Clear Sky Science · fr
Suiveur siamois à double branche augmenté par transformeur avec régression consciente de la confiance et mise à jour adaptative du modèle
Apprendre aux ordinateurs à suivre un seul objet dans une scène encombrée
Des voitures autonomes aux caméras de sécurité domestique en passant par les drones, de nombreux dispositifs modernes doivent suivre un seul objet en mouvement dans un monde occupé et changeant. Cette tâche, appelée suivi d'objet visuel, paraît simple pour les humains mais s'avère étonnamment difficile pour les machines : des personnes passent devant la caméra, l'éclairage varie, l'objet rétrécit au loin ou est brièvement masqué. Cet article présente TSDTrack, un nouveau système de suivi qui exploite les avancées récentes en apprentissage profond et en transformeurs pour rester verrouillé sur une cible de façon plus fiable dans ces conditions réalistes.
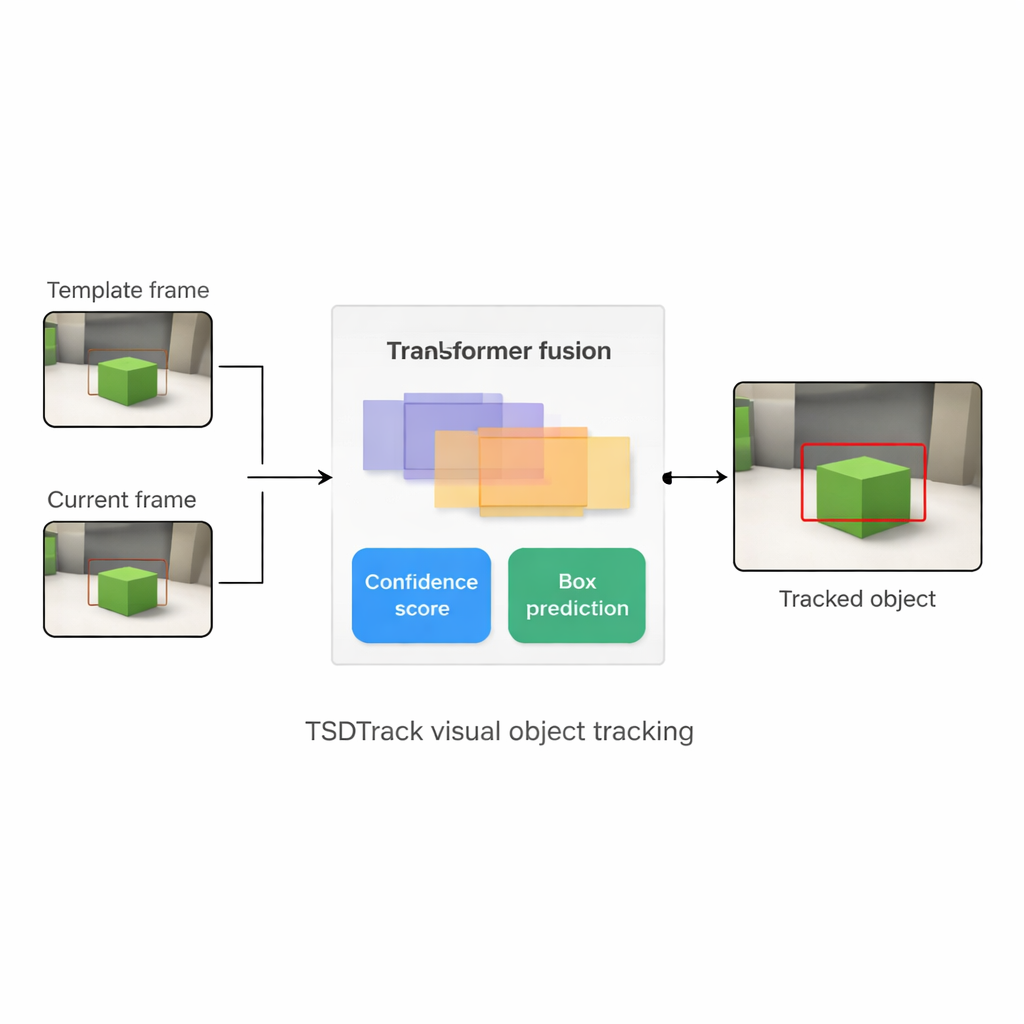
Pourquoi suivre un seul objet est si difficile
Un suiveur voit généralement l'objet clairement seulement dans la première image d'une vidéo, puis doit continuer à le localiser au fur et à mesure que la scène change. Les méthodes traditionnelles s'appuyaient soit sur des descripteurs d'image conçus manuellement, soit sur un réseau neuronal comparant la première image (le « modèle ») avec chaque nouvelle image. Ces systèmes plus anciens présentaient trois faiblesses majeures. D'abord, ils conservaient généralement le modèle initial fixe ; si l'objet tournait, était partiellement couvert ou changeait de taille, le suiveur avait du mal. Ensuite, ils se concentraient souvent sur un seul niveau de détails de l'image, manquant la combinaison de contours fins et de contexte plus large qui aide les humains à reconnaître les choses. Enfin, ils ne savaient pas quand douter : ils produisaient un encadré autour de l'objet supposé sans indication claire de la fiabilité de cette estimation, ce qui les rendait sujets à dériver sur l'arrière-plan.
Fusionner le contexte global et les détails fins
TSDTrack répond à ces problèmes en combinant une architecture « siamoise » classique avec un transformeur, le même type de modèle basé sur l'attention qui a transformé les tâches de langage et de vision. Le système utilise un réseau profond pour extraire des caractéristiques de deux entrées : un petit patch définissant la cible et un patch plus large contenant la zone de recherche actuelle. Plutôt que de s'appuyer sur une seule échelle de caractéristiques, il puise des informations à partir de plusieurs couches du réseau, qui représentent des contours, des formes et des motifs au niveau des objets. Un module de fusion basé sur un transformeur apprend ensuite à mélanger ces couches afin que le suiveur comprenne à la fois où se trouvent les éléments dans l'image et comment ils se rapportent à la scène globale. Cela l'aide à distinguer la cible d'objets similaires et du désordre, même lorsque la vue est bruitée ou partiellement obstruée.
Savoir à quel point le suiveur est sûr
Le cœur de TSDTrack est une tête de prédiction à double branche qui divise la tâche en deux questions liées : « Où se trouve l'objet ? » et « Dans quelle mesure devons-nous faire confiance à cette réponse ? ». Une branche estime un score de confiance qui reflète non seulement la similarité visuelle avec la cible, mais aussi la qualité du recouvrement de la boîte prédite avec les régions susceptibles de contenir l'objet. L'autre branche considère les coordonnées de la boîte non pas comme une unique prédiction, mais comme une distribution de probabilité sur de nombreuses positions possibles, permettant au modèle de représenter l'incertitude. Lorsque l'image est nette, la distribution devient pointue et la boîte est précise ; lorsque l'objet est flou ou partiellement caché, la distribution s'étale. Cette vision probabiliste conduit à un positionnement de boîte plus lisse et plus stable comparé aux anciens suiveurs qui produisaient une seule prédiction rigide.
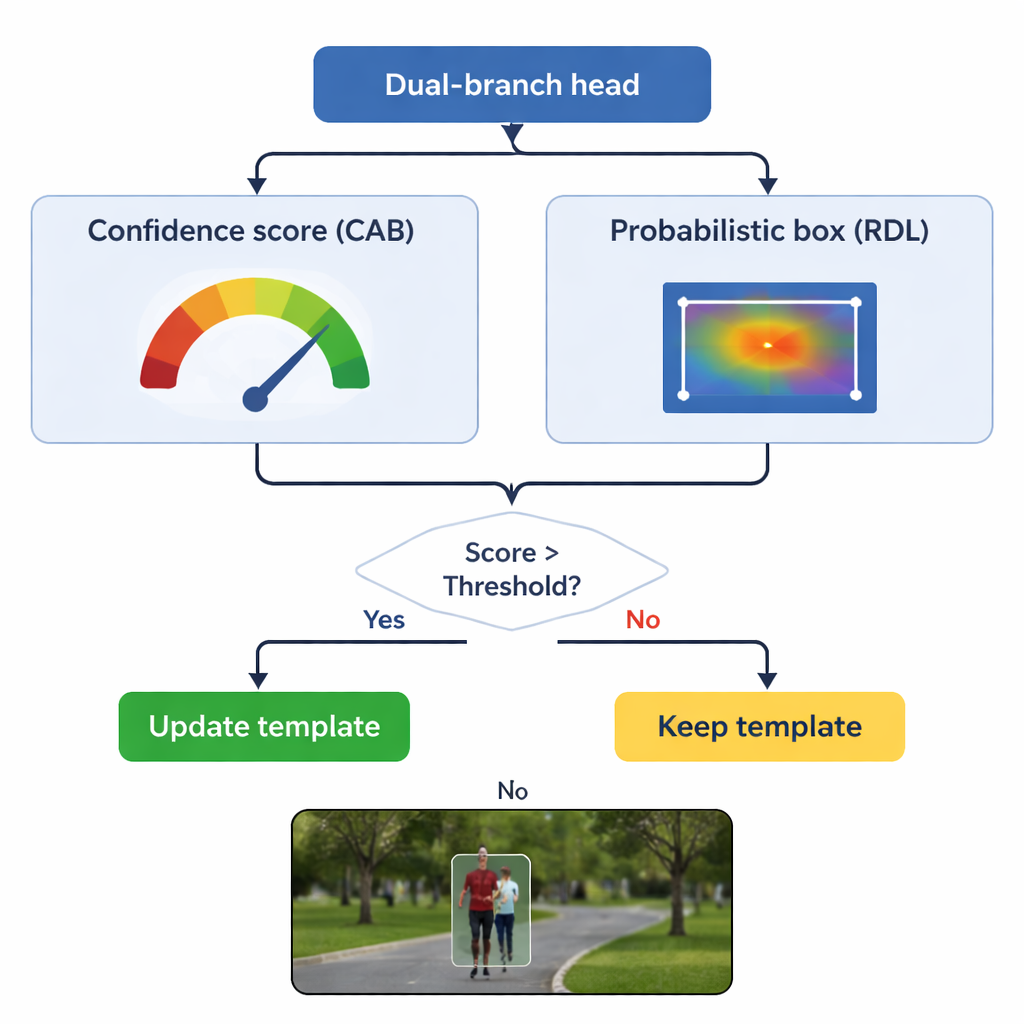
Mettre à jour la mémoire sans oublier l'original
Un danger clé dans le suivi est la « dérive du modèle » : si le modèle continue de mettre à jour sa représentation de l'objet à partir de images de mauvaise qualité, il peut apprendre progressivement l'arrière-plan. TSDTrack aborde cela en laissant sa branche de confiance jouer le rôle de gardien. Le système met à jour son modèle interne uniquement lorsque le score de confiance dépasse un seuil choisi, et même alors, il mélange les nouvelles informations en douceur avec la vue d'origine plutôt que de la remplacer complètement. Cette mise à jour sélective permet au suiveur de s'adapter aux véritables changements, comme une personne qui se retourne ou une voiture qui pivote, sans être trompé par des occlusions ou des distractions momentanées. Le modèle original est aussi conservé en réserve comme référence stable au cas où des mises à jour ultérieures s'avéreraient trompeuses.
Que signifient les résultats en pratique
Les auteurs ont testé TSDTrack sur plusieurs benchmarks de suivi largement utilisés, incluant des vidéos longues, des mouvements rapides, des prises de vue aériennes par drone et des scènes très encombrées. Dans ces tests, la nouvelle méthode a systématiquement surpassé de nombreux suiveurs de pointe à la fois en précision (distance entre la boîte et l'objet réel) et en robustesse (fréquence de perte totale de l'objet), tout en restant suffisamment rapide pour une utilisation en temps réel sur du matériel moderne. Pour un non-spécialiste, la conclusion est que TSDTrack peut garder son attention sur une cible choisie de façon plus fiable dans les conditions désordonnées des caméras réelles. En combinant un raisonnement multi-échelle par transformeur, une estimation de sa propre confiance et une mise à jour prudente du modèle, il offre un bloc de construction plus sûr pour des applications comme la conduite autonome, la surveillance intelligente et les robots intelligents.
Citation: Sachin Sakthi, K.S., Jeong, J.H. & Choi, W.Y. Transformer-augmented dual-branch siamese tracker with confidence-aware regression and adaptive template updating. Sci Rep 16, 5170 (2026). https://doi.org/10.1038/s41598-026-35692-2
Mots-clés: suivi d'objet visuel, suivi basé sur transformeur, réseaux siamois, vision par ordinateur, systèmes autonomes