Clear Sky Science · fr
Une approche par apprentissage automatique basée sur satellite pour estimer la température moyenne quotidienne de l’air à haute résolution dans une mégapole au Brésil
Pourquoi la chaleur en ville n’est pas la même partout
Lors d’une journée chaude dans une grande ville, la température que vous ressentez dans une rue bordée d’arbres peut être très différente de celle vécue sur une place en béton à quelques rues de là. Pourtant, la plupart des études sur la santé et le climat considèrent encore une ville entière comme si elle avait une température unique. Cet article montre comment des scientifiques ont utilisé des satellites, des modèles météorologiques et l’apprentissage automatique pour cartographier quotidiennement les températures à São Paulo, au Brésil, avec un grand niveau de détail — révélant qui est réellement exposé à des températures dangereuses et où les actions de refroidissement sont le plus nécessaires.
Prendre la température de la ville en haute définition
Les relevés de température traditionnels reposent sur un nombre limité de stations météorologiques, souvent regroupées près des aéroports ou dans des quartiers plus aisés. Cela rend difficile la compréhension de la distribution de la chaleur dans les vrais quartiers, en particulier dans les grandes villes et dans les pays à revenu faible ou intermédiaire, où les réseaux de surveillance sont peu denses. Les chercheurs se sont concentrés sur São Paulo, une mégapole vaste et très hétérogène de plus de 22 millions d’habitants. Leur objectif était d’estimer la température moyenne quotidienne de l’air pour chaque carré de 500 par 500 mètres sur l’ensemble de l’aire métropolitaine pendant cinq ans, de 2015 à 2019, créant ainsi l’un des jeux de données les plus détaillés de températures urbaines disponibles en Amérique du Sud.
Mêler satellites, modèles météo et capteurs au sol
Pour construire cette image à haute résolution, l’équipe a combiné plusieurs types de données librement disponibles. Ils ont rassemblé des mesures de 48 stations au sol, qui fournissent les lectures les plus directes de la température de l’air mais seulement en des points spécifiques. Ils ont ensuite intégré des observations satellitaires de la température de surface terrestre, de l’angle solaire et de la réflectivité du sol, ainsi que des informations sur l’humidité, le vent et la pression provenant d’un produit mondial de « réanalyse » météorologique qui reconstruit l’état horaire du temps sur une grille grossière. Ces éléments ont été rééchantillonnés pour correspondre à la grille de 500 mètres et nettoyés pour combler les lacunes dues aux nuages ou aux passages satellitaires manquants. Au total, ils ont testé 23 variables candidates susceptibles d’aider à expliquer la variabilité de la chaleur dans l’espace et le temps.
Entraîner une machine à apprendre à lire la chaleur
Plutôt que d’utiliser une simple équation linéaire, les scientifiques ont opté pour une forêt aléatoire (Random Forest), une méthode d’apprentissage automatique populaire qui construit de nombreux arbres de décision et en moyenne les résultats. Cette approche est bien adaptée pour découvrir des relations complexes et non linéaires, par exemple la façon dont la température réagit différemment à la chaleur de surface, à l’humidité et au vent selon les parties de la ville ou les périodes de l’année. Pour éviter le surapprentissage lié aux particularités de quelques stations, ils ont utilisé un processus de sélection de variables étape par étape qui conserve uniquement les variables améliorant réellement les prédictions, et ils ont validé le modèle de deux façons : en excluant à plusieurs reprises des groupes de stations pendant l’entraînement, et en réservant cinq stations entières comme test externe strict pour évaluer la performance du modèle dans de nouveaux emplacements.
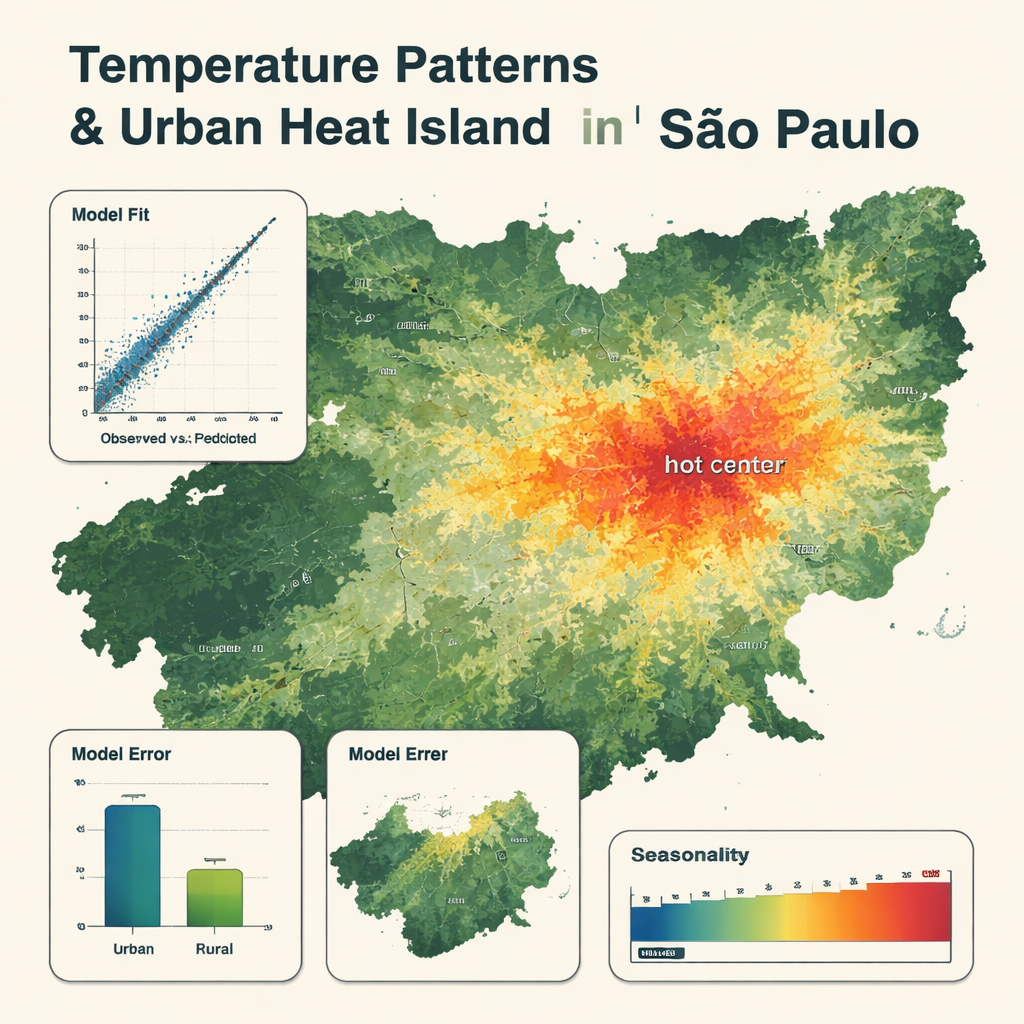
Ce que révèlent les cartes détaillées
Le modèle final n’a retenu que huit variables clés, dominées par la température de l’air issue du produit météorologique mondial, la température de surface satellitaire et l’humidité jouant aussi des rôles importants. Il a reproduit fidèlement les mesures des stations, avec une erreur moyenne d’environ 0,8 °C et une forte correspondance entre températures observées et prédites. Les cartes montrent des motifs clairs : des zones plus fraîches au-dessus des forêts, des montagnes et des grands réservoirs, et des zones plus chaudes dans le centre urbain dense, où les températures peuvent être jusqu’à 5 °C plus élevées que dans les zones rurales voisines. Le modèle a capté les variations saisonnières, avec les conditions les plus chaudes de décembre à mars et les plus fraîches de mai à août. Il était un peu moins précis en zones rurales et avait tendance à lisser les jours les plus extrêmes — très chauds ou très froids — mais il a néanmoins surpassé un modèle de régression multi‑linéaire plus traditionnel utilisant les mêmes entrées.
Pourquoi ces cartes importent pour la santé des populations
En transformant des mesures éparses et des clichés satellitaires en estimations quotidiennes de température à l’échelle de la rue, ce travail offre un outil puissant pour la santé publique et l’aménagement urbain à São Paulo et ailleurs. Les chercheurs peuvent désormais étudier comment la chaleur affecte différents quartiers, y compris les établissements informels souvent absents des registres officiels, et identifier où les habitants sont les plus à risque lors des vagues de chaleur. Parce que la méthode repose entièrement sur des données ouvertes et des logiciels standards, elle peut être adaptée à d’autres villes disposant de quelques stations au sol et d’une couverture satellitaire similaire. En termes simples, l’étude montre que nous pouvons désormais « voir » la chaleur urbaine avec beaucoup plus de finesse, fournissant une base essentielle pour une adaptation climatique plus juste et plus ciblée et pour la protection des communautés vulnérables.
Citation: Roca-Barceló, A., Schneider, R., Pirani, M. et al. A satellite based machine learning approach for estimating high resolution daily average air temperature in a megacity in Brazil. Sci Rep 16, 7459 (2026). https://doi.org/10.1038/s41598-026-35689-x
Mots-clés: chaleur urbaine, apprentissage automatique, données satellitaires, São Paulo, température de l’air