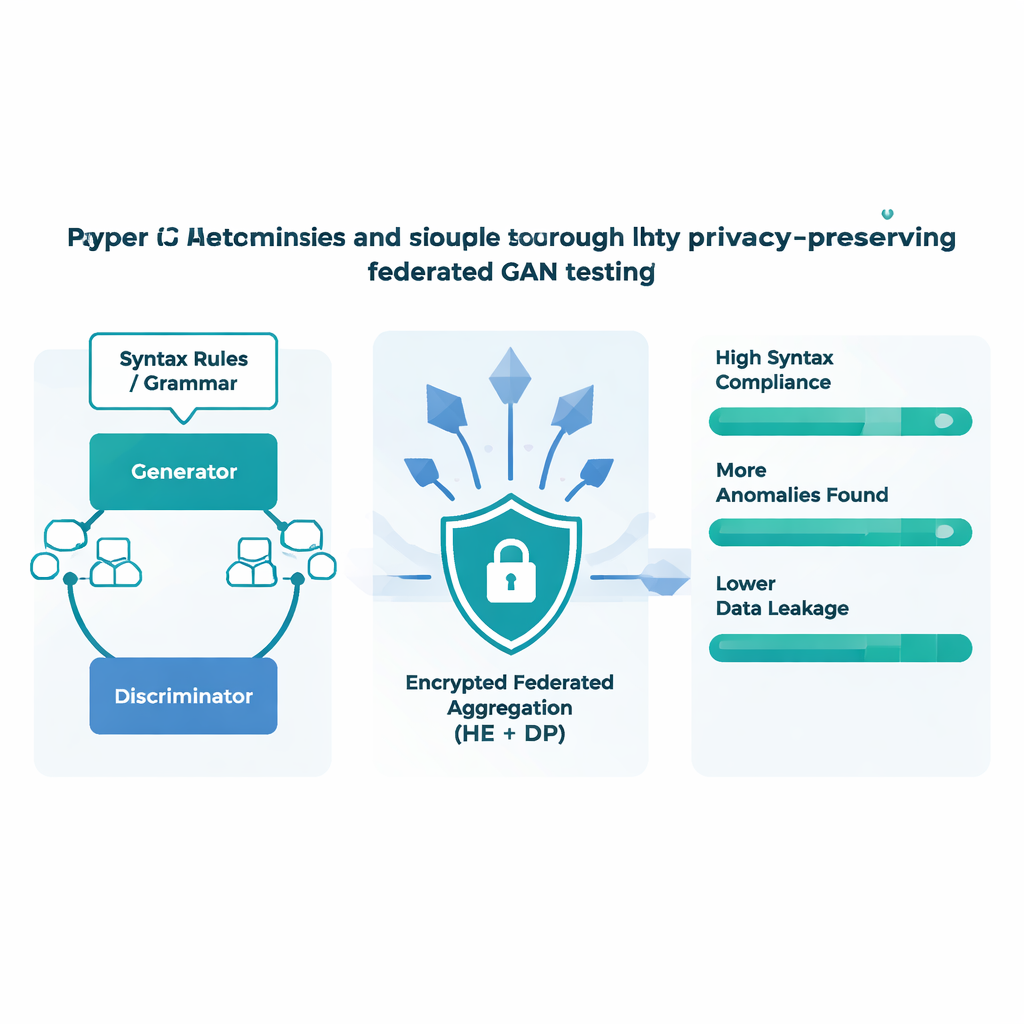
Au cœur de FAT-CG se trouve un réseau antagoniste génératif (GAN), composé de deux réseaux neuronaux en compétition. L’un, le générateur, tente de produire de nouveaux messages de protocole ; l’autre, le discriminateur, tente de distinguer les messages réels des faux. Au fil du temps, ce duel pousse le générateur à apprendre des motifs subtils dans la structure des messages valides. FAT-CG ajoute une autre dimension : des descriptions formelles des règles de protocole sont utilisées pour vérifier chaque message généré, et les violations sont pénalisées pendant l’entraînement. Cela maintient le trafic synthétique à la fois réaliste et diversifié. Le système fonctionne en boucle : une fois les messages générés, ils sont envoyés à des dispositifs industriels simulés dans un bac à sable. Tous les cas qui provoquent des plantages, des fuites mémoire ou des réponses anormales sont réinjectés dans le processus d’entraînement, orientant le générateur vers les zones les plus prometteuses de l’espace de recherche.
Confidentialité, rapidité et détection de bogues dans des tests réels
L’équipe a testé FAT-CG sur plusieurs protocoles industriels courants, notamment Modbus-TCP et OPC UA, en utilisant une configuration réaliste avec plusieurs dispositifs en périphérie et un serveur central. Comparée aux outils de fuzzing existants et à des méthodes d’apprentissage fédéré plus simples, la nouvelle approche a produit des messages de test respectant les règles de protocole plus de 90 % du temps et a découvert près de trois fois plus d’anomalies pour mille tests. Parallèlement, ses défenses en couches ont fortement réduit le risque qu’un attaquant puisse reconstruire les données d’entraînement à partir des mises à jour de modèle partagées. En compressant les caractéristiques de protocole en codes petits et structurés avant chiffrement, le système a aussi réduit le volume de communication d’environ un facteur trente, raccourcissant les tours d’entraînement et le rendant pratique pour des réseaux industriels à bande passante limitée.
Ce que cela signifie pour les systèmes critiques
Concrètement, ce travail montre que les entreprises exploitant des infrastructures critiques n’ont pas à choisir entre préserver la confidentialité de leurs données et tester leurs systèmes de manière approfondie. FAT-CG offre un moyen pour de nombreux acteurs de mutualiser leurs connaissances sur le comportement des réseaux réels, sans jamais remettre des journaux sensibles. Le résultat est un générateur de tests partagé, meilleur pour « parler » le langage des dispositifs industriels et plus à même de provoquer des cas limites dangereux — précisément l’outil nécessaire pour détecter des vulnérabilités avant qu’elles ne provoquent des pannes ou des accidents. Bien que l’étude se concentre sur les protocoles industriels, les mêmes idées pourraient s’appliquer à d’autres domaines sensibles, comme la santé ou la finance, où les organisations doivent collaborer sur la sûreté et la fiabilité sans sacrifier la confidentialité.
Citation: Wang, Z., Zhao, L., Meng, F. et al. Secure multi-party test case data generation through generative adversarial networks. Sci Rep 16, 5085 (2026). https://doi.org/10.1038/s41598-026-35773-2
Mots-clés: test de logiciels industriels, apprentissage fédéré, réseaux antagonistes génératifs, IA respectueuse de la vie privée, fuzzing de protocoles réseau