Clear Sky Science · fr
Sentinelle acoustique : classification hiérarchique des sons de pas utilisant des représentations acoustiques fines et grossières pour la surveillance tactique
À l'écoute des pas dissimulés
Imaginez détecter des personnes se déplaçant dans une forêt sombre ou le long d'une frontière isolée sans une seule caméra en vue — simplement en écoutant leurs pas. Cette étude explore comment les sons subtils produits par la marche peuvent être transformés en un outil d'alerte précoce puissant pour les soldats, la police et les enquêteurs, en particulier dans des lieux où les caméras échouent ou l'alimentation électrique est limitée.
Pourquoi les caméras ne suffisent pas
La sécurité moderne repose souvent sur la vidéosurveillance, mais les caméras présentent des faiblesses évidentes : elles nécessitent une ligne de vue directe, consomment beaucoup d'énergie et peuvent être difficiles à déployer rapidement en terrain accidenté ou hostile. Les points de contrôle mobiles, les patrouilles frontalières et les équipes de lutte contre le terrorisme peuvent opérer de nuit, sous un couvert végétal dense ou en zone montagneuse où installer et maintenir un réseau de caméras est peu pratique. Dans ces situations, le son devient une alternative séduisante. Les microphones sont légers, moins gourmands en énergie et peuvent « entendre autour des obstacles », repérant des personnes avant qu'elles ne deviennent visibles. Les pas, bien que relativement discrets, se détachent dans de nombreux contextes tactiques où le bruit de fond est faible, ce qui en fait un signal prometteur pour l'alerte précoce et la reconstitution médico-légale des événements.
Constituer une bibliothèque de pas en conditions réelles
Pour transformer cette idée en système opérationnel, les chercheurs ont d'abord dû résoudre un problème élémentaire : il n'existait pas de collection adéquate d'enregistrements de pas en conditions réelles. Les bases de sons existantes incluent quelques pas destinés principalement à la reconnaissance sonore générique ou à l'identification, souvent enregistrés en laboratoire dans des conditions contrôlées. Elles n'indiquent généralement pas si le son provient d'une forêt, d'une route ou d'un intérieur, ni s'il a été produit par une seule personne ou plusieurs. L'équipe a donc créé une nouvelle ressource appelée jeu de données EWFootstep 1.0. Il contient 1 650 extraits audio provenant de 176 volontaires marchant naturellement à travers des forêts, des routes et des espaces intérieurs dans trois régions différentes de l'Inde. Les enregistrements couvrent un mélange de chaussures à semelles souples et rigides, différents terrains et des conditions de terrain réalistes comme un placement de microphone irrégulier. Chaque extrait comprend au moins 15 pas et est étiqueté à la fois par type d'environnement et par la présence d'une personne seule ou d'un groupe.
Apprendre à une machine à entendre comme un éclaireur
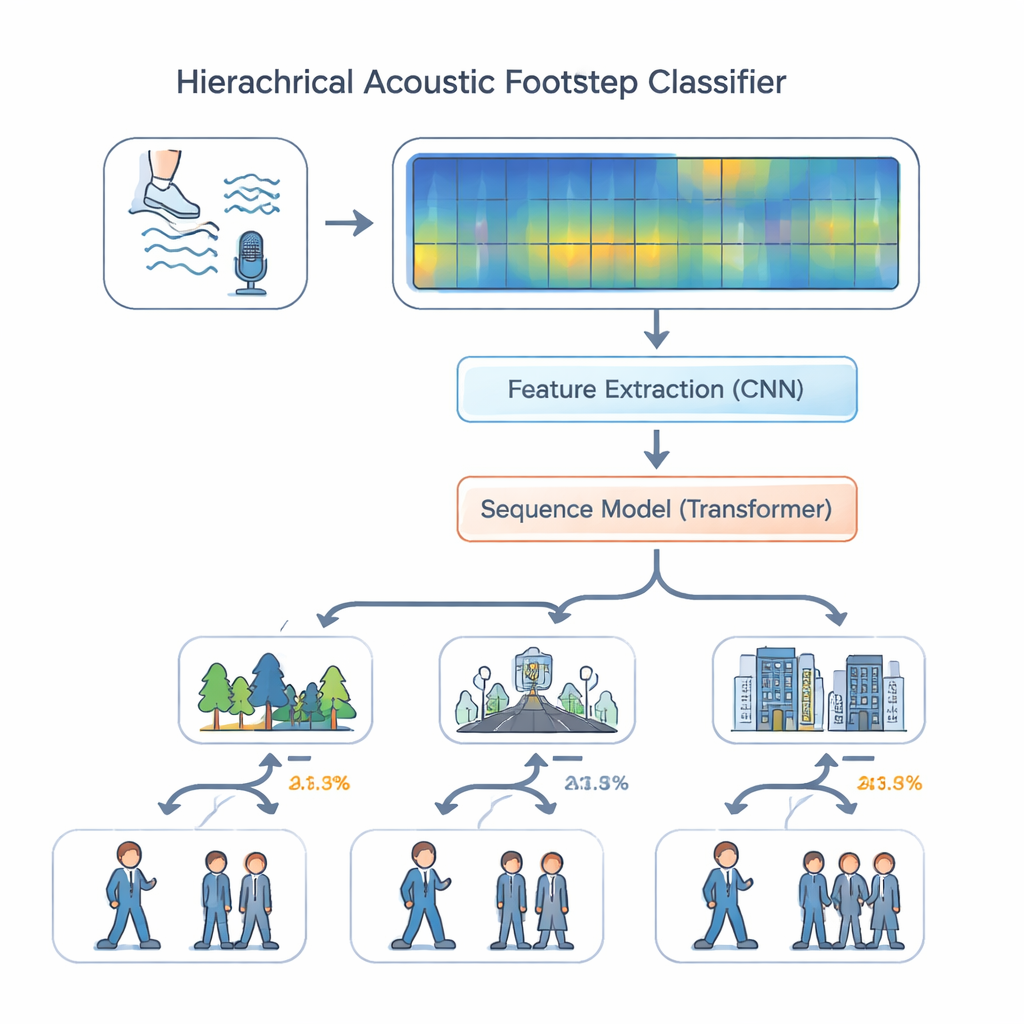
Avec ce jeu de données, les auteurs ont conçu un système d'écoute qui imite la manière dont un éclaireur expérimenté pourrait raisonner à partir du son. Plutôt que de traiter toutes les tâches de la même façon, leur modèle « hiérarchique multi‑tâches » décide d'abord où le son se produit — forêt, route ou intérieur — puis, en utilisant ce contexte, estime s'il s'agit d'une seule personne ou de plusieurs. L'audio est converti en spectrogrammes colorés qui montrent comment l'énergie se répartit en fréquence au fil du temps. Une série de couches convolutionnelles extrait des détails fins liés aux surfaces et aux chaussures, comme le craquement des feuilles ou le bruit sourd de bottes sur le béton. Ces caractéristiques sont ensuite transmises à un module transformeur, un moteur moderne de traitement de séquences qui examine des motifs sur de nombreuses étapes — rythme, espacement et impacts répétés — plutôt que des sons isolés. Un encodage positionnel aide le modèle à garder la notion d'ordre dans le temps, essentielle pour reconnaître des schémas de marche.
Quelle est l'efficacité de la sentinelle acoustique ?
Les chercheurs ont comparé leur modèle hiérarchique à des approches plus simples, telles qu'un classifieur tout‑en‑un et un design multi‑tâches standard où l'environnement et l'effectif sont prédits indépendamment. Ils ont aussi testé des variantes supprimant des composants clés comme les couches convolutionnelles ou le transformeur. Dans l'ensemble, la conception complète avec les deux modules et l'encodage positionnel a obtenu les meilleures performances. Sur le jeu de données EWFootstep 1.0, il a identifié correctement l'environnement dans environ 96 % des cas et le nombre de personnes avec une précision similaire — nettement mieux que des auditeurs humains entraînés, qui ont accusé un retard de 25 à 30 points de pourcentage. Des expériences supplémentaires sur un jeu de données de toux ont montré que la même architecture se généralise bien au‑delà des pas, suggérant qu'elle peut traiter des types d'audio très différents du quotidien.
Du champ de bataille à la scène de crime
Pour les non‑spécialistes, l'idée principale est que des sons faibles et quotidiens comme les pas contiennent bien plus d'informations qu'on ne le croit habituellement. En combinant de larges jeux de données réalistes avec des outils avancés de reconnaissance de motifs, les auteurs montrent qu'un système compact peut, en quasi temps réel et sans caméras, indiquer de quel type de lieu il provient et combien de personnes s'y trouvent. Cette « sentinelle acoustique » pourrait aider à protéger des patrouilles et des installations isolées, et sa capacité à disséquer des motifs sonores subtils pourrait aussi servir la criminalistique audio, par exemple pour reconstituer des déplacements sur une scène de crime lorsque la vidéo est indisponible ou peu fiable.
Citation: Agrahri, A., Maurya, C.K., Tiwari, R.S. et al. Acoustic sentinel: hierarchical classification of footstep sound using fine and coarse-grain acoustic feature representations for tactical surveillance. Sci Rep 16, 5635 (2026). https://doi.org/10.1038/s41598-026-35756-3
Mots-clés: surveillance acoustique, détection de pas, systèmes d'alerte précoce, deep learning audio, sécurité tactique