Clear Sky Science · fr
Réseau de fusion par renforcement multi-caractéristiques pour la segmentation sémantique d’images de télédétection
Des cartes plus nettes vues du ciel
Chaque jour, des satellites et des drones capturent des images détaillées de nos villes et de nos terres agricoles. Transformer ces images brutes en cartes nettes, pixel par pixel, des routes, toitures, arbres et cultures est essentiel pour des tâches telles que le suivi de la santé des cultures ou la planification de nouveaux quartiers. Cet article présente une nouvelle manière de rendre ces cartes plus précises, en particulier le long des frontières difficiles où bâtiments, champs et végétation se confondent.
Pourquoi lire les images aériennes est difficile
Les images de télédétection diffèrent des photos du quotidien. Elles sont prises depuis de haut, souvent sous des angles prononcés et avec des conditions d’éclairage changeantes. Différents objets peuvent apparaître très semblables depuis les airs : un parking en béton et un toit plat peuvent partager presque la même couleur ; différentes cultures peuvent afficher des motifs déroutants proches les uns des autres. Parallèlement, un même type d’objet peut paraître très différent selon les ombres, l’humidité ou les réglages de l’appareil. Les méthodes traditionnelles, et même beaucoup de systèmes modernes d’apprentissage profond, peinent à conserver des contours nets dans ces conditions. Elles ont souvent tendance à estomper les limites entre catégories ou à manquer de petits détails comme des voitures garées ou des canaux d’irrigation étroits.
Voir à la fois la vue d’ensemble et les lignes fines
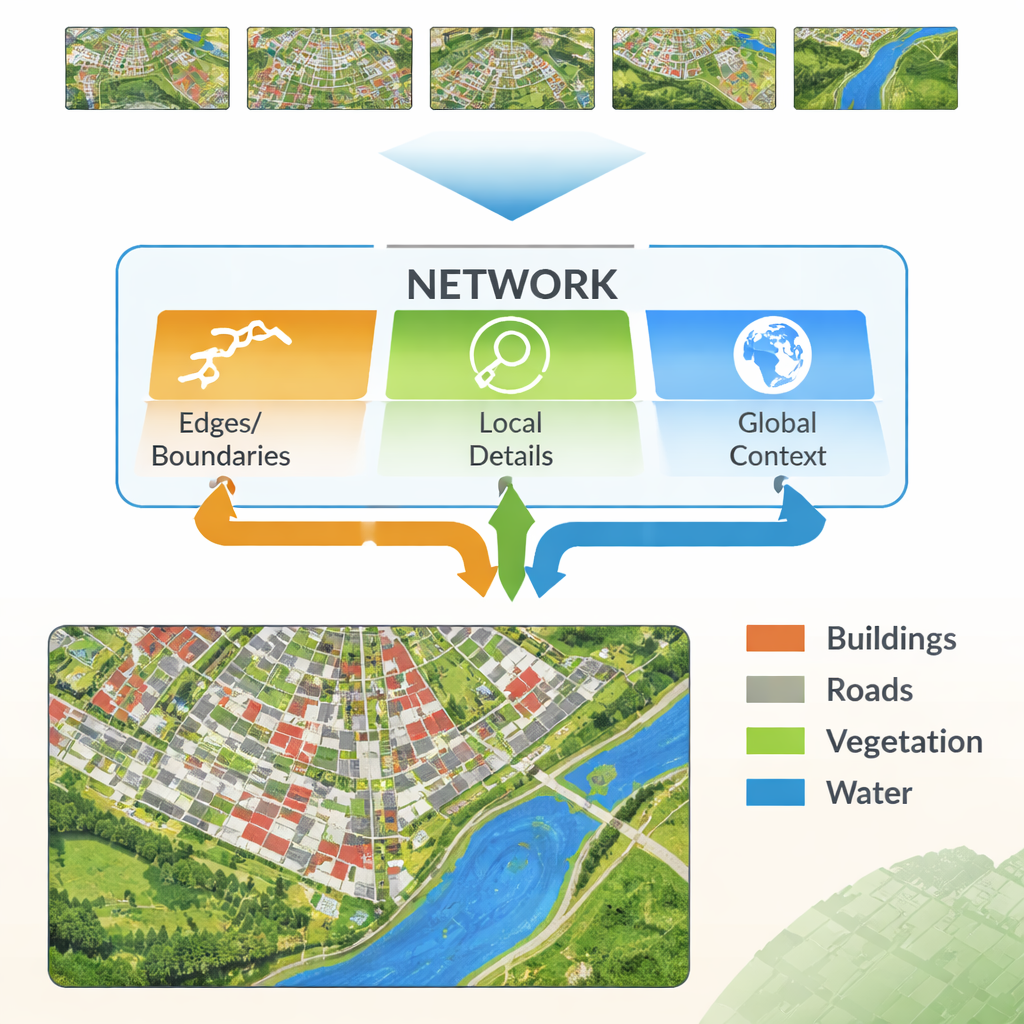
Les réseaux neuronaux modernes apprennent en faisant passer une image à travers de nombreuses couches. Les premières couches captent des détails fins comme les lignes et les textures, tandis que les couches profondes apprennent des motifs larges tels que « cette région est probablement des bâtiments ». Le défi est que combiner ces deux types d’informations n’est pas simple. Les détails de bas niveau peuvent être bruités et redondants, et les motifs de haut niveau peuvent effacer les bords, produisant des contours flous. Les auteurs proposent une nouvelle architecture, nommée Multi‑Feature Enhancement Fusion Network (MFEF‑UNet), conçue explicitement pour équilibrer détail local et compréhension globale. Elle traite les contours, les motifs locaux et le contexte large comme des sources d’information distinctes mais coopérantes.
Mettre en valeur les contours et fusionner les caractéristiques
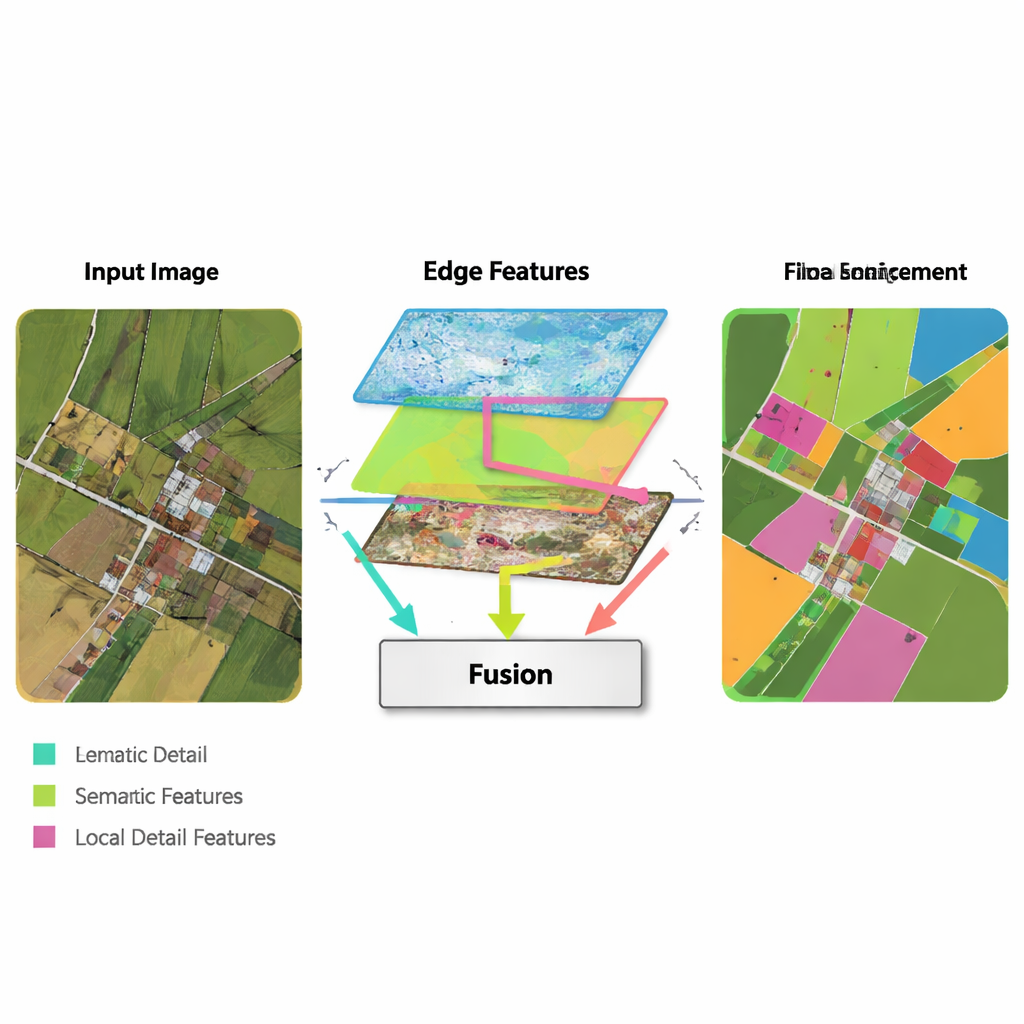
Une idée clé de la nouvelle méthode est d’emprunter des outils simples et classiques de détection de contours et de les intégrer dans une chaîne moderne d’apprentissage profond. Un module d’amélioration des contours récupère les premières caractéristiques issues du réseau et les passe à travers des opérateurs très efficaces pour repérer les frontières — à la manière des fonctions de détection de contours basiques des logiciels d’édition d’images. Ces cartes de contours renforcées sont produites à plusieurs échelles, de sorte que le réseau voit à la fois les frontières fines et grossières. Un module de fusion multi‑caractéristiques rassemble ensuite trois flux : l’information sémantique évolutive de haut niveau (« qu’est‑ce que cette région ? »), la reconstruction des détails par le décodeur, et les cartes de contours. Plutôt que de les empiler, le module utilise un mécanisme de type attention pour que les caractéristiques sémantiques puissent « interroger » les flux de contours et de détails afin de localiser les frontières et les structures fines, puis ajuster la représentation finale en conséquence.
Équilibrer détail local et contexte global
Un autre ingrédient du MFEF‑UNet est un module d’amélioration des caractéristiques local‑global. Pour un non‑spécialiste, on peut le voir comme la partie du réseau qui veille à ne pas perdre de vue la forêt en se concentrant sur les arbres — ou la ville en raffinant chaque bâtiment. L’image est découpée en sous‑fenêtres gérables pour que des pixels voisins puissent être modélisés ensemble, préservant formes et textures. Après cette modélisation locale, les fenêtres sont recousues pour reformer l’image complète, et un second passage permet à l’information de circuler entre régions éloignées. Ce processus en deux étapes aide le modèle à respecter à la fois les petites structures, comme les voitures et les limites étroites de parcelles, et les motifs à grande échelle, comme des îlots d’habitation ou des masses d’eau continues.
Valider la méthode sur villes et campagnes
Les chercheurs ont testé leur approche sur trois jeux de données publics : deux couvrant des villes et bourgs européens, et un grand ensemble d’images agricoles des États‑Unis. Ces ensembles contiennent un mélange de toitures, routes, végétation, plans d’eau et motifs subtils de cultures. Sur les trois benchmarks, le MFEF‑UNet a produit de manière constante des cartes plus précises que plusieurs méthodes de pointe, incluant des réseaux convolutionnels classiques, des architectures basées sur les Transformers et des modèles plus récents de type « state‑space ». Ses avantages étaient les plus visibles autour des contours complexes de bâtiments, des amas de petits objets comme des véhicules, et des structures longues et fines telles que canaux de drainage ou rangs de culture — endroits où d’autres méthodes ont tendance à fragmenter ou à flouter la segmentation.
Qu’est‑ce que cela signifie en pratique
En pratique, le réseau proposé transforme les images aériennes en cartes d’occupation des sols plus propres et plus fiables. Les urbanistes peuvent mesurer avec plus de confiance les surfaces bâties, les ingénieurs peuvent mieux tracer routes et toits, et les agronomes peuvent délimiter plus précisément parcelles, voies d’eau et zones de stress des cultures. Bien que les composants supplémentaires dédiés aux contours et à la fusion ajoutent un certain coût de calcul, la conception globale reste raisonnablement efficace tout en apportant des gains clairs en précision et robustesse. Pour les non‑spécialistes, la conclusion est que, en mettant délibérément l’accent sur les contours et en fusionnant soigneusement différents indices visuels, les ordinateurs peuvent désormais lire l’imagerie satellite et drone avec un œil plus acéré — nous rapprochant de cartes mondiales à jour et de haute précision.
Citation: Zhang, W., Yang, W., Yin, Y. et al. Multi-feature enhancement fusion network for remote sensing image semantic segmentation. Sci Rep 16, 5023 (2026). https://doi.org/10.1038/s41598-026-35723-y
Mots-clés: télédétection, segmentation sémantique, imagerie satellite, apprentissage profond, cartographie de l’occupation des sols