Clear Sky Science · fr
Apprentissage automatique pour l’estimation rapide de l’intensité macrosismique à partir de données sismométriques en Italie
Pourquoi des évaluations rapides des séismes sont importantes
Lorsque le sol commence à trembler, les équipes d’urgence ont seulement quelques minutes pour décider où envoyer les sauveteurs et les ressources. Pourtant, la façon habituelle de décrire la perception d’un séisme en surface — l’intensité macrosismique, comme l’échelle Mercalli utilisée en Italie — n’arrive souvent que des heures, des jours, voire des mois plus tard, après que des personnes ont rempli des questionnaires et que des experts ont inspecté les dégâts. Cet article examine comment l’apprentissage automatique moderne peut transformer les premières mesures d’un sismomètre en cartes rapides et raisonnablement précises de la perception du séisme, aidant les autorités à réagir plus vite et avec plus de confiance.
Des rapports ressentis aux estimations rapides
Les estimations d’intensité traditionnelles en Italie s’appuient sur deux flux de données principaux. Le premier consiste en des enquêtes de terrain réalisées par des experts et consignées dans une base de données officielle, qui portent sur les lieux endommagés mais nécessitent du temps pour être organisées. L’autre provient du système en ligne « Hai Sentito Il Terremoto », où les citoyens rapportent ce qu’ils ont ressenti et vu, fournissant de nombreuses observations de faible et moyenne intensité. Les deux sources mesurent l’intensité sur l’échelle Mercalli–Cancani–Sieberg, qui classe les secousses de très faibles à destructrices en fonction des réactions humaines et des bâtiments. Pour relier ces mesures centrées sur l’humain aux enregistrements instrumentaux, les auteurs ont fusionné les deux jeux de données autour de chaque station sismique, en moyennant toutes les intensités rapportées dans un rayon de 5 km pour obtenir une valeur représentative unique pour cette zone et en l’arrondissant à une classe entière de 1 à 8.
Apprendre à une forêt de modèles à lire les secousses
Les chercheurs ont posé l’estimation d’intensité comme un problème de classification : étant données les premières mesures, prédire laquelle des huit classes d’intensité s’appliquera aux environs de chaque station. Ils ont utilisé une Forêt Aléatoire, un ensemble de nombreux arbres de décision qui effectuent chacun une série simple de séparations « si–alors » sur les données, comme des combinaisons de magnitude, profondeur, distance à la source et mesures directes du mouvement du sol telles que l’accélération, la vitesse et le déplacement maximaux. Entraîné sur 5 466 observations issues de 523 séismes à travers l’Italie (2008–2020), le modèle a appris des liens complexes et non linéaires entre ce que les sismomètres enregistrent et ce que les gens rapportent. Pour gérer le fait que les secousses fortes sont plus rares dans les données, les auteurs ont ajusté l’entraînement pour que tous les niveaux d’intensité comptent de façon égale, empêchant le modèle de se concentrer uniquement sur les événements plus fréquents et plus faibles.
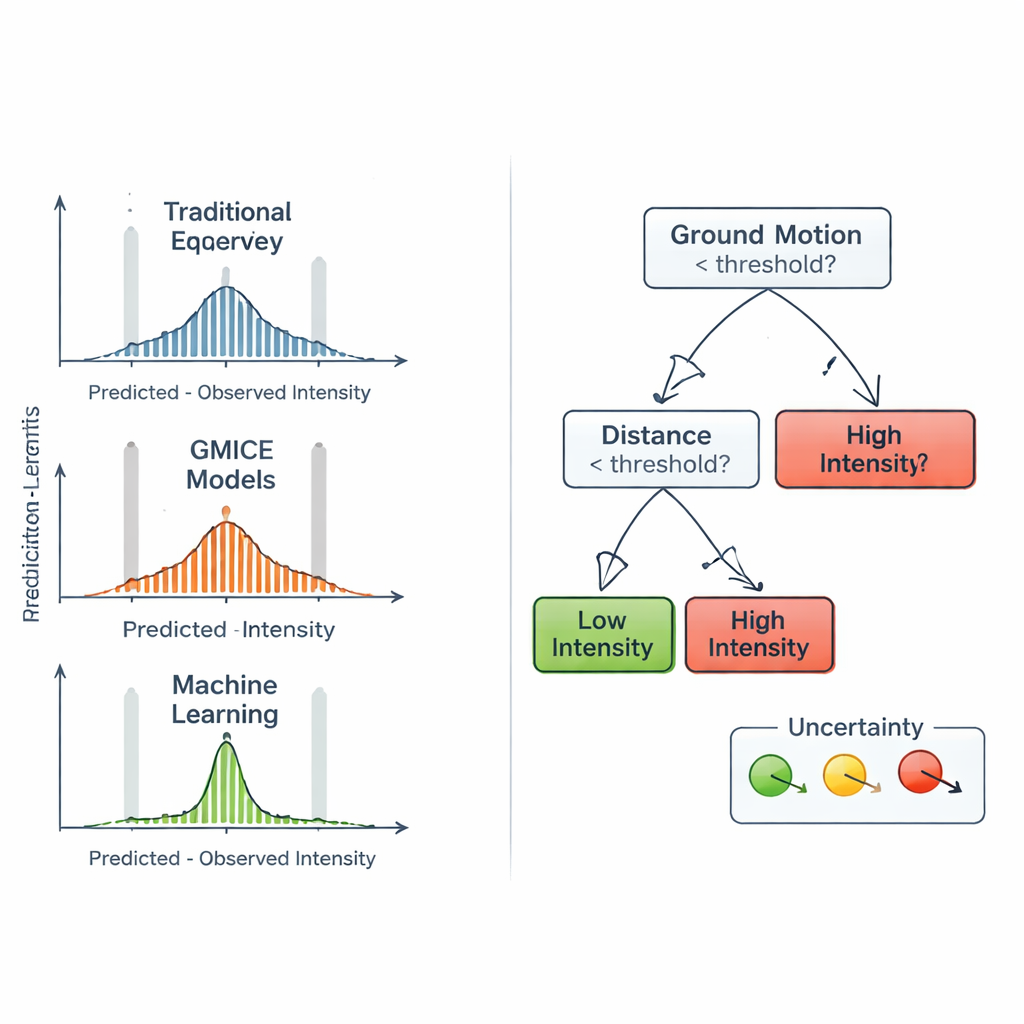
Vérification par rapport aux relations établies
Pour évaluer si l’approche par apprentissage automatique apporte réellement une plus-value, l’équipe a comparé ses prédictions à deux familles largement utilisées de relations empiriques. La première, appelées équations de prédiction d’intensité (IPE), estime l’intensité principalement à partir de la magnitude, de la profondeur et de la distance du séisme, en supposant que l’amplitude des secousses décroît de manière régulière avec la distance. La seconde, équations de conversion du mouvement du sol en intensité (GMICE), transforme les mesures instrumentales d’amplitude maximale en classes d’intensité attendues. Ces formules sont compactes et faciles à appliquer, mais elles ne peuvent pas entièrement rendre compte de l’influence de la géologie locale, du parc de construction ou de la direction des ondes sur la secousse ressentie. En revanche, la Forêt Aléatoire intègre naturellement à la fois les paramètres de source et les mesures du mouvement du sol, et peut s’adapter aux motifs subtils présents dans le jeu de données italien sans préscrire une forme mathématique rigide.
Regarder à l’intérieur de la boîte noire et ses limites
Parce que les responsables des urgences ont besoin de comprendre la base des décisions automatisées, les auteurs ont construit des arbres de décision « relais » plus simples qui imitent le comportement de la Forêt Aléatoire. Ces arbres réduits peuvent être représentés sous forme de diagrammes, montrant quels seuils de mouvement du sol distinguent faibles et fortes intensités et où des variables comme l’accélération et la vitesse prédominent. Cette analyse a révélé que les mesures directes du mouvement du sol, en particulier l’accélération et la vitesse maximales, ont plus de poids que la magnitude ou la profondeur seules. Les auteurs ont aussi introduit un moyen simple de signaler l’incertitude de chaque prédiction d’arbre relais, en utilisant des mesures de mélange des exemples d’entraînement dans chaque branche terminale. Ils ont en même temps constaté que les intensités très fortes restent difficiles à prédire, en partie parce qu’elles sont naturellement rares dans les archives historiques, ce qui conduit parfois à sous-estimer les niveaux de secousse les plus élevés.
Test en conditions réelles lors d’un séisme récent en Italie
L’équipe a évalué son cadre sur un événement notable : un séisme de magnitude 5,5 au large de la côte adriatique près de Pesaro-Urbino en 2022. Environ 15 minutes après, les sismologues disposaient des informations nécessaires sur la source et le mouvement du sol, mais seulement une centaine de rapports publics d’intensité avaient été déposés, donnant une image très parcellaire. En n’utilisant que les données instrumentales, la Forêt Aléatoire et son arbre relais ont généré des estimations d’intensité détaillées autour de centaines de stations en moins de deux secondes sur un ordinateur standard. Comparées ensuite à la carte beaucoup plus dense construite à partir de plus de 12 000 rapports citoyens collectés sur plusieurs jours, les cartes issues de l’apprentissage automatique ont bien capturé à la fois l’étendue générale des ressentis et la répartition des secousses modérées, et ont égalé ou surpassé les formules classiques.
Ce que cela signifie pour les populations exposées aux séismes
Globalement, l’étude montre qu’un système d’apprentissage automatique soigneusement entraîné peut prendre les premières minutes de données sismométriques et produire des cartes rapides et raisonnablement transparentes de l’impact d’un séisme. Ces cartes ne remplacent pas les enquêtes détaillées ni les rapports participatifs, mais elles peuvent combler l’écart précoce et dangereux durant lequel les autorités doivent décider où envoyer ambulances, pompiers et inspecteurs structurels avec des informations très limitées. En combinant des algorithmes avancés avec des modèles simplifiés interprétables et des indicateurs d’incertitude basiques, le cadre propose une étape pratique vers une réponse aux séismes plus rapide et mieux informée en Italie et pourrait être adapté à d’autres régions confrontées à des risques sismiques similaires.
Citation: Patelli, L., Cameletti, M., De Rubeis, V. et al. Machine learning for prompt estimation of macroseismic intensity from seismometric data in Italy. Sci Rep 16, 7265 (2026). https://doi.org/10.1038/s41598-026-35740-x
Mots-clés: intensité du tremblement de terre, apprentissage automatique, forêt aléatoire, hazard sismique, Italie